오늘도 어김없이 찾아오는 블로그 정리시간.
솔직히 말하면 코드를 하나하나 손으로 쳐봐라 하면은 못치겠지만, 왜 이거를 이렇게 쳤는지 이렇게 글로 정리하면서 진행하면 이해는 된다. 오늘도 팟팅
1. Maximal Margin Classifier
왜써? 가장 좋은 분류 경계를 찾기 위해서
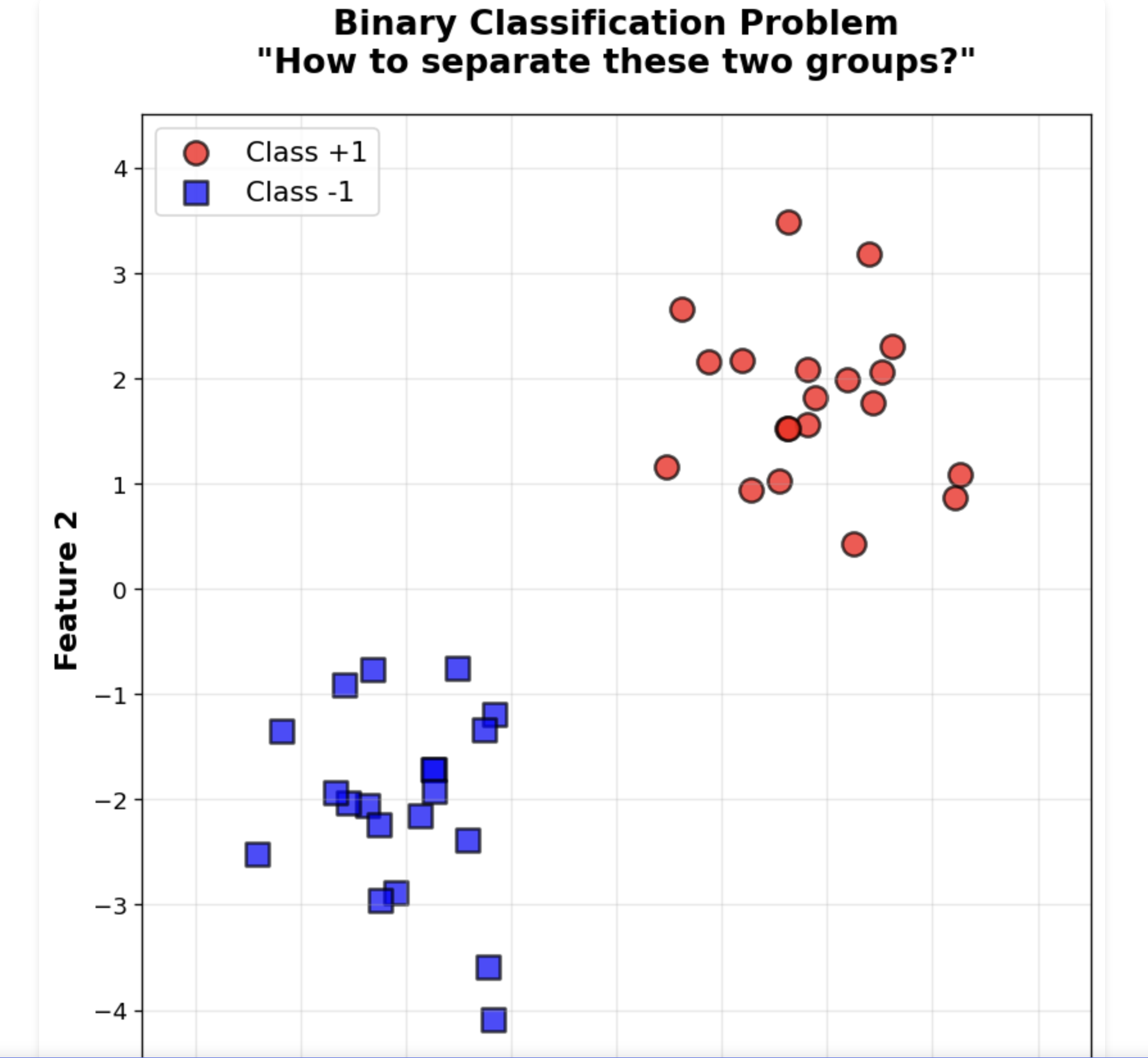
생각해보장, 이렇게 데이터가 주어졌는데.. 어떻게 나누고 싶어?
이때 나누는게 Decision Boundary(결정 경계) 두 클래스를 나누는
선 또는 평면 또는 초평면임
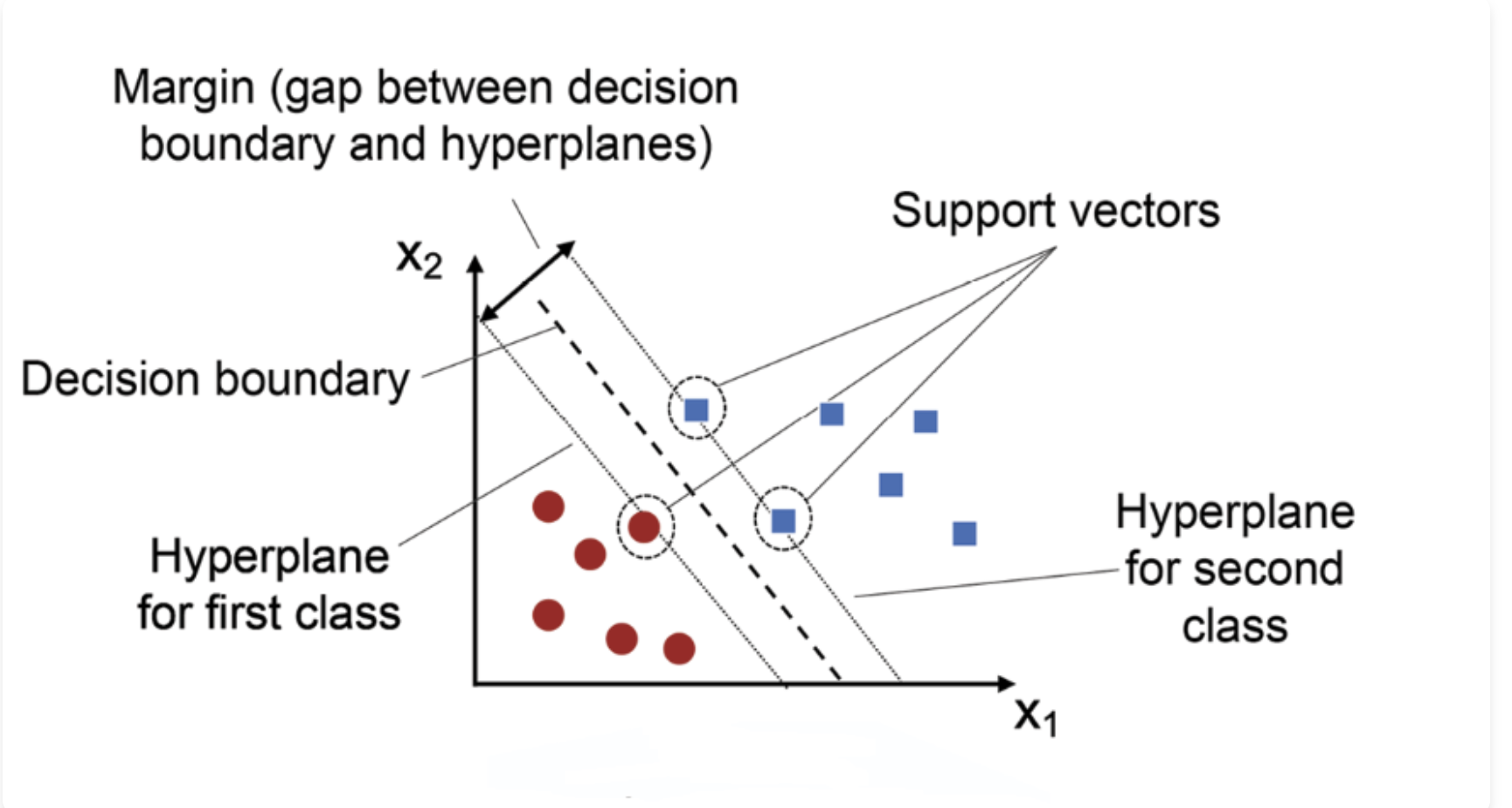
margin
Decision Boundary로부터 가장 가까운 데이터까지의 거리. 조금 더 설명하면 양쪽 클래스의 가장 가까운 점들 사이의 폭
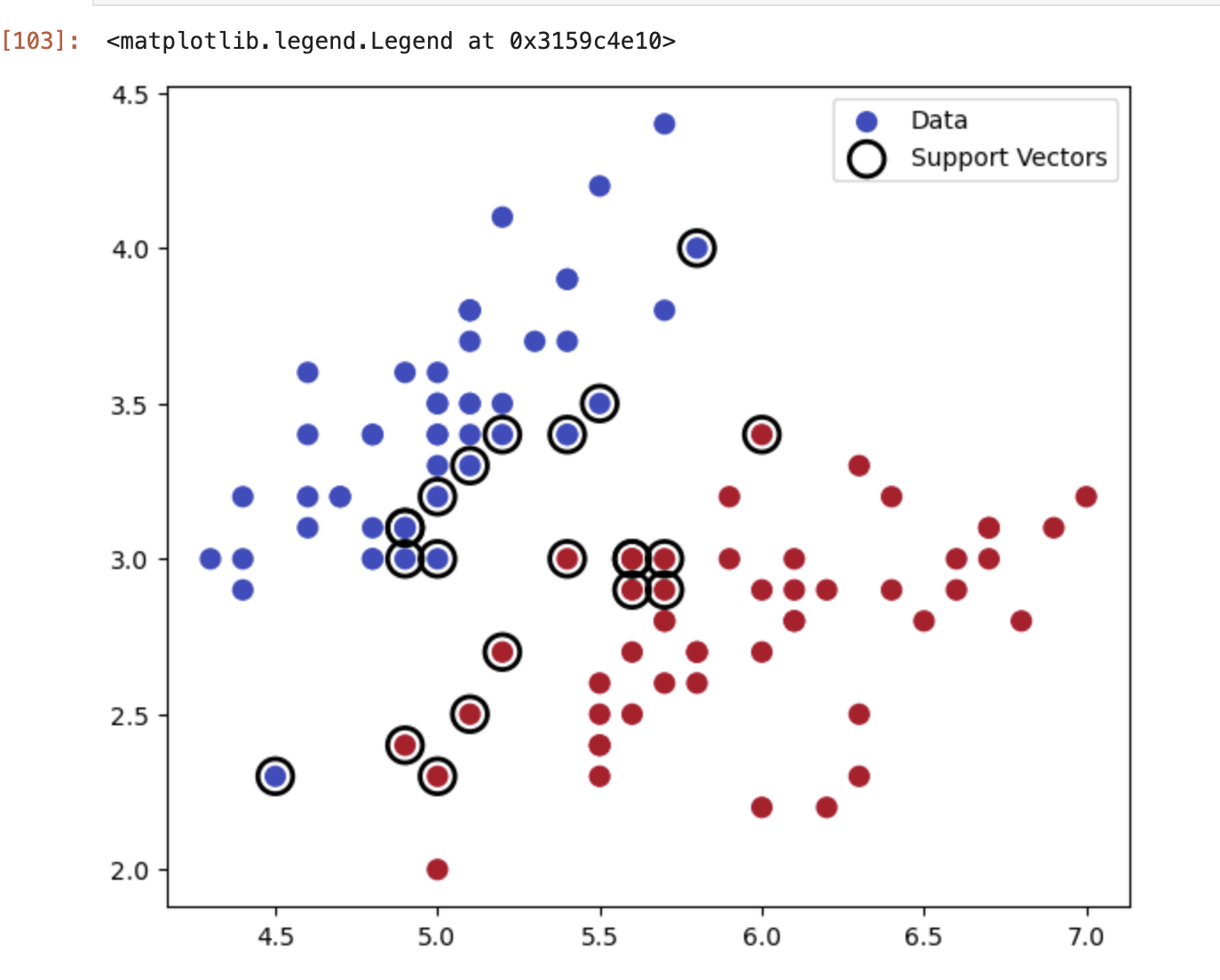
사진 자료로 보면 이렇게 나온다. Decision boundary 가 데이터를 나누는 가장 중심 부분에 있고, 그 주변으로 Support Vectors들이 보이고, 그 Support vectors들 사이로 있는 범위가 margin 이라고 불린다.
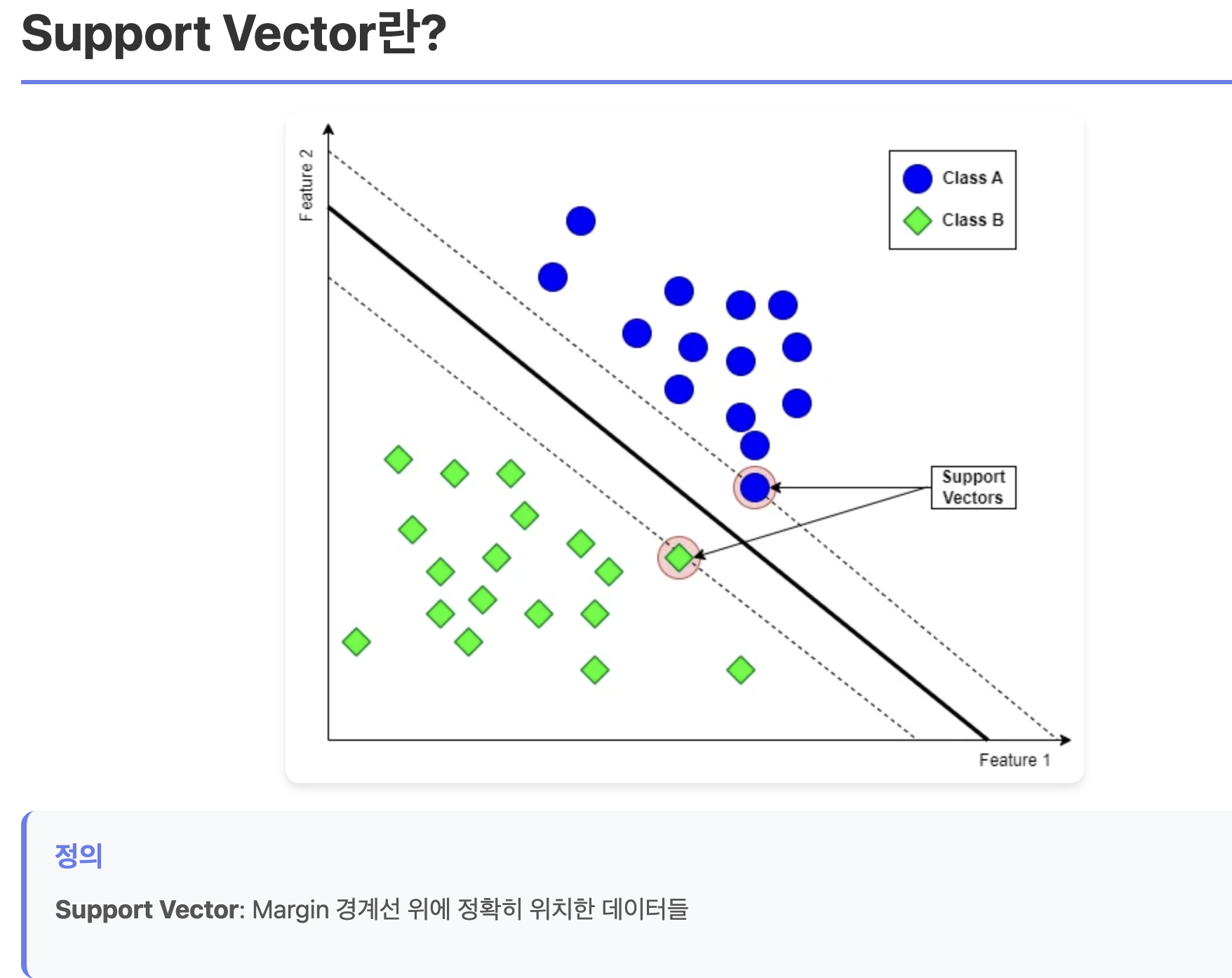
support Vector
요게 서포트 벡터 개념. margin의 끝자락에 있는 실제 데이터들의 위치라고 보면 되려나
전체 데이터들의 5~10퍼정도
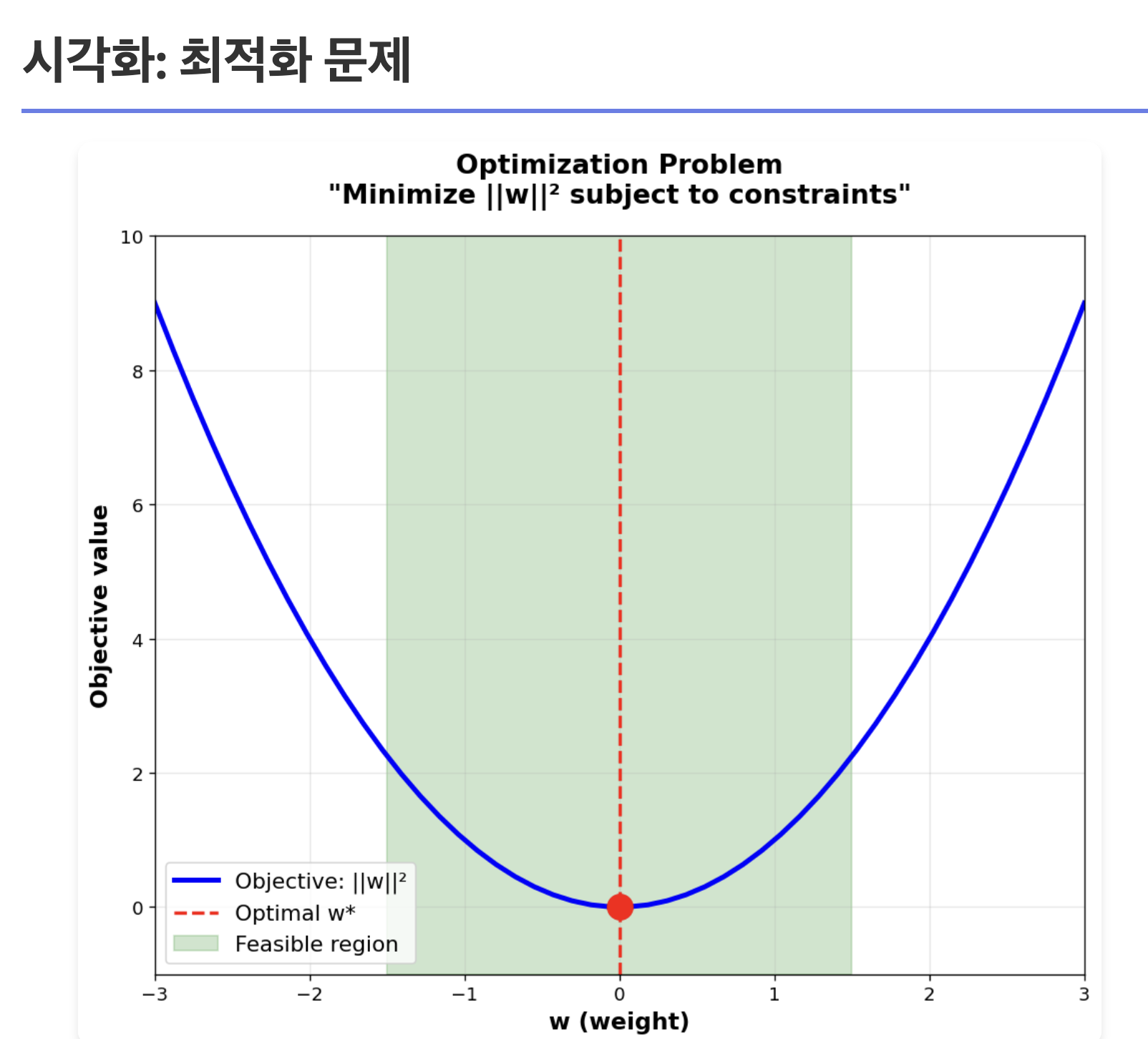
여기서 나오는게, 최적화 문제라는건데, 두 그룹을 나누는 선은 무한이 많다. but 그 중에서 margin이 최대힌 선을 선택해야 한 선을 경계로 두 그룹이 잘 나누어졌다고 말할 수 있음. 이를 계산하기 위해 최적화 문제 개념이 적용됨. 그러면 어떻게 margin을 크게 구할건데? 느낌
아까 앞에 표에서 w개념이 살짝 나왔는데,
margin width = 2/||w|| 이다.
그렇기에 SVM은 w를 최소화하기 위해 계산을 때림
이때 제약조건 shaded 영역이란 개념이 나오는데,
w(가중치)가 가질 수 있는 제한 범위
일단 여기서 추가로 보이는 클래스는 SVC라는 클래스다. 주석보면 C-Support Vector Classification 라고 되어있음. support vector를 정의하는 함수? 인자로는 C값, kernel값, degree, gamma등이 있다.
C값은 기본값으로 1로 되어있지만, 줄이면 줄일수록 margin을 넓게 허용하겠다는 뜻
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC다른거는 다 한번쯤 본거여서 이해 하겠는데, mask 하는 부분이 신기하다
mask = (y == 0) | (y == 1)
X = X[mask]
y = y[mask]설명하자면 위에 X열을 2개만 가져온 거랑도 연관이 있는데, 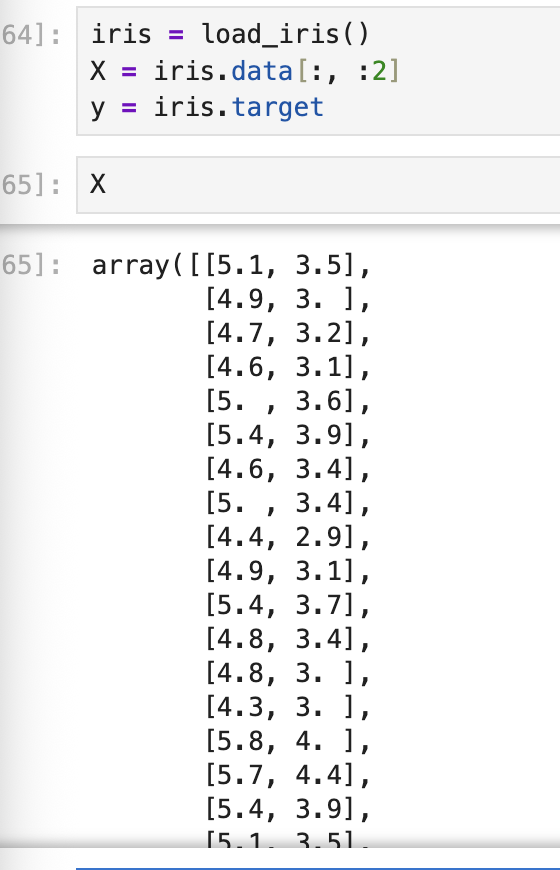 이 중에서 종 2개만 비교해서 보고싶어서 종 0 과 1 이외에는 모두 False처리 해버리겠다는 뜻.
이 중에서 종 2개만 비교해서 보고싶어서 종 0 과 1 이외에는 모두 False처리 해버리겠다는 뜻.
이 데이터 가지고 데이터 분할 해준다음
각 각 train 데이터 가지고 학습 ㄱㄱ
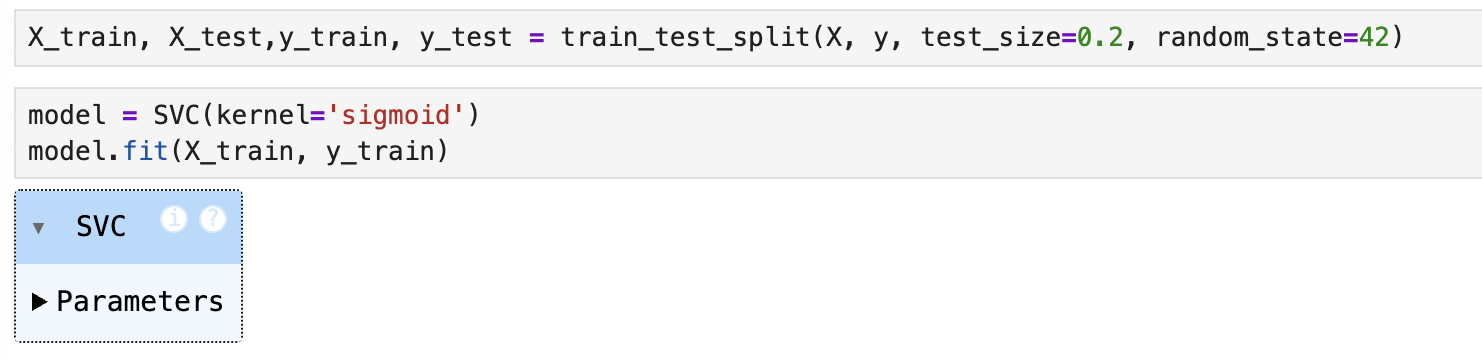
그러면 요렇게 나오는데, 아 이거 할 때 linear 부분에 선형 외에 다른 형의 함수도 있는데, 일단 나중에 데이터 형식에 따라서 달라질 수 있는것도 확인해놓기

저렇게 주석에 보면 해당 인자 값으로 어떤 것을 넣은건지 다 나와있다.
요거는 서포터 벡터 찾는 값인데, model.supportvectors했을 때 값이 저렇게 나온다.
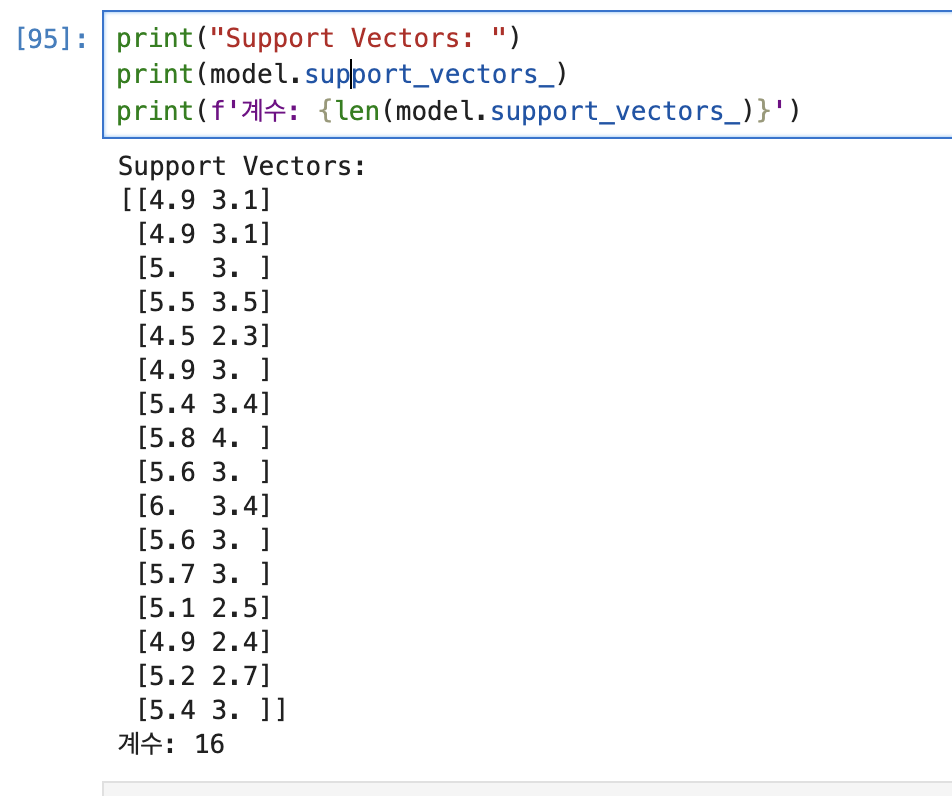
SVC 인자 안에 C값이 마진 값을 조절 해주는 건데, 그냥 기본값인 1 했을 때는 support vector 갯수가 16개가 나왔는데, 0.5로 줄여보니(느슨하게 만들어 보니) 22개로 조금 많아졌다.
여기 아래는 RBF Kernel이랑 Polynomial Kernel 인데 활용방법은 다음과 같음.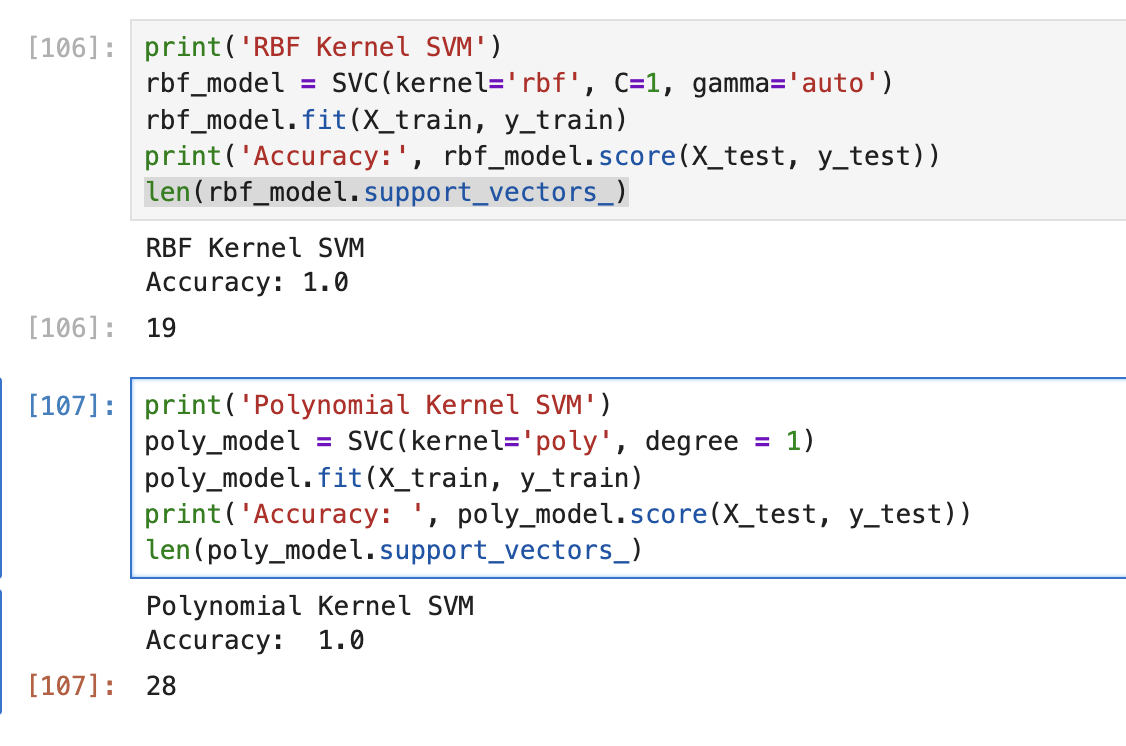 확실히 선형 그래프랑 달리 함수가 조금 꼬아지니 더 support vector가 많아지는 것 같다(19개, 28개).
확실히 선형 그래프랑 달리 함수가 조금 꼬아지니 더 support vector가 많아지는 것 같다(19개, 28개).
2. Lagrange Dual Formulation
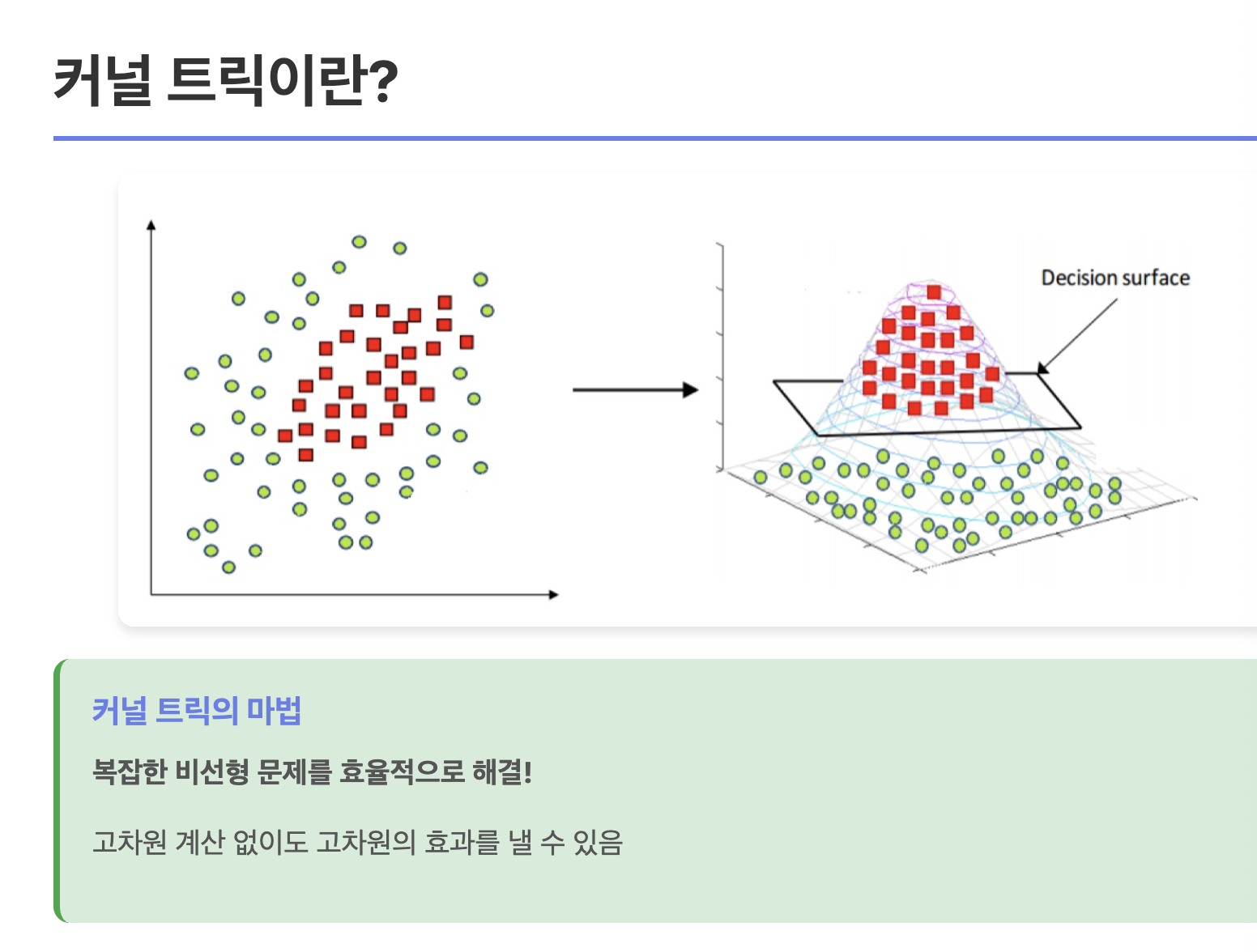
커널트릭
쉽게 설명하면, 선형적으로 구분할 수 었던 데이터를 차원을 높여서 보면 구분할 수 있는 초평면이 보인다. 아래는 사진
듀얼 문제를 왜 풀어?
primal변수는 d(특성 수) 에 의해 결정됨. 보통 이미지, 유전자 데이터등은 특성이 수천~수만일 개이기 때문, w(가중치) 값이 커지면 primal최적화 할 때 계산량 폭팔
그렇기에 dual은 '데이터 개수(n)'만큼만 변수 필요. 이때 dual문제의 변수는 ⍺(알파)라고 불리는 라그랑지 승수이고, 데이터마다 1개씩 존재 👉 총 n개가 됨. 만약 데이터 n이 500개? dual변수도 500개
수학 이것저것 개념이 많은데, 일단 코드먼저 보자 위에 내용 짧게 요약하면, 고차원 데이터에서는 Dual유리하다는 뜻!
