Numpy Broadcasting, Pytorch Broadcasting
Broadcasting
Broadcasting이라는 용어는 산술 연산 중에 NumPy가 배열을 다양한 모양으로 처리하는 방법을 설명합니다. 특정 제약 조건에 따라 더 작은 Array는 더 큰 Array에 "Broadcast"되어 호환 가능한 모양을 갖습니다. Broadcasting은 Python 대신 C에서 루프가 발생하도록 배열 작업을 벡터화하는 수단을 제공합니다. 이는 불필요한 데이터 복사본을 만들지 않고 이를 수행하며 일반적으로 효율적인 알고리즘 구현으로 이어집니다. 그러나 Broadcasting은 메모리를 비효율적으로 사용하여 계산 속도를 늦추기 때문에 좋지 않은 생각인 경우도 있습니다.
NumPy 작업은 일반적으로 요소별로 배열 쌍에서 수행됩니다. 가장 간단한 경우에는 다음 예와 같이 두 배열의 모양이 정확히 동일해야 합니다.
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = np.array([2.0, 2.0, 2.0])
>>> a * b
array([2., 4., 6.])NumPy의 broadcasting 규칙은 배열의 모양이 특정 제약 조건을 충족할 때 이 제약 조건을 완화합니다. 가장 간단한 broadcasting 예는 배열과 스칼라 값이 연산에 결합될 때 발생합니다.
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = 2.0
>>> a * b
array([2., 4., 6.])결과는 b가 배열이었던 이전 예제와 동일합니다. 우리는 산술 연산 중에 스칼라 b가 a와 같은 모양의 배열로 늘어난다고 생각할 수 있습니다. 그림 1에 표시된 것처럼 b의 새로운 요소는 원래 스칼라의 복사본일 뿐입니다. 스트레칭 비유는 개념적인 것일 뿐입니다. NumPy는 복사본을 실제로 만들지 않고도 원본 스칼라 값을 사용할 수 있을 만큼 똑똑하기 때문에 broadcasting 연산이 가능한 한 메모리와 계산 효율이 높습니다.
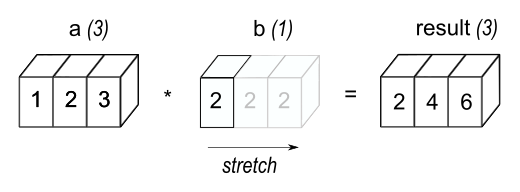
가장 간단한 broadcasting 예시에서는 스칼라 B가 A와 같은 모양의 배열이 되도록 늘려서 요소별 곱셈에 호환되는 모양을 만들었습니다.
두 번째 예제의 코드가 첫 번째 예제보다 더 효율적인 이유는 곱셈하는 동안 메모리를 덜 이동시키기 때문입니다(b는 배열이 아닌 스칼라입니다).
General Broadcasting Rules
두 배열에서 연산할 때 NumPy는 두 배열의 모양을 요소별로 비교합니다. 가장 뒤쪽(즉, 가장 오른쪽) 차원부터 시작하여 왼쪽으로 작업합니다. 두 차원은 다음과 같은 경우에 호환됩니다.
- 두 차원이 같은 경우
- 둘 중 하나가 1인 경우
이러한 조건이 충족되지 않으면 배열의 모양이 호환되지 않음을 나타내는 "ValueError: operands could not be broadcast together" 예외가 발생합니다.
입력 배열의 차원 개수가 같을 필요는 없습니다. 결과값은 차원 수가 가장 많은 입력 배열과 동일한 수의 차원을 가지며, 여기서 각 차원의 크기는 입력 배열 중 해당 차원의 가장 큰 크기입니다. 누락된 차원은 크기가 1인 것으로 가정합니다.
예를 들어 RGB 값의 256x256x3 배열이 있고 이미지의 각 색상의 크기를 다른 값으로 조정하려는 경우 이미지에 3개의 값을 가진 1차원 배열을 곱하면 됩니다. broadcast 규칙에 따라 이러한 배열의 후행 축의 크기를 정렬하면 해당 배열이 호환되는지 확인할 수 있습니다:
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3비교하는 두 차수 중 하나가 1이면 다른 차수가 사용됩니다. 즉, 크기가 1인 차수는 다른 치수와 일치하도록 늘어나거나 "복사"됩니다.
다음 예제에서는 A와 B 배열 모두 길이가 1인 축이 broadcast 작업 중에 더 큰 크기로 확장됩니다:
A (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5Broadcastable arrays
위의 규칙이 유효한 결과를 생성하는 배열 집합을 동일한 모양으로 "broadcastable" 배열이라고 합니다.
예를 들어 a.shape가 (5,1), b.shape가 (1,6), c.shape가 (6,), d.shape가 ()인 경우 d는 스칼라이므로 a, b, c, d는 모두 차원 (5,6)으로 broadcast할 수 있습니다.
a는 a[:,0]이 다른 열로 broadcast되는 (5,6) 배열처럼 작동합니다,
b는 b[0,:]가 다른 행으로 broadcast되는 (5,6) 배열처럼 작동합니다,
c는 (1,6) 배열처럼 작동하므로 c[:]가 모든 행에 broadcast되는 (5,6) 배열처럼 작동합니다,
d는 단일 값이 반복되는 (5,6) 배열처럼 작동합니다.
다음은 몇 가지 예시입니다:
A (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
A (2d array): 5 x 4
B (1d array): 4
Result (2d array): 5 x 4
A (3d array): 15 x 3 x 5
B (3d array): 15 x 1 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 1
Result (3d array): 15 x 3 x 5다음은 broadcast되지 않는 shape의 예입니다:
A (1d array): 3
B (1d array): 4 # 마지막 차원이 일치하지 않음
A (2d array): 2 x 1
B (3d array): 8 x 4 x 3 # 마지막에서 두번째 차원이 일치하지 않음1차원 배열이 2차원 배열에 추가될 때 broadcast의 예:
>>> a = np.array([[ 0.0, 0.0, 0.0],
... [10.0, 10.0, 10.0],
... [20.0, 20.0, 20.0],
... [30.0, 30.0, 30.0]])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a + b
array([[ 1., 2., 3.],
[11., 12., 13.],
[21., 22., 23.],
[31., 32., 33.]])
>>> b = np.array([1.0, 2.0, 3.0, 4.0])
>>> a + b
Traceback (most recent call last): ValueError: operands could not be broadcast together with shapes (4,3) (4,)그림 2와 같이 a의 각 행에 b가 추가됩니다. 그림 3에서는 호환되지 않는 shape으로 인해 예외가 발생합니다.
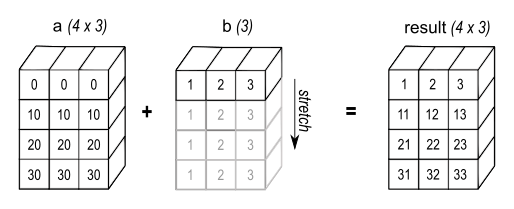
2차원 배열에 1차원 배열을 추가할 때, 1차원 배열 차수와 2차원 배열 차수가 일치하는 경우 broadcasting이 발생합니다.
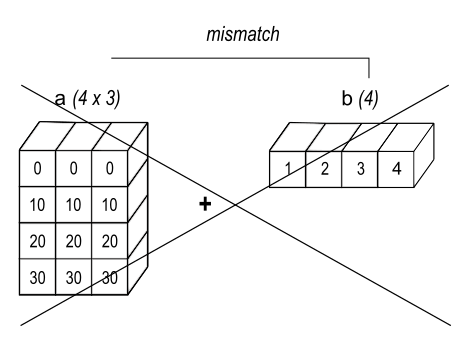
배열의 후행 차원이 같지 않으면, 요소 추가를 위해 첫 번째 배열의 값을 두 번째 배열의 요소와 정렬할 수 없기 때문에 broadcasting이 실패합니다.
Broadcasting은 두 배열의 외적(또는 다른 outer operation)을 계산하는 편리한 방법을 제공합니다. 다음 예에서는 두 개의 1차원 배열에 대한 outer addition 연산을 보여줍니다.
>>> a = np.array([0.0, 10.0, 20.0, 30.0])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a[:, np.newaxis] + b
array([[ 1., 2., 3.],
[11., 12., 13.],
[21., 22., 23.],
[31., 32., 33.]])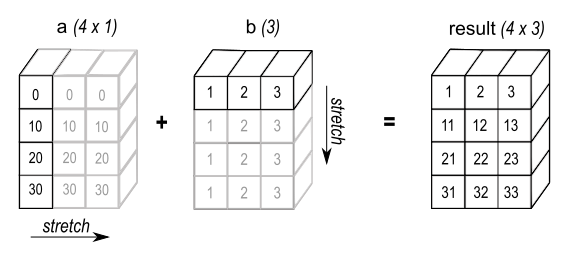 경우에 따라, broadcasting은 두 배열을 모두 확장하여 초기 배열보다 큰 출력 배열을 형성합니다.여기서 np.newaxis 인덱스 연산자는 a에 새 축을 삽입하여 2차원 4x1 배열을 만듭니다. 4x1 배열을 (3,) shape을 가진 b와 결합하면 4x3 배열이 됩니다.
경우에 따라, broadcasting은 두 배열을 모두 확장하여 초기 배열보다 큰 출력 배열을 형성합니다.여기서 np.newaxis 인덱스 연산자는 a에 새 축을 삽입하여 2차원 4x1 배열을 만듭니다. 4x1 배열을 (3,) shape을 가진 b와 결합하면 4x3 배열이 됩니다.
PyTorch Broadcasting semantics
Pytorch operation은 NumPy의 Broadcasting semantics을 지원합니다. 자세한 내용은 https://numpy.org/doc/stable/user/basics.broadcasting.html 을 참조하세요. 간단히 말해, PyTorch operation이 Broadcast를 지원하면 데이터를 복사하지 않고도 텐서 인자를 동일한 크기로 자동 확장할 수 있습니다.
General semantics
다음 규칙이 충족되면 두 개의 텐서는 "broadcastable"합니다:
- 각 텐서에는 적어도 하나의 차원이 있습니다.
- 후행 차원부터 차원 크기를 비교할 때, 차원 크기가 같거나, 차원 크기 중 하나가 1이거나, 차원 크기 중 하나가 존재하지 않아야 합니다.
예를 들어:
# 동일한 모양은 항상 broadcastable. (i.e. 이 규칙은 항상 적용됨)
>>> x = torch.empty(5, 7, 3)
>>> y = torch.empty(5, 7, 3)
# x와 y는 not broadcastable. x는 차원이 적어도 하나 이상 있어야 하기 때문.
>>> x = torch.empty((0,))
>>> y = torch.empty(2, 2)
# x와 y는 broadcastable
# 1st trailing dimension: 모두 크기가 1.
# 2nd trailing dimension: y 크기가 1.
# 3rd trailing dimension: x size == y size
# 4th trailing dimension: y 차원이 없음.
>>> x = torch.empty(5, 3, 4, 1)
>>> y = torch.empty( 3, 1, 1)
# x와 y는 not broadcastable. 3rd trailing dimension: 2 != 3
>>> x = torch.empty(5, 2, 4, 1)
>>> y = torch.empty( 3, 1, 1)두 개의 텐서 x, y가 "broadcastable"인 경우 결과 텐서 크기는 다음과 같이 계산됩니다:
- x와 y의 차원 수가 같지 않으면 차원 수가 적은 텐서의 차원에 1을 더하여 길이가 같아지도록 합니다.
- 그 다음, 새로운 텐서의 크기는 x와 y 크기의 최대값이 됩니다.
예를 들어:
>>> x=torch.empty(5, 1, 4, 1)
>>> y=torch.empty( 3, 1, 1)
>>> (x+y).size()
torch.Size([5, 3, 4, 1])
# but not necessary:
>>> x=torch.empty(1)
>>> y=torch.empty(3,1,7)
>>> (x+y).size()
torch.Size([3, 1, 7])
>>> x=torch.empty(5, 2, 4, 1)
>>> y=torch.empty( 3, 1, 1)
>>> (x+y).size()
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 1In-place semantics
한 가지 복잡한 점은 in-place operation이 broadcast 결과로 내부 텐서의 모양을 변경하는 것을 허용하지 않는다는 것입니다.
예를 들어:
>>> x=torch.empty(5, 3, 4, 1)
>>> y=torch.empty( 3, 1, 1)
>>> (x.add_(y)).size()
torch.Size([5, 3, 4, 1])
# 그러나:
>>> x=torch.empty(1, 3, 1)
>>> y=torch.empty(3, 1, 7)
>>> (x.add(y)).size() # not in-placement.
torch.Size([3, 3, 7])
>>> (x.add_(y)).size() # in-placement.
RuntimeError: The expanded size of the tensor (1) must match the existing size (7) at non-singleton dimension 2.