Word2Vec
- 단어간 벡터 연산: 고양이 + 애교 = 강아지, 한국 - 서울 + 도쿄 = 일본
이런 연산을 할 수 있는 이유는 각 단어 벡터가 단어간 유사도를 반영한 값을 가지고 있기 때문이다.
Word2Vec는 단어간 유사도를 반영하도록 단어의 의미를 벡터화하는 방법이며, CBOW와 Skip-Gram이 있다. CBOW는 주변의 단어를 통해 중간 단어를 예측하고 Skip-Gram은 중간 단어로 주변 단어를 예측한다. (Word2Vec의 입력은 원-핫 벡터)
CBOW(Continuous Bag of Words)
-
간소화된 형태
-
중심 단어(center word): 예측할 단어
-
주변 단어(context word): 예측에 사용되는 단어
-
윈도우(window): 중심 단어를 예측하기 위해 앞, 뒤로 몇 개의 단어를 보는 범위
윈도우 크기가 n이면 실제 중심 단어를 예측하기 위해 참고하는 주변 단어의 개수는 2n(앞에서 n개, 뒤에서 n개)이다.
- 슬라이딩 윈도우(sliding window): 윈도우 크기를 정했다면 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만드는 방법
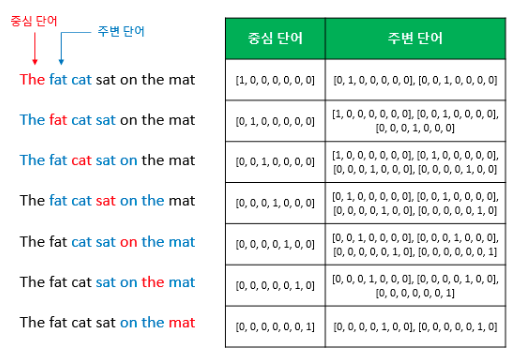
위의 그림 중 왼쪽 그림은 윈도우 크기가 2일때 슬라이딩 윈도우가 어떤 식으로 이루어지면서 데이터 셋을 만드는지를, 오른쪽 그림은 중심 단어와 주변 단어를 어떻게 선택했을 때 어떤 원-핫 벡터가 되는지를 보여준다.
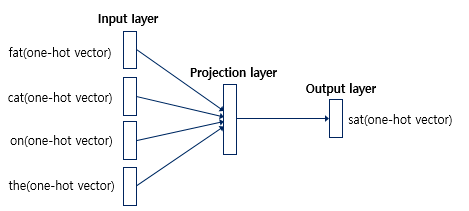
입력층의 입력으로 윈도우 크기 범위 안의 주변 단어들의 원-핫 벡터가 들어가고 출력층에서 예측하고자 하는 중간 단어의 원-핫 벡터가 필요하다.
Word2Vec은 입력층과 출력층 사이에 하나의 은닉층만 존재하므로 딥러닝 모델이 아니다. 이처럼 은닉층이 1개인 경우는 얕은 신경망(shallow Neural Network)이라고 한다. Word2Vec의 은닉층은 룩업 테이블이라는 연산을 담당하는 투사층(projection layer)이다. (활성화 함수 없음)
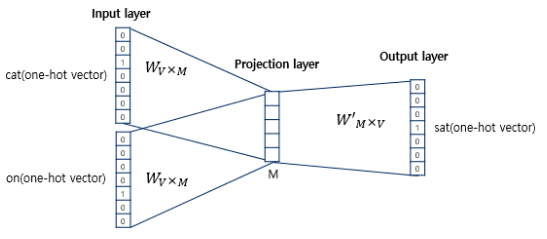
위의 그림에서 주목할 부분은 두 가지이다. 첫째, CBOW에서 투사층의 크기 M은 임베딩한 후의 벡터의 차원와 같다. 둘째, 입력층과 투사층 사이의 가중치 W는 V x M 행렬이고 입력층과 투사층 사이의 가중치 W는 V × M 행렬이며, 투사층에서 출력층사이의 가중치 W'는 M × V 행렬이다. 여기서 V는 단어 집합의 크기이며, 두 가중치 행렬은 서로 다른 행렬이다. 가중치 행렬 W와 W'는 대게 굉장히 작은 랜덤 값을 가지며 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W'를 학습해 간다.
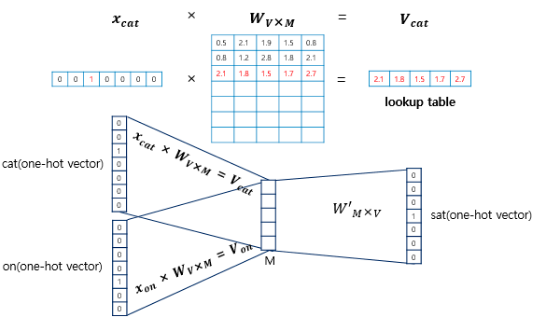
입력인 주변 단어의 원-핫 벡터와 가중치 W 행렬의 곱은 W 행렬의 i번째 행을 그대로 읽어오는 것(lookup)이다. (이 과정이 룩업 테이블) 즉 lookup한 W의 각 행벡터가 Word2Vec을 수행한 후의 각 단어의 M차원의 크기를 갖는 임베딩 벡터이다. 따라서 가중치 행렬을 잘 훈련시키면 중심 단어를 더 정확히 맞출 수 있다.
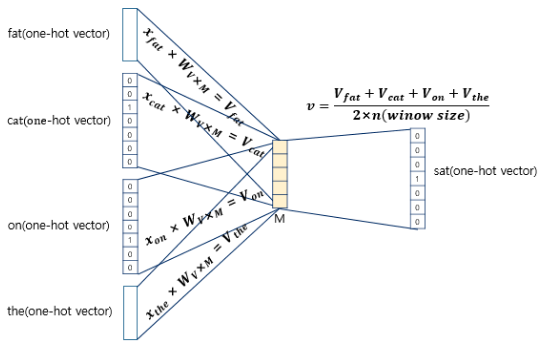
주변 단어의 원-핫 벡터에 대해 가중치 W를 곱해서 얻은 벡터들은 투사층에서 이 벡터들의 평균 벡터를 구한다. 만약 윈도우 크기가 2라면 4개의 결과 벡터에 대해 평균을 구한다. (Skip-Gram과의 차이점)
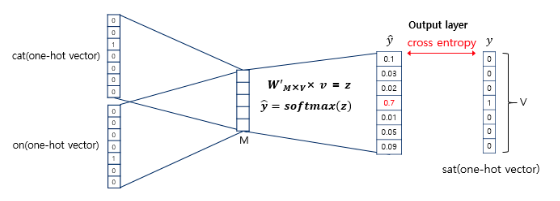
위에서 구해진 평균 벡터는 두 번째 가중치 행렬 W'와 곱해지고 그 결과 원-핫 벡터와 차원이 V로 동일한 벡터가 나온다. 이 벡터에 소프트맥스 함수를 취해 스코어 벡터를 구한다. (소프트맥스 함수로 인한 출력값은 0~1 사이의 실수, 각 원소의 총합은 1)
스코어 벡터의 j번째 인덱스가 가진 0과 1 사이의 값은 j번째 단어가 중심 단어일 확률이다. 이 스코어 벡터와 중심 단어 원-핫 벡터(target word) 사이의 오차를 줄이기 위해 손실 함수로 cross-entropy 함수를 사용하고, 이 값을 최소화하는 방향으로 학습한다. 역전파를 수행해 W와 W'를 학습하고, 학습을 다한 후에 M차원의 크기를 갖는 W의 행이나 W'의 열로부터 어떤 것을 임베딩 벡터로 사용할지 결정한다. 때로 W와 W'의 평균치로 임베딩 벡터를 선택하기도 한다.
Skip-gram
CBOW와 메커니즘은 동일하다. Skip-gram은 중심 단어에서 주변 단어를 예측한다. 윈도우 크기가 2일 때 데이터셋의 구성은 아래와 같다.
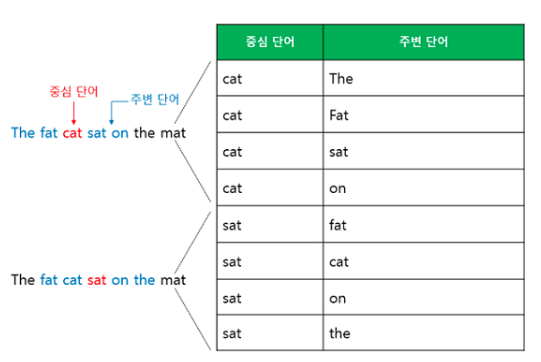

중심 단어에서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없다. 논리적으로 CBOW가 더 좋아보이지만 실제에서는 Skip-gram이 더 성능이 좋다.
- Word2Vec의 단점
- 모르는 단어와의 유사도를 계산할 수 없다.
- 희귀 단어의 임베딩 정확도가 낮다.
- 영어가 아닌 언어에 적용하면 문제가 생긴다.
FastText
페이스북에서 개발한 단어를 벡터로 만드는 방법이며 매커니즘은 Word2Vec의 확장이다. 그러나 Word2Vec와 달리 FastText는 하나의 단어 안에 있는 내부 단어(subword)를 고려한다.
내부 단어의 학습
각 단어는 글자 단위 n-gram의 구성이다. n의 크기에 따라 내부 단어의 수가 결정된다. 어휘를 구성하는 n-gram마다 임베딩 벡터를 할당하고, 어휘를 구성하는 모든 n-gram 벡터의 평균 벡터를 어휘 임베딩으로 본다.
아래와 같이 시작과 끝을 의미하는 <, >을 도입하고 5개의 n-gram으로 쪼갠다. 5개의 내부 단어 토큰을 벡터로 만든다. 여기에 기존 단어에 <와 >를 붙인 특별 토큰을 벡터화킨다.
# n = 3인 경우
<ap, app, ppl, ple, le>, <apple>여기서 내부 단어를 벡터화한다는 의미는 위의 단어들에 대해 Word2Vec을 수행한다는 의미이다. 내부 단어의 벡터값을 얻었다면 단어 apple의 벡터값은 위에서 구한 벡터값의 총 합이다.
apple = <ap + app + ppl + ppl + le> + <app + appl + pple + ple> + <appl + pple> + , ..., +<apple>이런 방식을 사용하면 어휘 안에 포함된 다양한 요소를 n-gram 수준에서 학습하므로 동일한 의미를 갖는 어휘의 변화하는 패턴을 학습하기 쉽다.
- FastText의 장점
- FastText의 인공 신경망을 학습한 후 데이터셋의 모든 단어는 각 n-gram에 대해 워드 임베딩이 된다. 데이터셋만 충분하면 내부 단어를 통해 모르는 단어도 다른 단어와의 유사도를 계산해 벡터를 얻을 수 있다.
- 등장 빈도수가 적은 단어의 임베딩의 정확도가 낮은 Word2Vec과 달리 FastText는 희귀단어라도 그 단어의 n-gram이 다른 단어의 n-gram과 겹치면 Word2Vec보다 높은 임베딩 벡터값을 얻는다.그래서 FastText는 노이즈(오타, 맞춤법이 틀린 단어)가 많은 코퍼스에서도 일정 수준의 성능을 보인다.
- 적은 양의 학습 데이터로도 높은 성능을 낼 수 있다.
- 동일한 의미를 갖는 어휘의 변화 패턴을 학습하기 쉽다.
ELMo
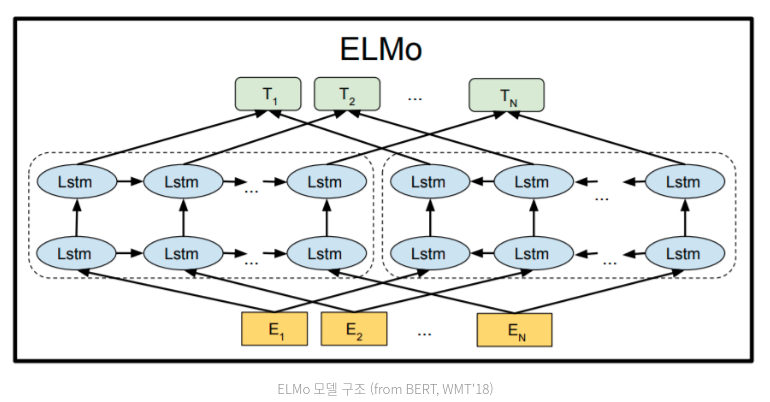
- 입력: 기존 어휘 임베딩()을 사용
- 양방향 LSTM(biLM): 양방향 LSTM = 순방향 LSTM + 역방향 LSTM
순방향 LSTM은 주어진 문장에서 시작해 n개의 단어를 보고 n+1번째 단어를 맞춘다. 역방향 LSTM(오른쪽)은 주어진 문장의 끝부터 n개의 단어를 역순으로 보고 n-1번째 단어를 맞춘다. 각 LSTM은 서로의 hidden state를 공유하지 않고 학습 시 로그 우도(나중에 다시 공부할 것!)를 동시에 최대화하는 방식으로 학습한다. - 학습: 언어 모델을 학습할 때는 양방향 LSTM이 생성한 hidden state를 concat한 벡터()를 소프트맥스 레이어를 통과해 예측하고자 하는 단어를 맞추지만 임베딩을 생성할 때는 이 레이어는 제거된다.
- ELMo Embedding: 다른 모델에 사용될 어휘 임베딩 벡터로, 기존 어휘 임베딩, 순방향 LSTM의 hidden state, 역방향 LSTM의 hidden state를 모두 종합해서 붙인 벡터이다.
- ELMo Embedding를 언어 모델의 LSTM 레이어 별로 가중치를 두고 더한다. 가중치는 소프트맥스 레이어로 정규화된 가중치이고, 이 값은 사용자가 ELMo 임베딩을 사용할 과제에 맞춰 학습된다. 과제가 사용하는 모델이 ELMo 임베딩에 어떤 파트에 주의(attention)를 기울일지 가중치를 주는 부분이다.
- 이런 과정을 통해 어휘가 문맥에 따라 서로 다른 임베딩을 갖는 것이 가능해진다.
- ELMo의 장점
- 어휘 임베딩 맥락화 가능
- ELMo 임베딩을 인공신경망 모델의 입력으로 사용할 때 성능 향상 - 학습된 모델의 지식을 임베딩으로 전이
- 데이터 셋의 크기 줄일 수 있다.
- 레이블링이 어려웠던 다양한 과제에 대해 지도학습 기반 인공신경망 모형을 쉽게 적용할 수 있다.
