하이욤
오늘은 어제 마무리 했던 과제를 리뷰해보려 한다
어제 한 내용은 솔직히 말하면 함수 다른거 빼고는 다른 데서도 정리 한번 했었는데, 다시 하려니까 기억이 안나서 전에 했었던 코드 다시 보고 다시 쳐보는 걸 반복했었다. 요번에도 정리해서 조금 더 기억력을 올려보려 함
Task 1
task1은 sklearn 데이터셋의 유방암 데이터 가지고 가긱 다른 kernel들 가지고 노는 과제.
일단 필요한 모듈과 클래스들은
from sklearn.svm import SVC #support vector classification
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import matplotlib.pylab as plt요종도가 되겠다.
그 중 SVC함수의 kernel메서드 중 'linear', 'poly', 'rbf 를 그래프로 시각화 해야함

가장 먼저 할 일은, 데이터를 로드하고 학습용과 테스트 용으로 나눠주는 것. 물론 다 하면 좋겠지만, feature_names를 꺼내보면 이렇게 피쳐들이 많다. 갯수만큼 차원수가 늘어나는데, 다 한번에 시각화 불가능! 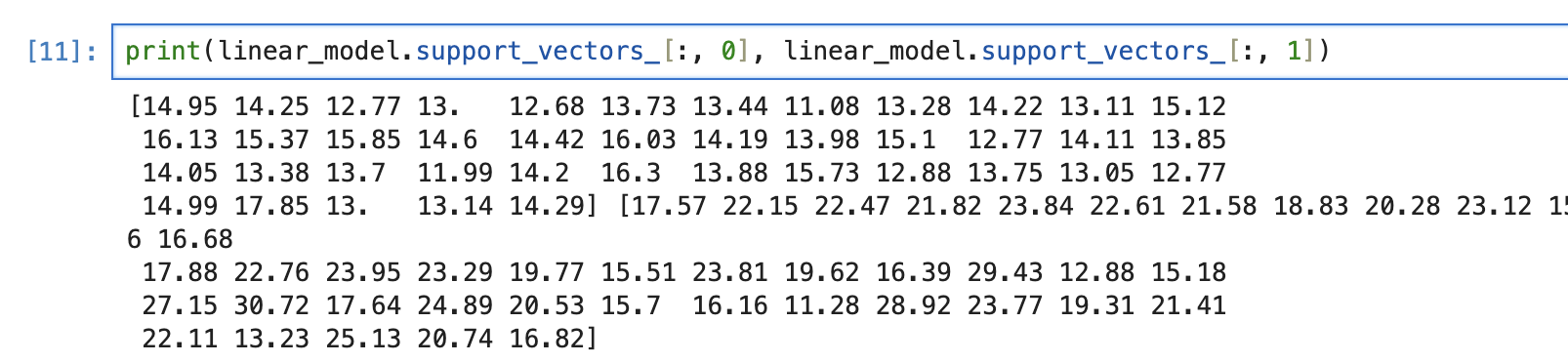
그렇기에, data 중에서 처음 과 두번째 열만 가지고 온다
X = breast_cancer.data[:, :2]요거 중요하다잉~
그리고 그 다음으로 이제 학습을 시작한다. 기억해야 할 것은, scatter x축이랑 y축 값 넣어줄 때, X.data의 위치를 정해주어야 한다는 것.
추가로 학습된 모델을 supportvectors가 붙으면 support vector 위치를 알 수 있는데, 이거 거 가지고 저 검은색 동그란 원을 그려주어야 함.
저 동그란 원 생기게 하는거는 facecolors = 'none'해주면 투명하게 된다. 아래가 사진
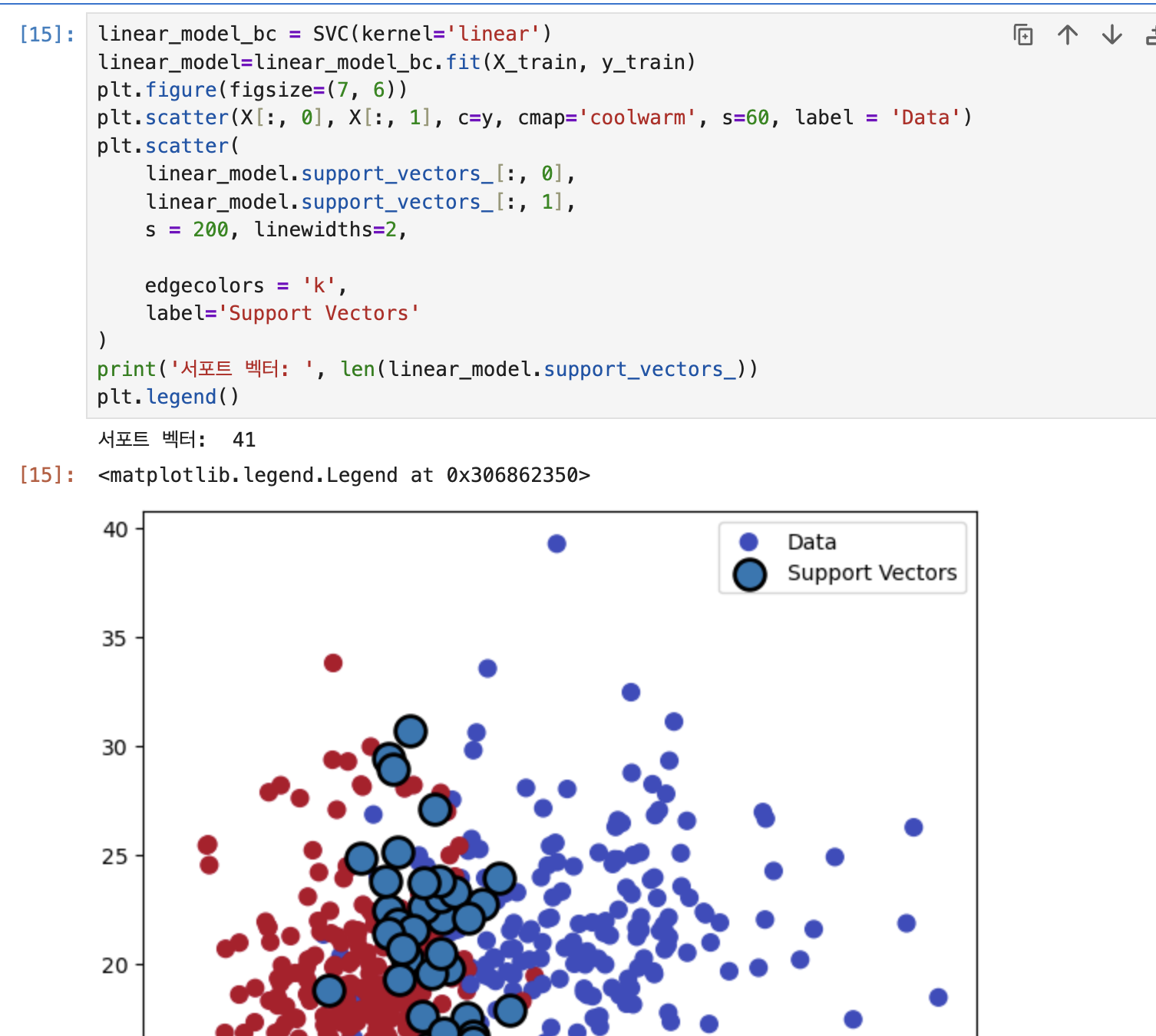
linear_model_bc = SVC(kernel='linear')
linear_model=linear_model_bc.fit(X_train, y_train)
plt.figure(figsize=(7, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', s=60, label = 'Data')
plt.scatter(
linear_model.support_vectors_[:, 0],
linear_model.support_vectors_[:, 1],
s = 200, linewidths=2,
facecolors = 'none', edgecolors = 'k',
label='Support Vectors'
)
print('서포트 벡터: ', len(linear_model.support_vectors_))
plt.legend()이제 나머지는 kernel만 'linear'에서 'poly'랑 'rbf'로 변경해서 데이터 다시 그려주면 됨!
task 2
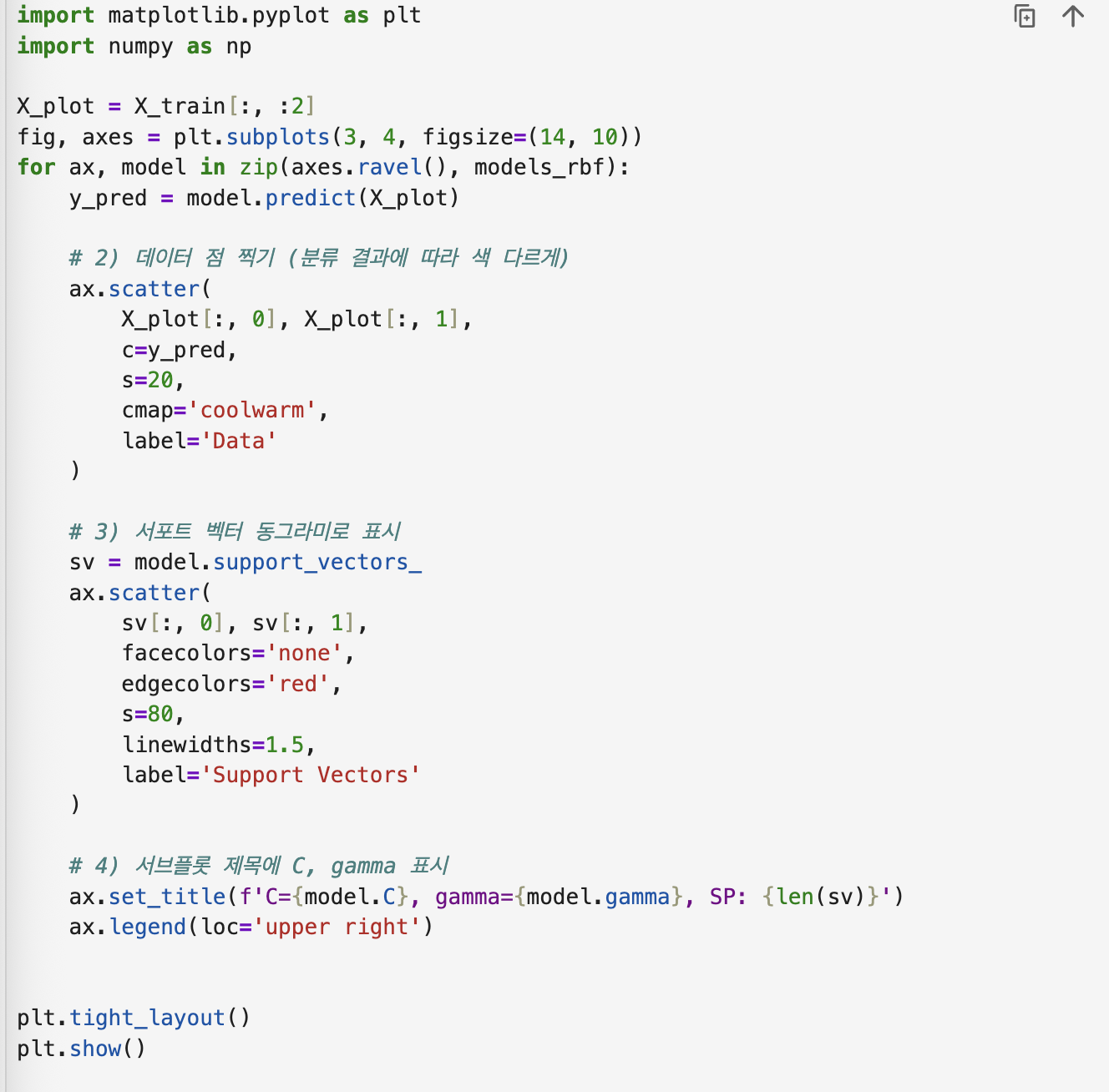
과제 2는 rbf커널 기준으로 C와 gamma 값을 조정해서 모델 변화를 관찰하는 과제
rbf - Radial Basis Function 으로 비선형 데이터를 분류하는데 큰 강점이 있음, 중심에서 멀어질수록 영향이 줄어드는 '종 모양' 함수 형태라고 알고있자. 즉 직선으로 못 나누는 데이터를 곡선으로 깔끔하게 분리해주는 강력한 커널
gamma - gamma값은 RBF 커널에서만 쓰이는 중요한 하이퍼 파라미터로 데이터 한 점이 주는 영향의 범위이다. gamma 값이 커지면 모델이 데이터에 너무 예민하게 반응해서 과적합이 되고, 너무 작으면 영향 반경이 넓어져서 모델이 너무 단순해진다. 과소적합 위험있음
C값은 margin 범위인데, 커질수록 margin 영향이 커진다고 보면 됨
일단 시작하기 전에 비교할게 여러개니 리스트로 만들어 놓자
c = [0.1, 1.0, 10.000]
gamma = [0.001, 0.01, 0.1, 1]
models_rbf = []
scores_rbf = []요거 models_rbf = []같이 빈 리스트 만들어서 append한 다음 한번에 처리하는거는 태현님 코드 보면서 배움. (감사합니다)
이제 C랑 gamma 리스트를 모두 돌려야 하는데, 아래처럼 for문을 두번 겹쳐서 쓰게되면 해결된다.
모델 학습도, append하는것도 모두 여기 for문 안에서 실행한다.
for i in c:
for g in gamma:
model = SVC(
kernel = 'rbf',
C = i,
gamma=g
)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
models_rbf.append(model)
scores_rbf.append(score)fig, axes?
fig는 전체 도화지(캔버스)
axes는 그 도화지 위에 있는 작은 그래프들. axes[0,0]하면 첫 번째 줄, 첫 번째 그래프
그리고 위에서 학습한 모델 가지고 for문을 돌려 그래프를 그린다.
X_plot = X_train[:, :2]
for ax, model in zip(axes.ravel(), models_rbf):요 코드는 그래프를 여러개 그릴 때 포문으로 한번에 쭉 깔아버리는 것임
axes.ravel() 요거는 axes들 (각각 그래프들) 을 한줄 리스트로 쭉 펼친 다음에, models.rbf 값들을 이어붙여서 그래프를 그리겠다고 선언하겠다는 뜻
y_pred 를 해주는 이유는 나중에 색깔 칠해주기 위해서
scatter 할 때 c(색깔) 매서드로 들어감
s = 20 은 점 크기
cmap은 color map. bwr은 white+red를 포함한 컬러맵이라는 뜻. brw 이외게 viridis, coolwarm, plasma, gray 등이 있음
y_pred = model.predict(X_plot)
ax.scatter(
X_plot[:, 0], X_plot[:, 1],
c=y_pred,
s=20,
cmap='bwr',
label='Data'요거는 support vector 표시해주는 건데, sv = model.supportvectors하면 값들이 도출되는데, 이때 위에서 해준대로 x 축, y 축에다 값으로 support vectors 값 넣어주고 facecolors = 'none'하면 구멍이 뻥 뚫린다.
sv = model.support_vectors_
ax.scatter(
sv[:, 0], sv[:, 1],
facecolors='none',
edgecolors='k',
s=80,
linewidths=1.5,
label='Support Vectors'나머지는 알아서!