Abstract
현대 NLP 태스크는 관련된 문맥 정보를 검색하기위해 dense retrieval 방법에 의존하고 있다.
해당 연구는, 콘텐츠의 의미론적 독립성을 더 잘 포착할 수 있도록 크기가 다양할 수 있는 세그먼트에서 검색 이점을 얻을 수 있다는 전제에서 나왔다.
LLM을 활용하여 문서를 동적으로 분할하는 방법인 LumberChunker을 제안하였다. LLM이 시퀀스한 구절 그룹 내에서 콘텐츠가 이동하기 시작하는 지점을 식별하도록 반복적으로 프롬프팅한다.
또한 방법론을 평가하기 위해 GutenQA라고 하는 3000개의 QA 쌍으로 구성된 데이터셋을 소개한다.
해당 방법은 검색 성능(DCG@20)에서 가장 좋은 베이스라인보다 7.37% 더 뛰어난 성능을 발휘할 뿐만 아니라 RAG 파이프라인에 활용할 때LumberChunker가 Gemini 1.5M Pro와 같은 다른 청킹 방법 및 경쟁 기준보다 더 효과적인 결과를 보였다.
Introduction
LLM은 다양한 태스크에서 활용되고 있지만, 부족한 정보를 기반으로 응답을 생성할 때 주로 할루시가 발생한다.
정보의 정확성이 가장 중요한 QA 분야에서는 RAG가 상황에 맞는 문서를 기반으로 답변을 생성하도록 하여 할루시에 대한 솔루션을 제시한다.
하지만, RAG 파이프라인에서는 텍스트 콘텐츠가 청크로 분할되는 것이 검색 품질에 큰 영향을 미칠 수 있음을 간과한다.
본 논문에서는 콘텐츠의 청크가 서로 최대한 독립적일 때 검색 효율성이 향상된다는 원리에 기반하는 새로운 텍스트 분할 방법인 LumberChunker 방법을 제안한다.
의미적으로 독립된 부분으로 다양한 사이즈의 청크를 만드는 것은 좋은 성과를 가져올 수 있다.
특히 언어 모델은 텍스트 분석에 뛰어나기 때문에 이 케파를 활용한다.
구체적으로, 일련의 시퀀스한 단락을 주고 내용이 분기되기 시작하는 시퀀스 내에서 정확한 단락을 결정하도록 언어 모델에게 지시한다.
이 방법은 각 세그먼트가 문맥적으로 일관적이면서도 인접한 세그먼트와 구별되도록 보장하여 정보 검색의 효율성을 향상시킨다.
LumberChunker
제안하는 주요 기여는 LumberChunker라 불리는 새로운 document segmentation 기법이다. 이 방법은 LLM을 활용하여 문서를 동적으로 분할하고, 각각의 청크가 의미적으로 독립적인 단위가 되도록 만든다. 이 접근법은 검색은 크기가 유동적인 세그먼트를 통해 더 잘 작동하며, 그 결과 콘텐츠의 의미적 독립성이 더욱 정확하게 포착된다는 원리에 기반한다.
이러한 dynamically varying granularity 덕분에 각 청크는 하나의 완전하고 독립적인 아이디어를 담게 되고, 이는 검색 결과의 관련성과 명확성을 향상시킨다.
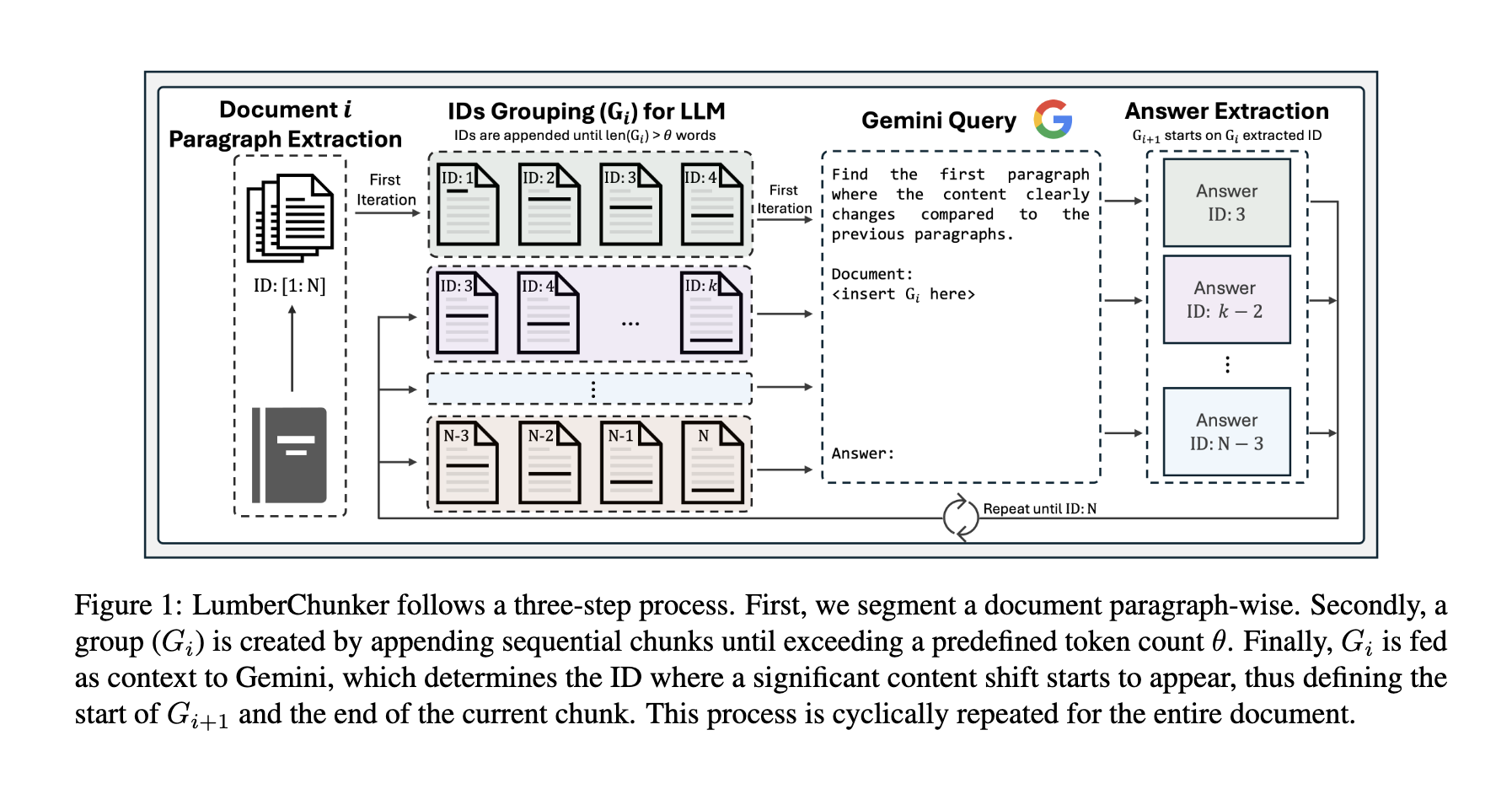
연속된 여러 단락들을 LLM에 입력함으로써, LumberChunker는 가장 적절한 분할 지점을 자동으로 결정한다. 이 결정 과정은 텍스트의 구조와 의미적 흐름을 모두 고려하여, 크기와 문맥의 일관성이 최적화된 청크를 생성할 수 있게 해준다. 그림 1은 LumberChunker의 전체 파이프라인을 나타낸 것이다.
먼저 대상 문서를 단락(paragraph) 단위로 나누며, 각 단락은 증가하는 ID 번호로 유일하게 식별된다. 이후 각 단락을 순서대로 이어붙여 그룹 Gi를 만들고, 그룹에 포함된 전체 토큰 수가 미리 정해둔 임계값 θ(세타)를 초과할 때까지 계속 추가한다. θ는 너무 짧게 설정해서 의미적으로 긴 단락이 둘로 쪼개지는 것을 방지하면서도, 동시에 너무 크게 설정하여 모델이 지나치게 긴 문맥 때문에 추론 능력이 떨어지지 않도록 신중하게 정해야 한다.
이렇게 구성된 그룹 Gi는 LLM(Gemini 1.0-Pro를 사용함)에 입력되고, LLM에게는 Gi 내부에서 이전 문맥과 의미적으로 뚜렷하게 달라지기 시작하는 단락을 찾도록 지시한다. 이 변화 지점이 하나의 청크가 끝나는 위치가 된다. 이후 문서는 이러한 과정을 반복하여 순차적으로 청크로 분할된다.
즉, 각 새 그룹 Gi+1의 시작 단락은 이전 단계에서 LLM이 찾아낸 단락이 된다.
Experiments
우리는 다양한 유형의 실험을 통해 LumberChunker를 평가하였다.
우리의 실험적 평가를 이끄는 핵심 질문들은 다음과 같다.
• 첫 번째 질문: 각 LumberChunker 프롬프트에서 목표 토큰 수의 최적 임계값은 무엇인가?
θ ∈ [450, 1000] 범위의 서로 다른 프롬프트 길이에 따라
LumberChunker의 DCG@k 및 Recall@k 점수가 어떻게 변화하는지 분석한다.
• 두 번째 질문: LumberChunker는 검색 성능을 향상시키는가?
LumberChunker가 문서 내에서 아주 특정한 세부 정보를 찾아내는 능력을 평가하기 위해,
우리는 GutenQA에서 구성한 질문들을 통해 테스트한다.
또한, 그 성능(DCG@k, Recall@k)을
Semantic chunking, Proposition-level chunking 등 기존 베이스라인 방법들과 비교한다.
• 세 번째 질문: LumberChunker로 만든 청크는 생성 품질(Generation Quality)을 향상시키는가?
LumberChunker를 사용하면 문서 분할 과정이 복잡해지고 계산 비용이 증가하므로,
이 비용이 실제로 가치가 있는가?라는 질문이 제기된다.
이를 검증하기 위해, 우리는 QA 태스크에서
LumberChunker 청크가 생성 성능을 향상시키는지 평가한다.
이를 위해 LumberChunker의 청크를 RAG 파이프라인에 통합하고,
4개의 자서전적 내러티브를 기반으로 한 280개의 소규모 QA 테스트셋을 구축했다.
(이 구성은 본 논문의 주요 논점 밖이므로 자세한 내용은 Appendix E에 제공)
다음과 같은 RAG 파이프라인 변형들과 성능을 비교한다:
- 다른 청킹 기법을 활용한 RAG 버전들
- 수동으로 만든 청크(manually created chunks)
→ 이를 최적 검색의 gold standard로 간주함
또한 RAG를 사용하지 않는 베이스라인도 포함한다:
- Gemini 1.5 Pro (최대 150만 토큰 입력 가능)
- Closed-book 셋업 (문서 컨텍스트 없이, 내부 지식만 사용)
Context Size
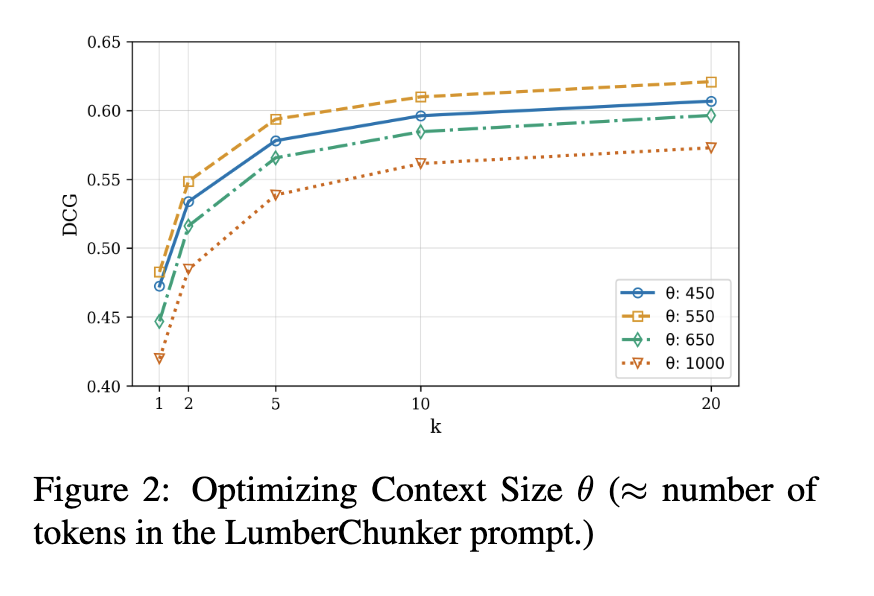
그림 2는 여러 임계값(threshold) 중 θ = 550이 가장 우수한 성능을 보이며, 시험한 모든 k 값에서 가장 높은 DCG@k 점수를 기록함을 보여준다.
이는 약 550 토큰으로 구성된 프롬프트가 문맥 포착 능력과 청크 길이의 균형을 가장 잘 맞춰, 문서 검색 품질을 최적화한다는 것을 의미한다.
그다음으로 θ = 450과 θ = 650도 비슷하게 좋은 성능을 보였으나, θ = 550만큼의 최적 균형에는 미치지 못한다.
반면, θ = 1000은 가장 낮은 성능을 기록했다.
이 과업은 고도의 추론 능력을 요구하기 때문에, 너무 긴 프롬프트는 모델이 관련 정보에 집중하는 데 방해가 되어 성능 저하를 유발할 수 있다.
Main Results
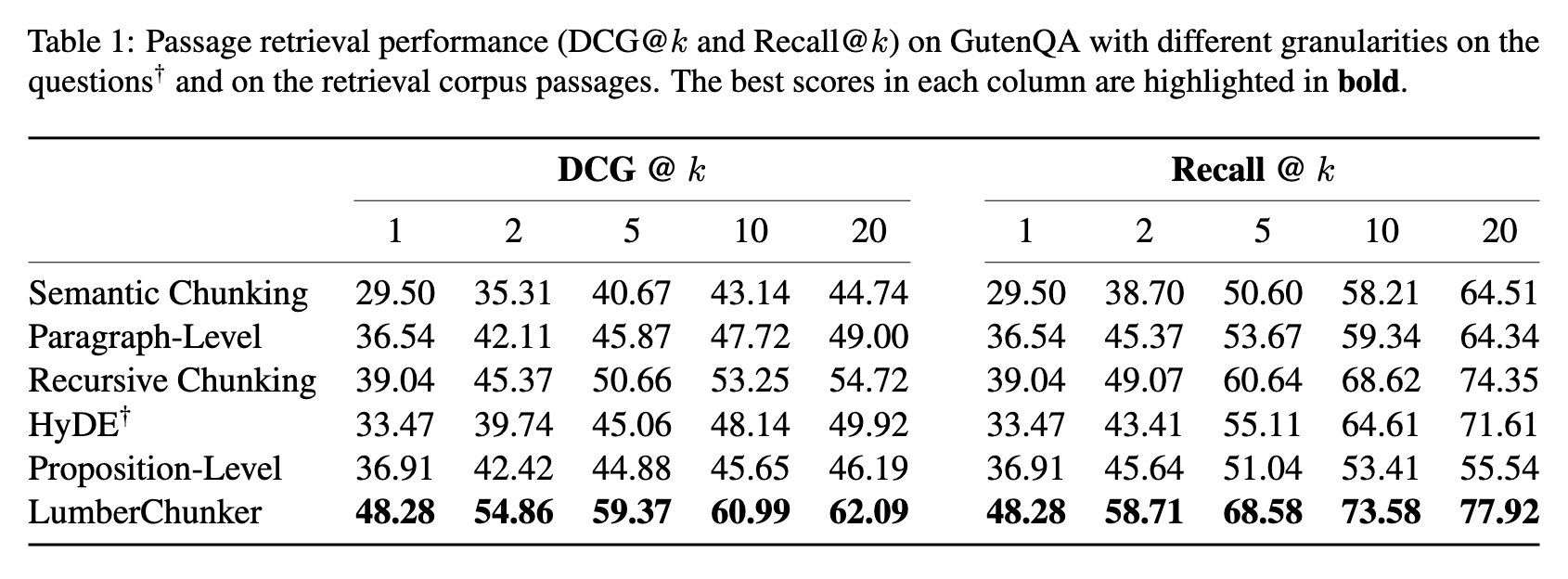
표 1의 결과에 따르면, 모든 k 값에서 LumberChunker는 DCG@k와 Recall@k 지표 모두에서 모든 베이스라인을 지속적으로 능가한다.
특히 k = 20에서 두드러지는데,
LumberChunker DCG@20 = 62.09
가장 성능이 비슷한 경쟁 baseline(Recursive chunking) = 54.72
또한 Recall@k에서도:
LumberChunker Recall@20 = 77.92
Recursive Chunking = 74.35
베이스라인을 자세히 보면,
Paragraph-level 및 Semantic chunking은 k가 커질수록 성능이 제대로 유지되지 못함. 많은 문서를 반환할 때 관련성을 유지하는 데 취약하다는 의미
HyDE는 Recursive chunking을 기반으로 하지만 모든 k 값에서 기본 Recursive chunking보다 성능이 떨어짐. HyDE의 추가 생성(augmentation) 단계가 이 작업에는 적합하지 않다는 것을 시사함
또 하나 주목해야 할 점은 Proposition-Level chunking의 성능이 매우 낮다는 것이다.
이 방법은 Wikipedia처럼 사실 기반(fact-based) 자료에는 강점이 있지만,
이번 실험처럼 이야기 구조와 문맥적 흐름이 중요한 내러티브 텍스트에서는 효과적이지 못하다.
Impact on QA Systems
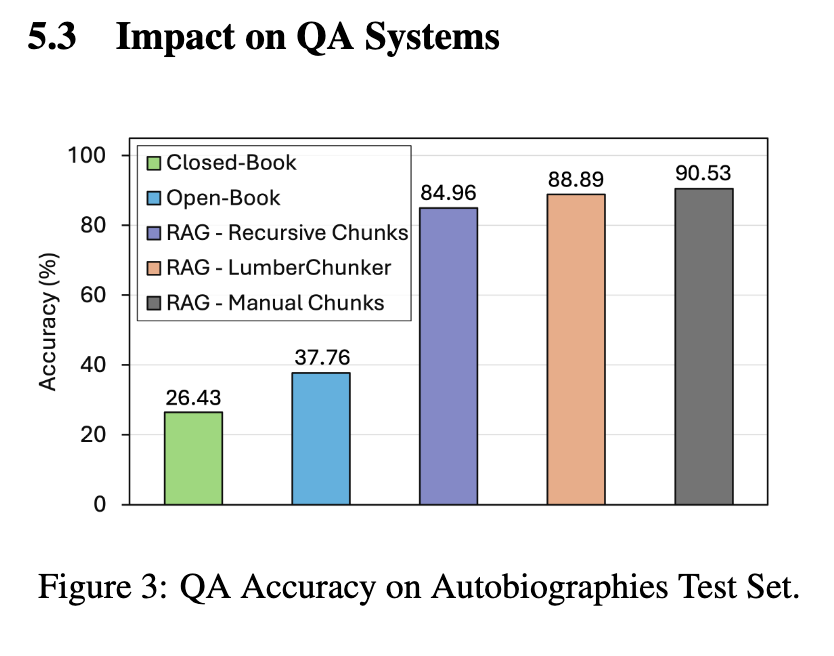
그림 3은 여러 자서전 텍스트에 대해 다양한 QA 접근법의 성능을 비교한 것이다.
여기서 특히 주목할 점은 LumberChunker를 RAG 파이프라인에 통합했을 때, 대부분의 베이스라인보다 더 높은 평균 정확도를 기록했다.
검색 실험에서 가장 경쟁력이 있었던 Recursive chunking마저 QA 성능에서는 LumberChunker에 밀림. 이는 향상된 검색 품질이 QA 정확도 개선으로 이어진다는 점을 강화하는 결과이다.
단 하나 LumberChunker가 뒤처진 경우는 수동(manual)으로 작성된 청크를 사용하는 RAG. 이는 ‘최적 검색(gold standard)’이므로 자연스러운 결과이다.
