[DL Basic] Sequential Models - Transformer
AttentionEncoder/Decoder/GeneratorMaskingUstageattention is all you needpositional encodingtransformer네이버커넥트_부스트캠프 AI Tech 3기
부스트캠프 AI Tech 3기 👩💻
목록 보기
8/10
시퀀셜 모델링을 어렵게 하는 문제들
Sequence는 뒤에가 잘리는 경우, 중간에 생략되는 경우, 어순이 바뀌는 경우 등이 존재
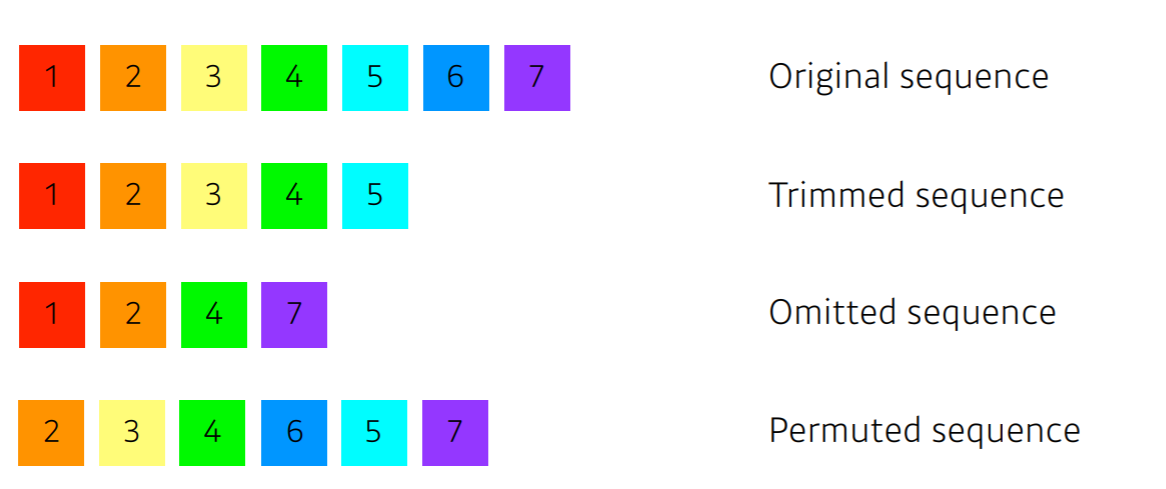
- 따라서 재귀적으로(recurrersive) 동작하는 RNN 계열의 경우에는, 이런 문제들을 반영해 학습하기가 어려웠음.
Transformer
- 기계번역 외에도 이미지 분류, 문장 조합에서 이미지를 생성하는 모델(
DALL·E- 참고: https://openai.com/blog/dall-e/) - (1)시퀀셜한 데이터를 처리하고 인코딩하는 구조 & (2)멀티 어텐션 헤드 개념은 다른 Task에서도 많이 사용되고 있음
- RNN 계열과 다른 특징
- [1] 입력 시퀀스와 출력 시퀀스의
크기(단어의 수)가 다를 수 있음. - [2] 입력 시퀀스와 출력 시퀀스는 데이터의
Domain도 다를 수 있다. (예: 기계번역 Task에서 입력은 한국어, 출력은 영어) - (하지만 모델은 1개)
인코딩시, RNN 처럼 단어의 수만큼 재귀적으로 돌지 않고, 한 번에 해당 단어의 수만큼 시퀀스가 딱 생성된다.Encoder/Attention구조에서는n(해당 단어의 수, 가변적인 단어 수..!!)만큼 한 번에 처리된다.- (➕ cf.
Generator(생성자)단계에서는,1개단어씩 생성한다..! 따라서, 이때는Auto-Regressive)
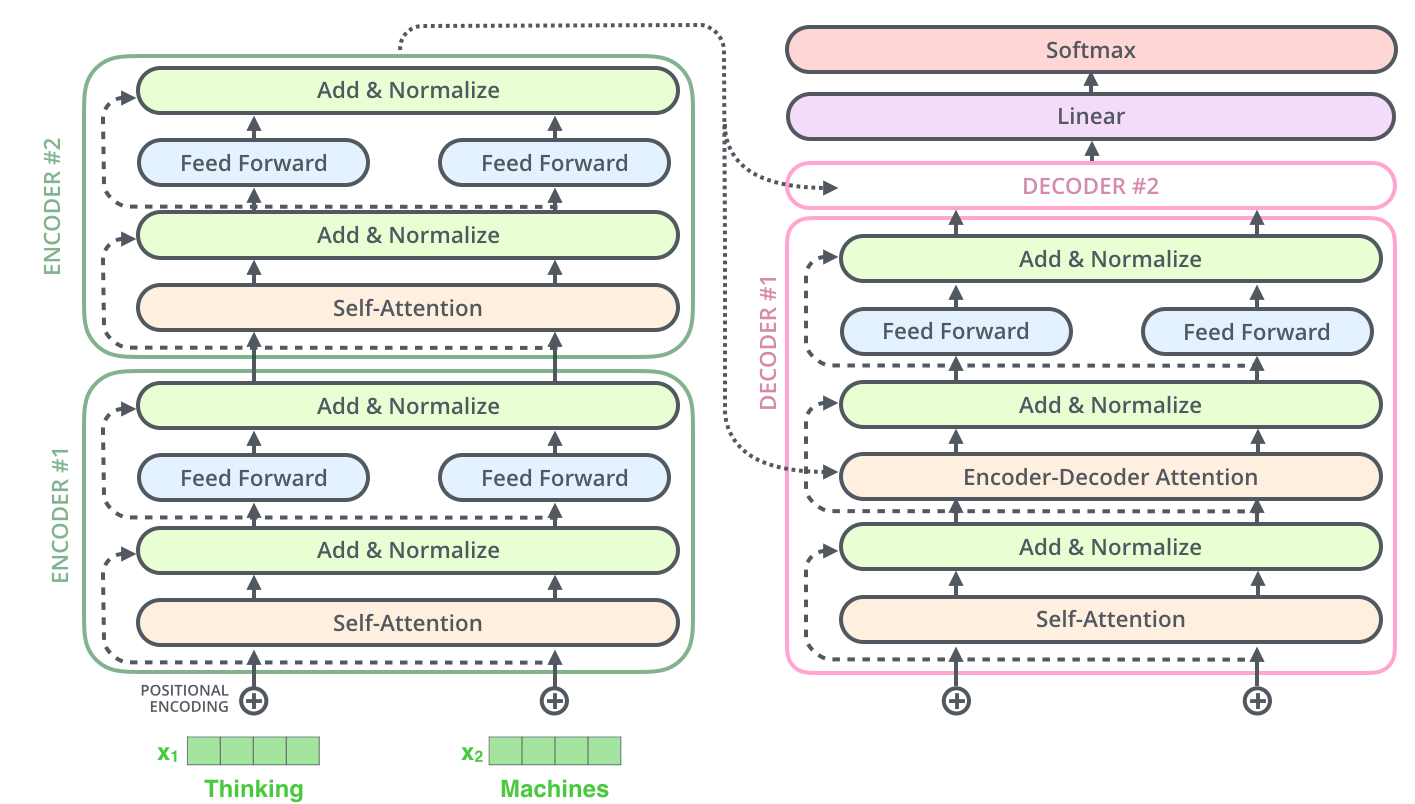
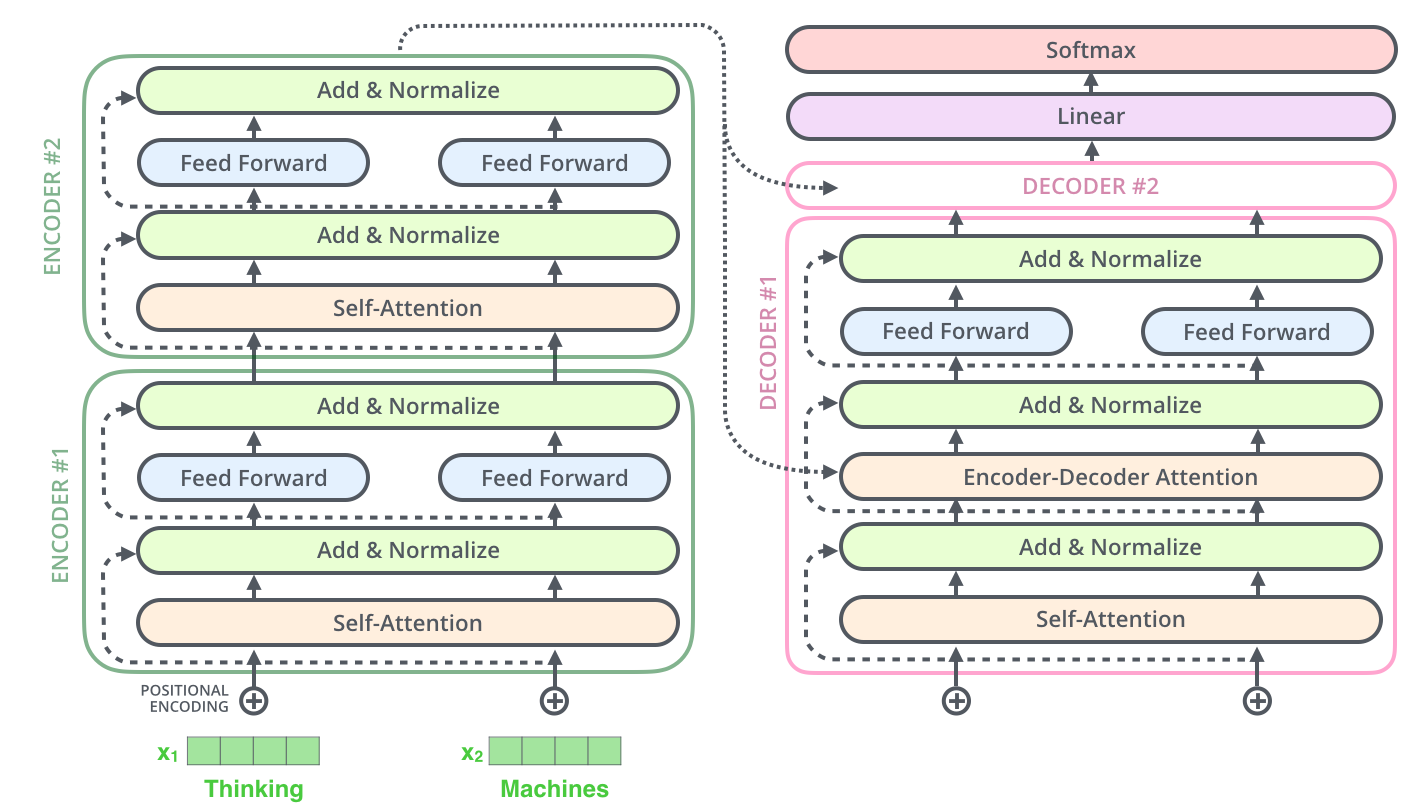
- Transformer의 구조
-
동일한 내부 구조를 갖지만
parameters가 다르게 학습되는Encoder와Decoder가 여러 개 stack되어 있는 구조. -
Self-Attention이 핵심 (Transformer에서인코딩단계에 해당됨) -
입력으로 주어진 n개의 단어가 들어갈 때, x_i에서 z_i으로 n개의 벡터(=
Feature Vectors)를 변환하는 구조. -
이때 해당
1개단어 외, 나머지(n-1)개의 단어의 정보를 함께 활용한다..!!!
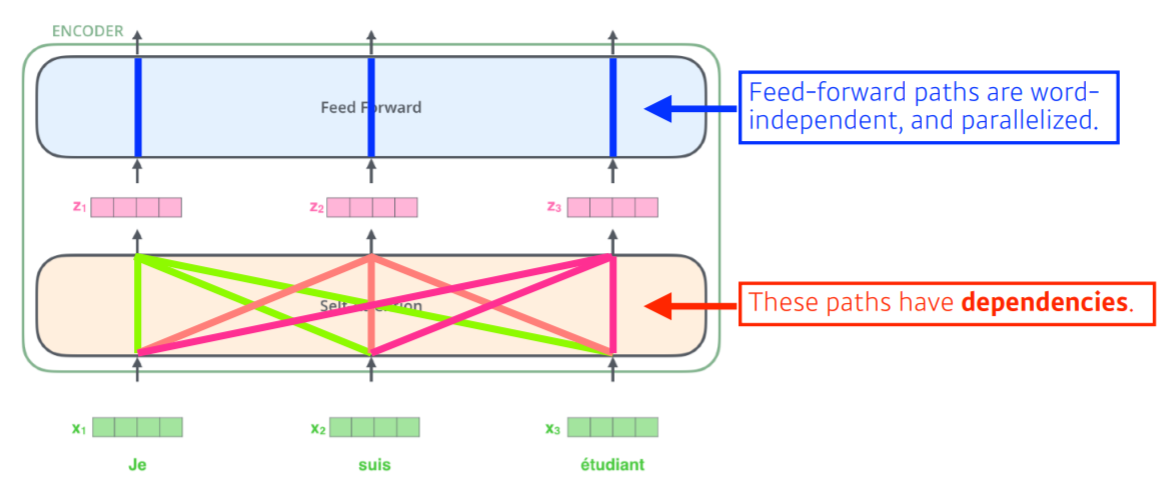
- ➕ Self-Attention VS. Feed Forward
- word-dependent // word-independent
- (dependency 가짐 O) // (dependency 가지지 X)
- paralleized X // parallelized O
## Self-Attention - `Self-Attention은` 3개의 `벡터`(= 즉, 3개의 `뉴럴 네트워크`)를 가짐 - : `Query 벡터`, `Key 벡터`, `Value 벡터`
쿼리를 날리는과정- 현재 내가 구하고자 하는
i번째 단어 1개에 해당하는Query 벡터와 나머지(n-1)개에 해당하는Key 벡터및Value 벡터의내적 값을 구하여 =>Score값(유사도, 상호관계성 관련 지표 / type:스칼라값)을 구함. - 즉, 특정 time-step에서 나머지 단어들 중 어떠한 단어가 자신과 corresponding 한지를 찾는
자기할당(self-aligned)과정
- 이때,
Score값을 계산할 때는,정규화(Normalization)개념으로 전체 벡터의 차원(=Query 벡터의 차원 =Key 벡터의 차원)의 루트 값으로 나누어줌. (분모 값) - 이후,
softmax()함수를 취해줌. - 이후,
Value 벡터와의weighted sum(가중치 합)이 최종 인코딩 벡터의 결과..!!
- 인코딩 단계의 최종 결과값 :
n차원의 인코딩된 벡터..!
➕ Query/Key/Value 벡터의 Dimension
Query 벡터의 차원 =Key 벡터의 차원..!- 하지만,
Value 벡터의 차원은 이 둘과 다를 수 있다..! - 🙋 그 이유는 ??
MLP(다층 퍼셉트론 구조)나CNN에서는 인풋이 고정되어 있으면, 출력도 고정되어 있다. (연산에 쓰이는 필터/가중치 등 파라미터가 고정되어 있기 때문에)- 하지만
Transformer에서는 인풋/네트워크 구조가 고정되어 있더라도, 현재 인코딩하는 단어와 근처에 주어진 다른 단어들과의 관계성에 따라 출력이 달라질 수 있다..! - 따라서,
표현성이 높은flexible한 모델 ➕ 하지만, 그만큼연산량이 증가한 모델 - 이러한 문장의 길이가 길어짐에 따라 증가하는 연산량은
Transformer의 한계가 됨.
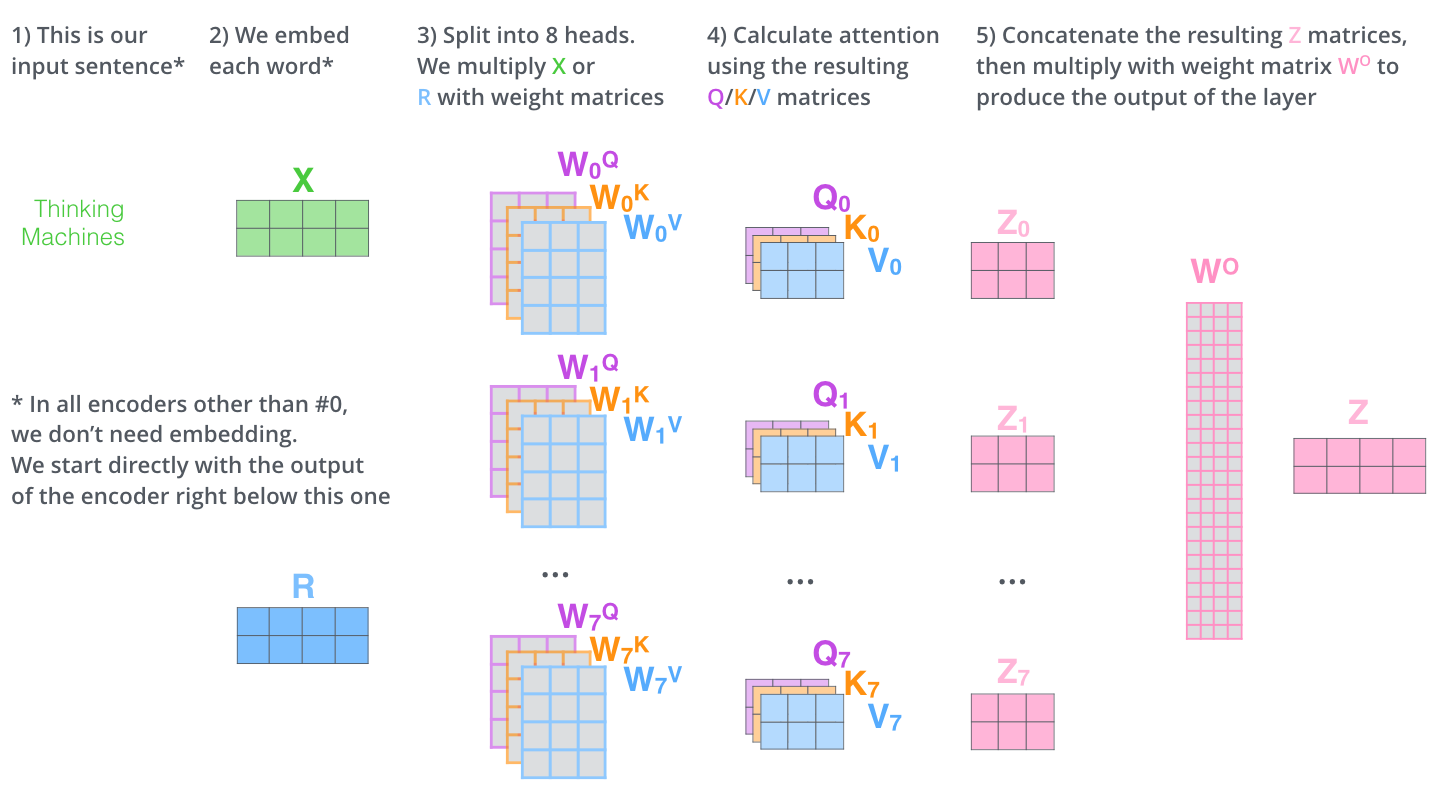
Muti-Head-Attention
- 하나의 임베딩된 벡터에 대해서 Query/Key/Value를
여러 개(m개)만드는 접근법. - 총 m개의 인코딩된 벡터 세트가 아웃풋 결과물
- (이 과정에서 차원을 맞춰주기 위해
linear map을 활용해 차원을 축소시켜줌) - (➕ 이 부분은 구현 시 논문과 살짝 다름..?)
➕ Positional Encodings
Self-Attention만 가지고는 순서 정보를 알 수 없음. (order-independent)- 따라서, 주어진 원래 임베딩 벡터 값에 위치를 나타내는 값을 더해줌.
- ➕ 방법론: [1] Attention is all you need 논문의 방식, , [2] 최근 논문(2020년 7월)의 방식
➕ Masking 기법 (Caution Masking)
- 이전 단어들에 대해서만
dependent하고 이후 단어들에 대해서는independent하지 않게 만드는 방법론 - 이를 통해, 학습 시 해당 단어의 뒤에 있는 정보(미래에 있는 정보)를 활용하지 않도록 방지하는 효과 (정답을 이미 알고 있는 학습 단계에서는 뒤를 참고하게 된다면 제대로된 학습이 이뤄지지 않게 되기 때문에)
- Masking은
train뿐만 아니라inference에서도 사용됨
Decoder + Generator 단계
입력 시퀀스(문장)uto-regressive방식으로 생성된다.Encoder-Decoder Attentionlayer : 생성 시, 내가 이전까지만 generate된 데이터만 가지고 Query를 만들고, Key+Value 벡터는 원래 raw인풋 시퀀스(문장)서 나오는 임베딩 벡터를 활용한다..!
참고 자료
- PyTorch 공식
nn.Transformer문서 : - The Illustrated Transformer :
- 번역 글 :
- 허민석님 발표 영상 :
- PyTorch
nn.Transformer모듈 공식 문서 : positional encoding에 대한 고찰 :

AI, Big Data, Industrial Engineering