목표
10M 정도의 작은 파라미터 사이즈의 BERT 모델을 만들어, 수백MB 수준의 코퍼스 기반으로 pretrain을 진행한다.
순서
- Tokenizer 준비
- 데이터 전처리 (1) MASK 생성
- 데이터 전처리 (2) NSP pair 생성
- 데이터 전처리 (3) 데이터셋 완성
- BERT 모델 구현
- pretrain 진행
BERT
BERT(Bi-directional Encoder Representations from Transformers)는 bi-directional Transformer로 이루어진 언어모델이다. 특히 self-attention layer를 여러 개 사용해 문장 내 token 사이의 의미 관계를 추출하였다. 또한 BERT는 2가지 학습 방법으로 Encoder를 학습시킨 후 특정 task를 fine-tuning하여 결과를 얻는다. Encoder는 양방향성을 띄고 있으며 양방향성은 모델이 문맥-문장 내 단어의 관계성-을 파악하는데 도움을 주었다.
잘 만들어진(pretrained) BERT 언어모델은 마지막 출력층에 1개의 layer를 추가해 fine-tuning하여 다양한 NLP task를 수행할 수 있다. 영어권에서는 11개의 NLP task에 대해 state-of-the-art (SOTA)를 달성하였다. (현재는 RoBERT, ALBERT 등이 나오면서 Leaderboard의 순위가 많이 떨어졌다.) 그러나 BERT는 원래 Language Representation을 해결하기 위해 고안되었다. 즉 단어, 문장, 언어를 잘 표현하기 위해 만들어졌다고 한다.
아래의 그림은 BERT 언어 모델 위에 1개의 classification layer를 부착하여 fine-tuning한 예이다. 예문과 질문을 입력으로 넣으면 그에 대한 답변이 출력으로 나온다. (QA task)
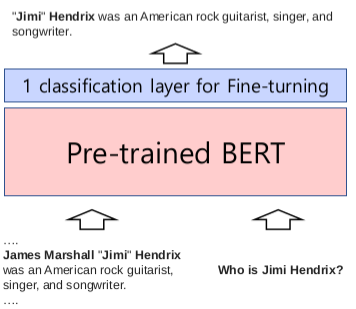
BERT Architecture
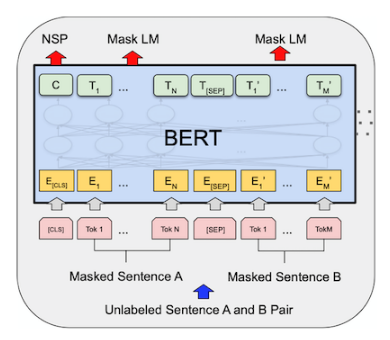
BERT의 구조는 위의 그림과 같다. Unlabelled Sentence A와 B에 tokenizing과 masking을 한 후, 이 두 문장을 [SEP]으로 연결하여 Pretrained BERT에 입력으로 집어넣는다. 이로 인해 양방향 표현을 사용할 수 있다.
BERT는 2개의 Task를 동시에 학습 함으로써 성능을 높일 수 있었다. 한 개의 task는 두 문장의 순서가 맞는지 맞추는 NSP(Next Sentence Prediction) 이고, 또 하나는 Mask된 단어를 예측 하는 것이다. 따라서 NSP 토큰 하나와 mask된 단어가 예측된 문장이 출력값이 된다.
| Transformer layer(L) | 12 | 24 |
| Self-attention head(A) | 12 | 16 |
| hidden layer(H) | 768 | 1024 |
| Total Parameters | 110M | 340M |
BERT는 BASE와 LARGE 2가지가 있고(자세한 내용은 표 참고), 성능은 LARGE가 더 높다. 두 가지 모델 모두 feed-forward/필터 사이즈는 4H이다.
Pretrained 모델의 학습 데이터
Pretrain할 때는 레이블링이 없는 학습 데이터를 사용한다. 또한 학습 데이터는 적용할 도메인과는 상관 없다.
- BooksCorpus (800M words)
- English Wikipedia (2,500M words without lists, tables and headers)
- 30,000 token vocabulary
fine-tuning할 때는 타겟 도메인을 가진 레이블 데이터를 사용한다.
3개의 Embedding - Token, Segment, Position
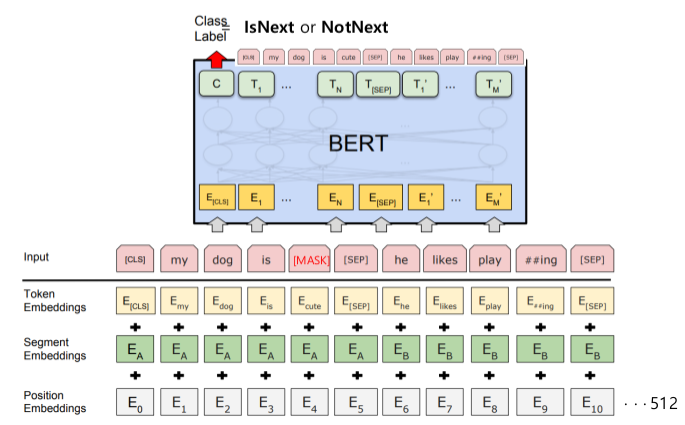
- Token Embedding: Wordpiece를 이용해 3만개의 vocabulary를 학습했다. 학습한 Wordpiece model을 이용해 token을 임베딩해준다. [CLS]와 [SEP]이라는 특수 토큰을 사용해 문장을 구별한다.
- Segment Embedding: 두 가지 sentence(텍스트 덩어리의 의미)를 입력으로 받기 때문에 2가지 sentence를 구분해야 한다. 모델의 입장에서 이어진 텍스트들의 덩어리를 segment embedding이 나누어 준다. 그림에서 [SEP] 토큰으로 구분된 두 sentence에서 앞부분은 A, 뒷부분은 B로 나누어 임베딩하고 있다. (index, label 지정)
- Position Embedding: segment embedding에서 두 sentence를 나누었지만 sentence 안에서의 순서를 모른다. 따라서 position embedding을 통해 문장 내에서 절대적인 위치(순서)를 알려준다. 학습을 통해 position 정보를 습득한다.
입력 데이터에 3가지 Embedding을 하여 element-wise하게 더한 후, layer normalization과 dropout까지 해주면 트랜스포머 첫 블록이 완성된다.
2 가지 방법의 pretraining - MLM, NSP
문장 표현을 학습하기 위해 2 가지 Unsupervised 방법을 동시에 사용한다.
Masked Language Model(MLM)
BERT는 마스크된 토큰([MASK])만 맞추면 되는 Masked LM(MLM)을 제안했다. 따라서 input sequence의 순서에 상관 없이 전체 문장을 모두 볼 수 있다.
문장에서 단어의 15%를 [mask] 토큰으로 바꾸고, 주변 단어(토큰)의 문맥을 이용해 마스크 처리된 토큰을 예측하도록 학습한다. 이 과정에서 BERT는 문맥을 학습할 수 있다. Input에 Mask를 사용하지 않는 Fine-tuning을 위해 15% 중 80%만 [mask] 토큰으로, 10%는 random word로, 나머지 10%는 원본 그대로 사용한다. 마지막 히든 벡터는 마스킹 토큰과 일치하며 마지막 히든 벡터는 출력시 어휘들에 대한 softmax를 반영한다.
Deep bidirectional transformer
MLM을 통해 마스크 처리된 토큰을 예측하고 left 토큰과 right 토큰들의 문맥 정보도 고려하는 방식
Next Sentence Prediction(NSP)
다음 문장이 올바른 문장인지 맞추는 문제로, 이 문제를 통해 두 문장 사이의 관계를 학습한다. Binary Classificaton Loss를 계산해 현재 문장과 다음 문장의 관계 정도가 얼마인지를 측정한다. NSP 학습은 Positive 예제와 Negative 예제를 고려한다(50%씩). Positive 예제는 연속 추출한 두 문장을 쌍으로 만들고, Negative 예제는 상이한 문서에서 추출한 문장을 쌍으로 만든다. (구분자 [SEP] 이용, 노드에서는 Negative 예제를 위해 연속 추출한 두 문장의 순서를 바꾸었다.) 모든 예제가 완성되면 Positive 예제와 Negative 예제를 동등한 확률로 샘플링한다.
- max_num_tokens 정의
task가 너무 쉬워지는 것을 방지하기 위해 max_num_tokens를 정의한 후, 데이터의 90%는 max_num_tokens = max_sequence_length, 10%의 데이터는 max_num_tokens < max_sequence_length이 되도록 랜덤으로 정한다. 이후 두 개의 sentence의 단어 총수가 max_num_tokens보다 작아질 때까지 두 sentence 중 단어 수가 많은 쪽의 문장 맨 앞 또는 맨 뒤 단어를 하나씩 제거한다. 문장 맨 앞의 단어를 선택할지, 맨 뒤의 단어를 선택할지는 50%의 확률로 정한다.
이렇게 NSP를 학습하면 문장과 문장 사이의 관계를 학습할 수 있다. 문장의 길이를 임의로 조정하면서 짧은 문장에 대해서도 성능이 크게 떨어지지 않게 되며, 문장의 단어들을 랜덤하게 삭제하는 과정을 통해 문장의 일부 단어들이 없어져도 큰 영향을 받지 않는다.
이 문제를 통해 QA(Question Answering)나 NLI(Natural Language Inference) 등 Downstream tasks의 성능을 높일 수 있다고 한다.
Tokenizer - WordPiece Tokeninzing
BERT에서 사용한 Tokenizer는 WordPiece 모델이다. Word Piece 모델은 언어에 상관 없이 Tokenization을 할 수 있다. (BERT를 발표할 당시, 영어 언어모델 뿐 아니라 Multilingual Model도 선보였다고 한다.) 이 방법은 BPE(Byte Pair Encoding)와 유사하다.
수백만개의 단어를 포함하는 데이터를 표현하려면 word2vec 등 기존 모델에서는 단어의 개수만큼의 차원을 지닌 벡터를 학습해야 한다. 그러나 모델의 크기는 단어의 개수에 영향을 받으므로 단어의 개수를 제한할 수 밖에 없고, 그로 인해 자주 사용하지 않는 단어는 임베딩 벡터로 표현하지 못한다(OOV - Out of Vocabulary 문제).
이 문제를 해결하기 위해서 단어를 표현할 수 있는 subwords(의미 있는 패턴)units으로 모든 단어를 표현하는 것이 Word Piece 모델이다. 여기서 subwords units는 자주 사용하는 단어이고, 자주 등장하지 않는 단어는 rare words로 지정한다. Word Piece 모델을 사용하면 OOV문제를 해결할 수 있고, 언어에 상관 없이 모두 적용할 수 있다.
모든 단어의 시작에는 '_'를 붙이고 자주 사용하는 단어(makers, over 등)는 units으로, 자주 등장하지 않는 단어(jet, feud 등)는 subword units으로 나눈다.
- 논문에서 사용한 예
- Word : Jet makers feud over seat width with big orders at stake
- Wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
여기서 '_'는 문장 생성 또는 문장 복원을 위한 특수기호이다.
def recover(tokens):
sent = ''.join(tokens)
sent = sent.replace('_', ' ')
return sentWord Piece 모델은 BPE(Byte Pair Embedding) 알고리즘을 사용하였고, BPE는 아래와 같은 방식으로 동작한다.

1. Tokenizer - SentencePiece 모델
Token Embedding
노드에서는 WordPiece 모델보다 성능이 좋은 SentencePiece 모델을 사용하여 토큰화를 시켰다.
SentencePiece는 SentencePiece는 Google에서 제공하는 오픈소스 기반 Sentence Tokenizer/Detokenizer 로서, BPE와 unigram 2가지 subword 토크나이징 모델 중 하나를 선택해서 사용할 수 있도록 패키징한 것이다.
SentencePiece는 딥러닝 자연어처리 모델의 앞부분에 사용할 목적으로 최적화되어 있는데, 최근 pretrained model들이 거의 대부분 SentencePiece를 tokenizer로 채용하면서 사실상 표준의 역할을 하고 있다.
spm.SentencePieceTrainer.train(
f"--input={corpus_file} --model_prefix={prefix} --vocab_size={vocab_size + 7}" +
" --model_type=bpe" +
" --max_sentence_length=999999" + # 문장 최대 길이
" --pad_id=0 --pad_piece=[PAD]" + # pad (0)
" --unk_id=1 --unk_piece=[UNK]" + # unknown (1)
" --bos_id=2 --bos_piece=[BOS]" + # begin of sequence (2)
" --eos_id=3 --eos_piece=[EOS]" + # end of sequence (3)
" --user_defined_symbols=[SEP],[CLS],[MASK]") # 사용자 정의 토큰
vocab = spm.SentencePieceProcessor()
vocab.load(f"{model_dir}/ko_32000.model")위의 코드를 통해 SentencePiece 모델과 단어장을 만든다. 만들어놓은 모델을 사용해 토큰화를 하면 아래와 같은 결과처럼 나온다.

[CLS](special classification token)는 모든 문장의 가장 첫 번째 토큰이다. [CLS]는 transformer layer를 거치고 나면 token sequence의 결합된 의미를 가지게 되고(?), 여기에 간단한 classifier를 붙임으로써 단일 문장 또는 연속된 문장의 classification을 쉽게 할 수 있다. 그러나 Classification task가 아니면 무시하면 된다.
[SEP]는 '구분자'라고 불리는 토큰으로, 두 개의 문장(실제로는 수 개의 문장으로 구성될 수 있음)을 구별할 때와 각 문장의 끝에 사용된다.
2. 데이터 전처리 (1) MASK 생성
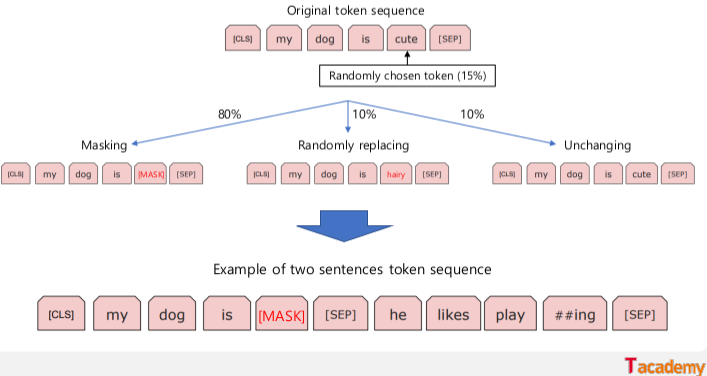
마스킹된 단어를 예측하는 문제를 풀기 위해서 Mask를 생성한다. Mask는 전체 단어의 15%를 선택한다. 학습과 달리 Pretrained Model은 mask를 사용하지 않으므로 마스킹할 15%의 단어 중 80%는 마스킹을 해주고, 10%는 아무 단어로 바꿔주고, 10%는 원래 단어 그대로를 넣어 준다.
마스킹을 할 때 주의할 점은 subword units을 기반으로 마스킹을 하면 마스킹한 단어를 예측하기 쉬우므로 (예: _대, [MASK], 민국) 띄어쓰기 단위로 한 번에 마스킹 해준다. (코드 생략)

- 코드 구현 순서
- 전체 token 중 15%를 mask라는 변수로 지정한다.
- 띄어쓰기 단위로 마스킹하기 위해 subwords 인덱스를 단어 단위로 분할한다. (예: [1, 2, 3]['▁추적', '추', '적'])
- random mask를 위해 인덱스의 순서를 섞는다. (shuffle)
- 15%의 마스크 중 80%는 마스크 토큰, 10%는 랜덤한 단어, 10%는 원래 단어로 바꿔준다.
- 마스크를 정렬한 후, 마스크의 인덱스와 정답을 추출한다.
3. 데이터 전처리 (2) NSP pair 생성
NSP는 문장 2개를 붙여놓고 두 문장이 이어지는 것인지 아닌지, 문장의 호응관계를 맞추게 하는 것이다. 이 task를 위해 입력 데이터(한 문장)를 NSP Pair(두 문장)로 짝지어 준다.
하나의 sequence인 입력 데이터를 2개의 문장(NSP Pair, 실제로는 여러 개의 문장으로 구성될 수 있음)으로 나누기 위해 1) [SEP] 토큰을 사용하고 2) Segment Embedding을 사용해 앞 문장에는 sentence A embedding, 뒷 문장에는 sentence B embedding을 더해준다. (고정된 값)
-
최종 데이터셋 결과 확인

-
코드 구현
- 하나의 문장을 줄 단위로 토큰화한다.
- 원문에서 이어진 두 문장씩 짝짓는다. (무작위로 숫자 하나를 뽑아 그 수만큼 token a에 들어갈 줄들을 넣고, token b에 나머지 줄들을 넣는다.)
- 두 문장이 최대 길이를 유지하도록 trim해준다.
- 50%의 확률로 True(1)/False(0) 케이스를 생성한다. (원래 순서면 True, 역순이면 False이다.)
5.두 문장 사이에 segment 처리를 해준다. 즉 첫 번째 문장의 segment는 모두 0, 두 번째 문장은 1로 채운 후 둘 사이의 구분자인 [SEP]를 넣어준다. - 위에서 만들어 놓은 mask 처리를 해준다.
4. 데이터 전처리 (3) 데이터셋 완성
사용할 데이터를 불러와 앞에서 했던 전처리를 수행하여 데이터셋 파일을 만든다. 만들어진 데이터를 로딩한다.
5. 모델 구현
- Encoder에 대한 자세한 설명은 [E-15] Transformer 참조
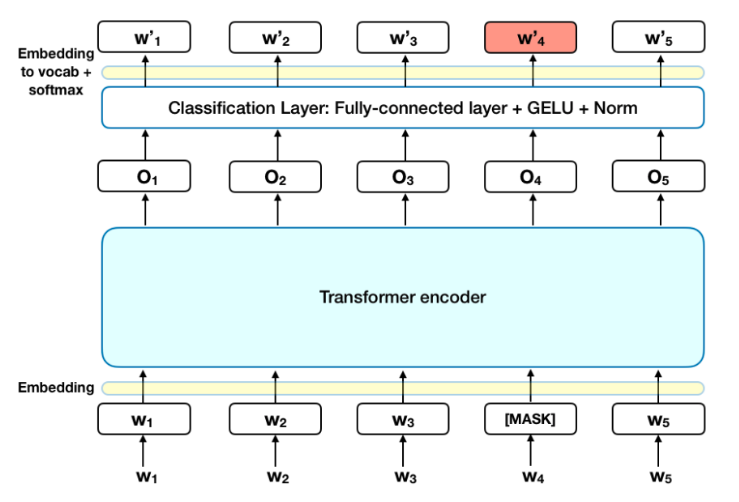
(출처: BERT explained)
-
유틸리티 함수 정의
1) pad mask
2) ahead mask
3) GELU 함수
4) Parameter, bias 초기값 생성
5) Config 클래스 -
Embedding
6) SharedEmbedding
7) Positional Embedding
- Segment Embedding은 BERT 클래스에 포함한다.
- Attention
8) ScaleDotProductAttention
9) MultiHeadAttention
- dense layer로 만들어진 Q, K, V가 ScaleDotProductAttention(self-attention)를 통과 후 linear로 만들어짐
10) PositionWiseFeedForward
- 활성화 함수 사용
- Encoder
11) Encoder Layer
- MultiHeadAttention -> LayerNormalization -> PositionWiseFeedForward -> LayerNormalization
- BERT
12) BERT
-
inputs(enc_tokens, segments) -> self_mask(pad_mask) -> Embed -> Dropout -> EncoderLayer ->
-
Embed = (SharedEmbedding + PositionalEmbedding + segment Embeddig(Embedding) -> LayerNormalization)
13) PooledOutput
- 2개의 Dense layer 통과
14) build_model_pre_train
-
Input(enc_tokens, segments) -> BERT(config) -> PooledOutput -> Softmax(nsp, mlm 2개 따로 진행)
-
config = {'d_model': 256,
'n_head': 4,
'd_head': 64,
'dropout': 0.1,
'd_ff': 1024,
'layernorm_epsilon': 0.001,
'n_layer': 3,
'n_seq': 256,
'n_vocab': 32007,
'i_pad': 0}
6. Pretrain 진행
1) loss 함수
SparseCategoricalCrossentropy 사용
2) Accuracy 계산
3) Learning Rate Scheduling
CosineSchedule class 사용
4) Optimizer - Adam
- BERT의 실제 Hyperparameters
- tokens: 512
- Batch size: 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) for 1,000,000 steps -> 3.3 billion word corpus의 40 epochs
- epochs: 40
- Adam Optimizer
- Learning rate: 1e-4,
- L2 Weight decay: 0.01, learning rate warmup over the first 10,000 steps, linear decay of the learning rate
- Dropout prob: 0.1
- Activation function: GELU
- BERT_base: 4 TPUs, BERT_larget: 16 TPUs 사용 (4일 학습)
참고 자료
- AIFFEL Going Deeper NLP 16
- [토크ON세미나] 자연어 언어모델 ‘BERT’ 3강 - BERT | T아카데미
- https://wikidocs.net/22592
- BERT 설명하기
- BERT 논문, 리서치 리뷰
- BERT 논문정리
