이번 글에서 정리할 내용은
1. Decision Tree의 한계와 앙상블
2. Bagging
3. Random Forest(tree 말고 숲!) (다음글)
Decision tree 한계와 앙상블
지난번에 Decision tree 실습 했었는데, 그때 했었던 시각화 결과를 가져왔다.
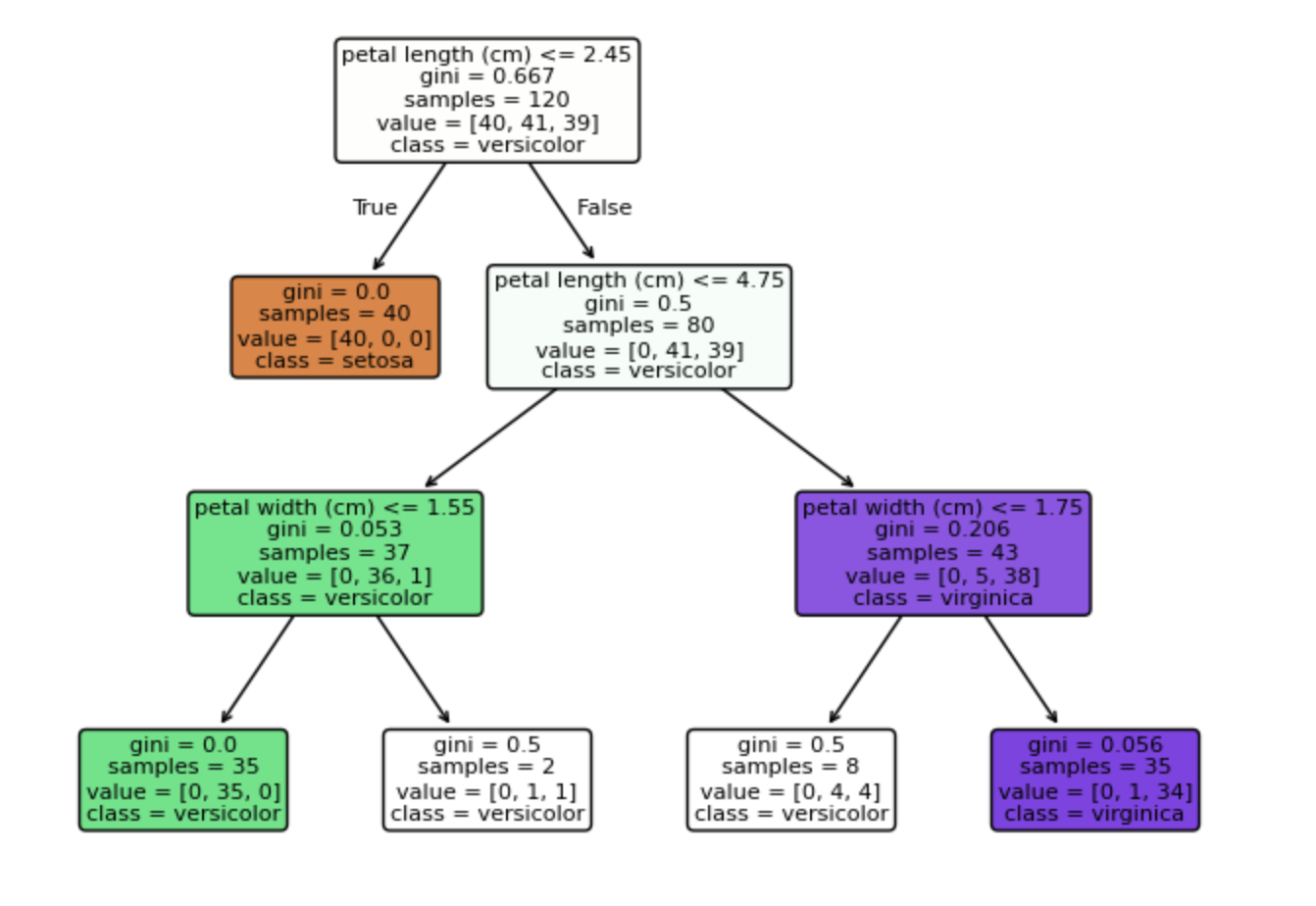
간략하게 코드 짜는거를 다시 상기시키면,
메서드로 docstring 넣어주면 되고, 마지막에 plot_tree 할때 DecisionTreeClassifier 함수 썼던 데이터들을 넣어주면 됨.
from sklearn.tree import DecisionTreeClassifier, plot_tree
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
tree = DecisionTreeClassifier(max_depth=3, min_samples_split=5, min_samples_leaf=2, random_state=42)
plt.figure(figsize=(8, 6))
plot_tree(
tree,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled = True, #어떤 색상을 채울거냐! 자동으로 만들어 주는 듯
rounded = True #둥굴게 만들고싶노?!
)(장점)
1. if-then 규칙으로 의사결정 과정 명확히 이해
설명하자면 2분법으로 나눈다는 뜻
2. 복잡한 비선형 관계 해결가능.
3. 스케일링, 정규화 필요 ㄴㄴ
4. 학습 후 에측 빠름
but (단점)
1. 훈련 데이터의 노이즈까지 완벽하게 학습..
2. 데이터의 작은 변화에도 전혀 다른 트리 형성..
3. 복잡한 패턴을 하나의 트리로 완벽히 포착하기 어렵 ㅠ
최종 결론을 내리자면, 강력하지만 불안정한 알고리즘
Bagging
이를 보완하기 위한 해결책 'Bagging'
Bagging = Bootstrap + Aggregating
그럼 각각 뜯어보자
랜덤 포레스트나 배깅 같은 방법은 하나의 큰 모델이 아니라, 여러 개의 작은 모델(트리)를 만들어
만약 트리 10개가 만들어진다고 하면, 각각이 가지고 있는 의견이 있지. 이때 이 10개가 말하는 것을 모아서 하나의 답을 도출하는게 aggregating이야
bootstrap은 각각 길이는 똑같지만, 중복된 데이터도 포함되고 어떤 데이터도 아예뽑히지 않은 서로 다른 모델들이 무수히 많지. 이게 10개 있다고 하면 위에 aggregating 설명할 때 썼던 거랑 이어져.
각각의 트리들이 만들어지는데, 한 상자 번호가 붙여져 있는 공을 뽑는다고 하자. 안에서 번호를 뽑고 확인한다음 다시 넣어. 이때 이를 수십번 수백번 수천버 중복 하면 각각의 번호가 나올 확률이 달라지겠지? (랜덤으로 뽑으니깐) 근데 이 확률은 시도한 횟수가 많아지면 많아질수록 어느 한 확률에 수렴하게 되는데 이를 bootstrap이라고 하지. bagging 기법은 이 두 과정을 합친거라고 보면 돼!
이때 bootstrap 학습하면서 아무리 돌렸다 해도 어떤 랜덤으로 넣고 빼고를 반복하니 학습에 포함되지 않은 데이터들이 있을 거 아니야, 이 안뽑힌 데이터들OOB (Out of bag)들로 테스트하게 됨.
10개의 사진을 만들었지만, 어떤 사진은 친구 A에게 보여주지 않았을 수 있음
친구 A가 보지 않은 사진으로 테스트 ㄱㄱ 근데 이 안본 사진 비율이 약 36.8%라는 뜻!

이거 1000개정도 돌려봤는데, 34%정도 나온다. 더 돌리면 올라갈듯

코드 보자
1. bootstrap_demo라는 함수에다가 data랑 n_bootstraps 라는 변수를 넣어주었다.
2. n 은 변수로 넣어준 data의 길이. 원본 데이터로 1부터 10까지의 데이터를 넣었으니, 그것의 길이를 측정해서 랜덤으로 뽑을것임
3. for문을 써서 n_bootstraps 만큼 트리를 만들어낸다
4. random.choice는 (n개의 데이터를, 사이즈 n만큼 replace = True (중복 허용)해서 숫자를 고르겠다는 뜻)
5.data[indices] 는 숫자 데이터는, 영어데이터든 문자 데이터든 indices는 리스트형태로 각각의 데이터 위치들을 알려주는 거고, 이 리스트에 맞춰서 data의 값들이 도출된다.
6. np.unique()는 배열 안에 있는 값들 중에서 중복을 제거하고, 고유한 값들만 모아서 정렬해서 보여준다는 뜻. 상자 안에 어떤 번호가 들어있는지 각각의 트리에서 뽑힌 것들을 (중복 제거하고)나열
7. missing_indices는 전체 데이터들에서 안나온 것들 나열
8. 그 아래는 내가 OOB비율 구하려고 해놓은 코드
요 아래 데이터는 원래
와인 데이터로 되어있는데, 모델 수를 아무리 늘려도 값이 똑같아서, breastcancer 데이터로 변경해서 모델수 늘려서 다시 계산해봄
처음 모델은 그냥 위에서 Decision tree 한것처럼 간단하게 묘사한거고, 아래는 Bagging 모델을 만들어서 Decision tree로 묘사한거다.
처음보든 코드긴 함
코드 설명을 보면

요렇게 되어있음. 위에 코드랑 차이를 보면 Decisiontreeclassifier에다가 하이퍼파라미터로 random_state = 42만 넣어줬는데, 아래는 sklearn.ensemble 모듈의 baggingclassifier 클래스를 가져와서 그 안에 메서드 인자값들을 많이 넣어준거다.
estimator로 똑같이 Decisiontreeclassifier을 넣어주고
n_estimators에다가 모델 몇개만들지 말해줌.
아 이것도 각각 fit으로 학습 시켜주어야 한다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine, load_breast_cancer
# 1. 데이터 준비
wine = load_wine()
breast_cancer = load_breast_cancer()
X, y = breast_cancer.data[:, :2], breast_cancer.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 2. 단일 Decision Tree
single_tree = DecisionTreeClassifier(random_state=42)
single_tree.fit(X_train, y_train)
single_score = single_tree.score(X_test, y_test)
# 3. Bagging with Decision Trees
bagging = BaggingClassifier(
estimator=DecisionTreeClassifier(), # 기본 모델
n_estimators=10000, # 모델 개수
max_samples=1.0, # 각 샘플의 크기 (1.0 = 100%)
max_features=1.0, # 각 모델이 사용할 특성 비율
bootstrap=True, # Bootstrap 샘플링 사용
bootstrap_features=False, # 특성은 Bootstrap 안함
oob_score=True, # OOB score 계산
random_state=42
)
bagging.fit(X_train, y_train)
bagging_score = bagging.score(X_test, y_test)
# 4. 결과 비교
print("="*50)
print("Wine 데이터셋 분류 결과")
print("="*50)
print(f"단일 Decision Tree:")
print(f" 테스트 정확도: {single_score:.3f}")
print(f"\nBagging (100 trees):")
print(f" 테스트 정확도: {bagging_score:.3f}")
print(f" OOB 점수: {bagging.oob_score_:.3f}")
print(f" 성능 향상: +{(bagging_score - single_score)*100:.1f}%")이정도 정리하고 넘어가자
라고 하려 했는데, 이거는 손으로 직접 쳐보면 좋을 것 같아서 ㅎㅎ bagging 분류법에다가 model들을 다르게 해서 가져온거다. SVM - support vector machine 이랑 KNN을 모델로 넣은거다.
다시 개념 상기하자면 SVM은 두 클래스를 결정 경계(고차원으로 쭉 늘인다음)로 찾는 알고리즘. 실습할 때 svm 커널 로 linear 대신에 RBF쓰연 점수가 더 잘 올랐던게 기억나네
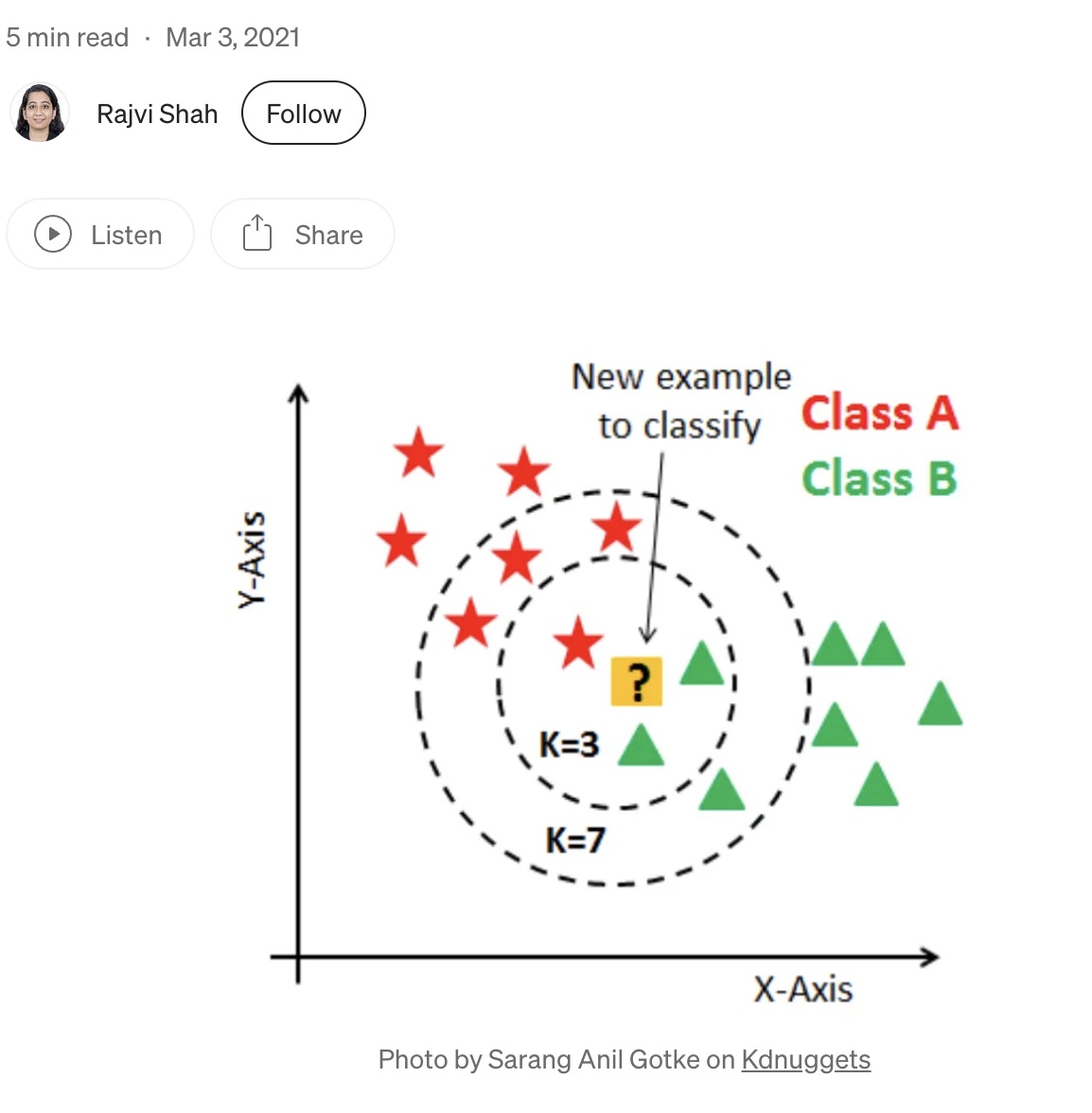
KNN은 아직 정해지지 않은 점 주위를 봤을 때 주변의 점이 2개는 빨간색이고 하나는 초록색이면 빨간색으로 분류. 아래 사진 참고!
Random Forest
다음글에서 정리
