Introduction

본 논문은 RAG 시스템의 핵심 단계인 text chunking 문제를 다룬다. 기존 청킹 방식(문장 단위, 일정 길이 단위, 구조 기반 등)은 실제 서비스 문서의 복잡한 구조나 노이즈를 충분히 처리하지 못해, 의미 단위가 잘게 분리되거나 불필요한 내용이 포함되는 한계를 가진다. 이러한 문제는 검색 품질 저하, 불완전한 컨텍스트 제공, 최종 사용자 경험 악화로 이어진다.
AutoChunker는 이러한 한계를 해결하기 위한 bottom-up 방식의 구조 기반 청킹 기법을 제안한다. 문서를 문장 단위로 분해한 뒤, LLM을 활용해 의미적으로 연결된 문장들을 묶어 논리적 단위의 청크로 재구성한다. 동시에 문서 내에 흔히 존재하는 노이즈(헤더/푸터, 광고 요소, 중복 콘텐츠 등)를 자동으로 제거한다.
또한 저자들은 단순히 방식을 제안하는 데 그치지 않고, 청킹 품질을 평가할 수 있는 5가지 핵심 지표(Noise Reduction, Completeness, Context Coherence, Task Relevance, Retrieval Performance)를 정의하여 기존 연구에서 부족했던 체계적 평가 프레임워크를 제시한다.
실험 결과, AutoChunker는 Support/Wikipedia 문서 모두에서 기존 방법 대비 현저히 높은 청킹 품질과 검색 성능을 보여주며, 실제 산업 환경에서도 고객 지원 성능 개선 및 제품 반품률 감소라는 실질적 효과를 증명한다.
Method
2.1 Bottom-up Intelligent Document Chunking
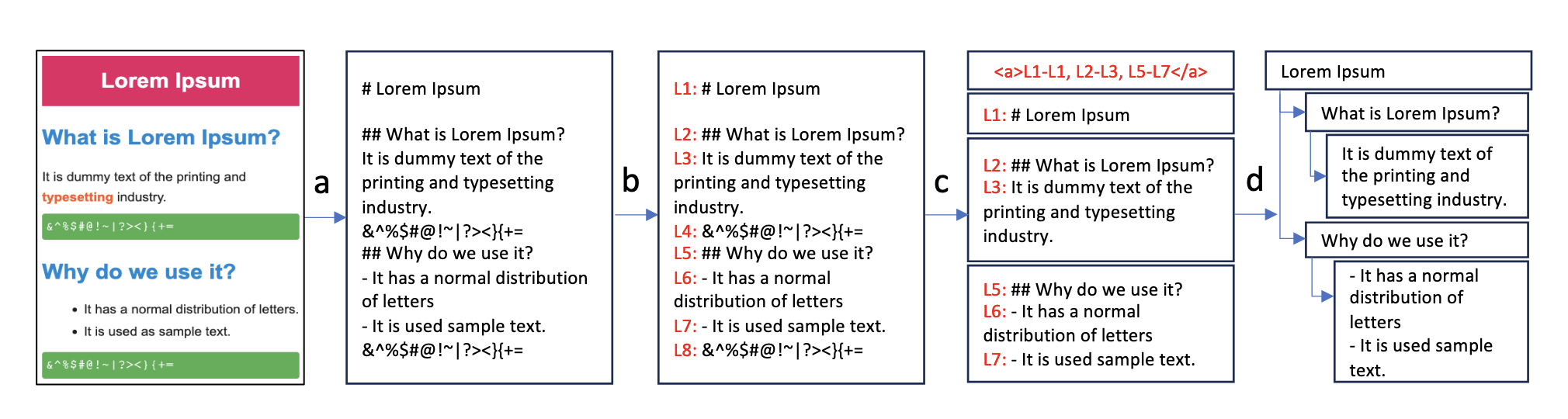
AutoChunker의 핵심은 문서 구조 보존 + 의미 단위 기반 병합 + 노이즈 제거이다.
문서 Markdown 변환
HTML 문서를 Markdown 형식으로 변환하여 제목/소제목 등의 구조 정보를 유지한다.
(논문 Figure 2a 참고)
최소 단위 분할
문서를 문장 단위로 쪼개 각 문장에 ID를 부여하고, 이를 청킹의 원자 단위로 사용한다.
LLM 기반 의미적 병합 및 노이즈 제거
LLM에 문장 리스트를 입력하여
-
어떤 문장 범위를 하나의 청크로 묶을지
-
어떤 문장은 노이즈로 제외할지
결정하도록 한다.
이때 LLM은 직접 텍스트를 생성하지 않고 문장 ID만을 출력함으로써 정보 손실을 방지한다.
(논문에서 제시된 Prompt 1 활용)
이 접근법은 기존 top-down 방식의 split-first 방식과 달리, 의미적 연속성이 보장된 단위부터 bottom-up으로 쌓아 올리는 방식이기 때문에 문서 구조를 자연스럽게 반영할 수 있다.
2.2 Hierarchical Tree Construction
청크가 생성된 후, Markdown의 구조적 정보(제목/소제목 등)를 활용하여 청크를 트리 구조로 정리한다.
이는 다음과 같은 장점을 제공한다:
문서의 계층적 의미 관계를 유지
검색 시 해당 청크의 부모/형제 문맥을 함께 고려 가능
너무 큰 청크는 분할하여 벡터 임베딩 최적화, 그러나 트리 구조로 관계 유지
이 단계는 RAG 시스템에서 Context-Aware Retrieval의 기반이 된다.
2.3 Context-Aware Retrieval (CAR)
검색 시스템은 각 청크의 벡터 임베딩을 비교한 뒤,
해당 청크를 루트로 하는 서브트리 전체를 검색 결과로 제시할 수 있다.
이는 기존 top-K chunk retrieval이 가지는 문맥 단절 문제를 완화한다.
또한 중복된 서브트리를 제거하고, 순위에 따라 flatten하여 결과를 구성함으로써
풍부한 컨텍스트를 제공하면서도 과잉 정보는 억제한다.
2.4 Evaluation Framework
저자들은 LLM judge 활용하여 다음 5가지 기준으로 청킹 품질을 평가한다:
-
Noise Reduction
-
Completeness (문맥적 완결성)
-
Context Coherence (내부 의미 연결성)
-
Task Relevance
-
Retrieval Performance (Weighted Precision@K 기반)
특히 Retrieval 평가를 위해 쿼리가 없는 상황에서는
LLM이 synthetic queries를 자동 생성하도록 설계했다.
Results
3.1 Chunking Quality
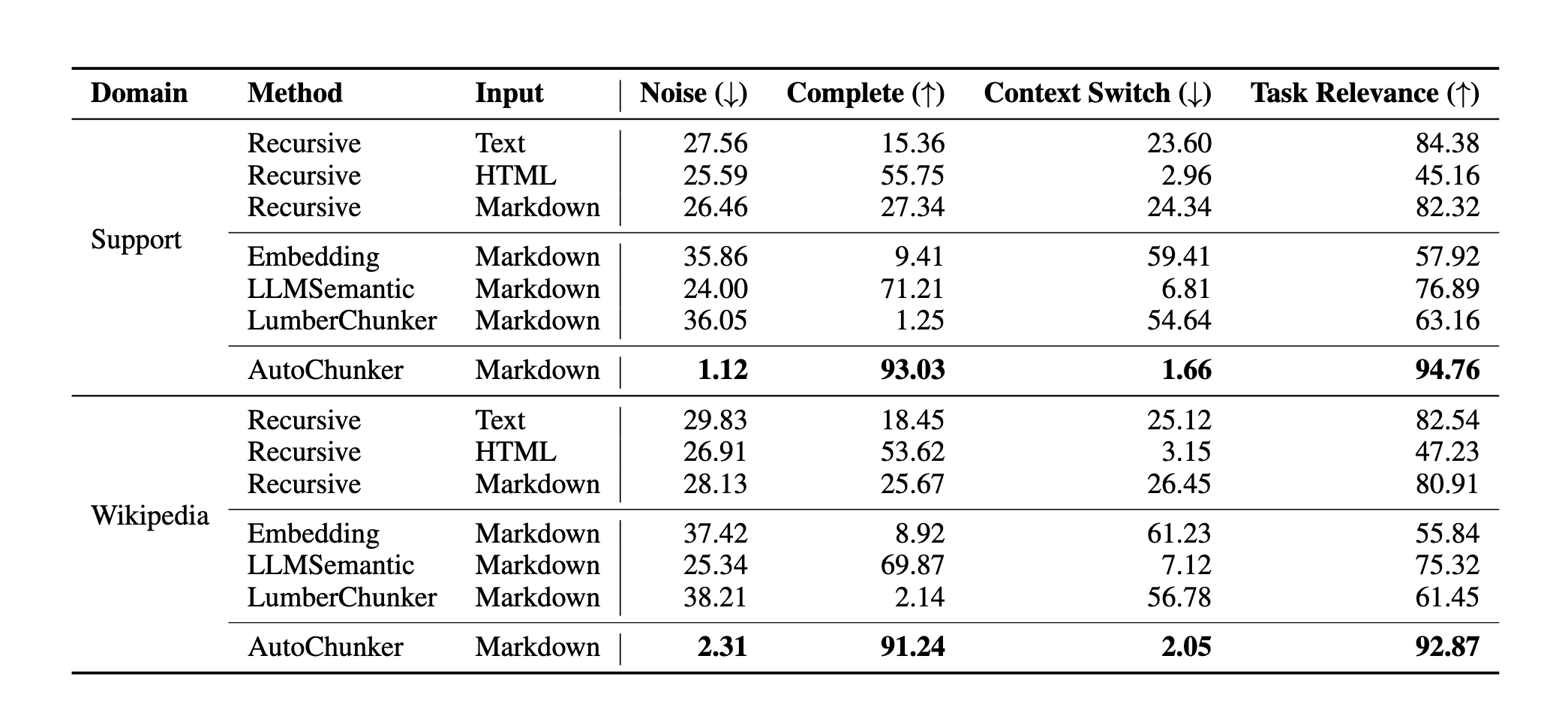
Table 2에 따르면 AutoChunker는 기존 모든 baseline을 크게 상회한다.
Noise: Support 도메인 기준 1.12% (기존은 24~36%)
Completeness: 93.03% (기존 최고 71.21%)
Context Switch: 1.66%로 최소
Task Relevance: 94.76% (기존 최고 84%)
즉 청크가
깨끗하고
논리적으로 완결되며
문맥 전환이 적고
downstream task에 유효
함을 종합적으로 입증했다.
3.2 Retrieval Performance
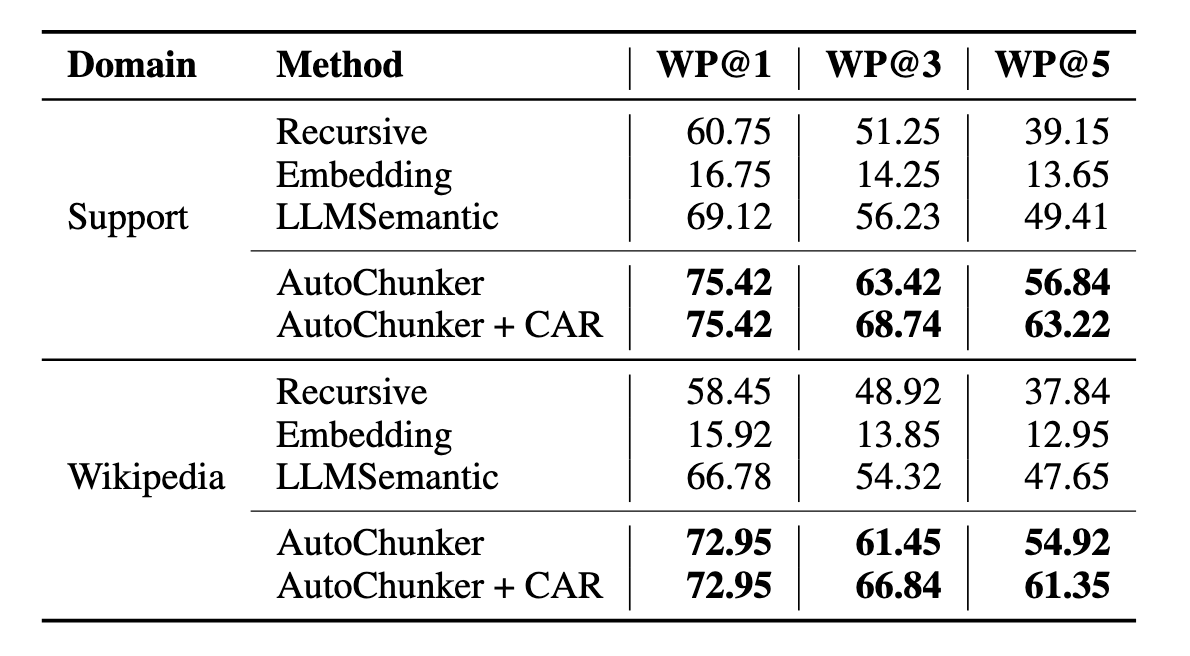
Table 3에서 AutoChunker는 WP@1, @3, @5 모두에서 가장 높은 성능을 보인다.
예: Support domain
WP@1: 75.42 (기존 LLMSemantic 69.12 대비 크게 우수)
CAR 적용 시 WP@5: 63.22로 추가 상승
이는 AutoChunker가
청크 자체의 품질 개선
트리 기반 컨텍스트 활용
을 동시에 달성했음을 보여준다.
3.3 Industry Impact
실제 전자제품 고객지원 시스템에 AutoChunker를 적용한 결과
retrieval precision 7% 향상
제품 반품률 6.5 bps 감소 (4주간)
