MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System
Paper Review
Introduction
RAG(Retrieval-Augmented Generation) 시스템에서 텍스트 청킹은 가장 기본적인 전처리 단계임에도 불구하고, 실제로는 큰 주목을 받지 못해왔다. 대부분의 시스템은 고정 길이 기반 혹은 임베딩 유사도 기반 청킹을 사용하며, 청킹의 품질은 downstream 태스크 성능을 통해 간접적으로만 평가된다.
본 논문은 이러한 관행에 문제를 제기한다. 저자들은 “좋은 청킹이란 무엇인가?”라는 질문을 명시적으로 던지고, 청킹 품질을 독립적으로 평가할 수 있는 지표와 효율적인 청킹 프레임워크를 함께 제안한다.
Motivation
기존 텍스트 청킹 방식에는 두 가지 근본적인 한계가 있다.
첫째, 청킹 품질을 직접 평가할 수 있는 기준이 없다. 대부분의 연구는 RAG QA 정확도와 같은 downstream 성능으로만 청킹을 비교한다. 이 방식은 청킹 자체의 구조적·의미적 적절성을 설명하지 못한다.
둘째, LLM 기반 청킹과 경량 청킹 간의 트레이드오프 문제이다. LLM 기반 방식은 문서 구조를 잘 반영하지만 비용과 지연 시간이 크고, 반대로 규칙 기반이나 임베딩 기반 방식은 효율적이지만 의미 단위 분리에 취약하다.
본 논문은 이 두 문제를 동시에 해결하려는 시도로 볼 수 있다.
Chunking Quality Metrics
논문의 가장 핵심적인 기여는 텍스트 청킹 품질을 직접 측정하기 위한 두 가지 지표를 제안한 점이다.
Boundary Clarity
Boundary Clarity는 서로 다른 청크 사이의 의미적 독립성을 측정하는 지표이다. 이상적인 청킹에서는 각 청크가 독립적인 의미 단위를 이루며, 인접 청크 간 정보 중첩이 최소화되어야 한다.
논문에서는 언어 모델의 perplexity 변화를 활용해 경계의 명확성을 정량화한다. 경계가 명확할수록, 청크 간 전이에서 모델의 불확실성이 증가하는 경향을 보인다.
Chunk Stickiness
Chunk Stickiness는 하나의 청크 내부에서 문장들이 얼마나 강하게 연결되어 있는지를 측정한다. 단순히 문장을 나누는 것이 아니라, 의미적으로 응집된 단위를 형성하는지가 중요하다는 관점이다.
이를 위해 저자들은 의미 관계 그래프를 구성하고, 해당 그래프의 구조적 엔트로피를 통해 내부 응집도를 평가한다.
이 두 지표는 기존의 downstream 기반 평가와 달리, 청킹 자체를 독립적인 분석 대상으로 다룰 수 있게 해준다.
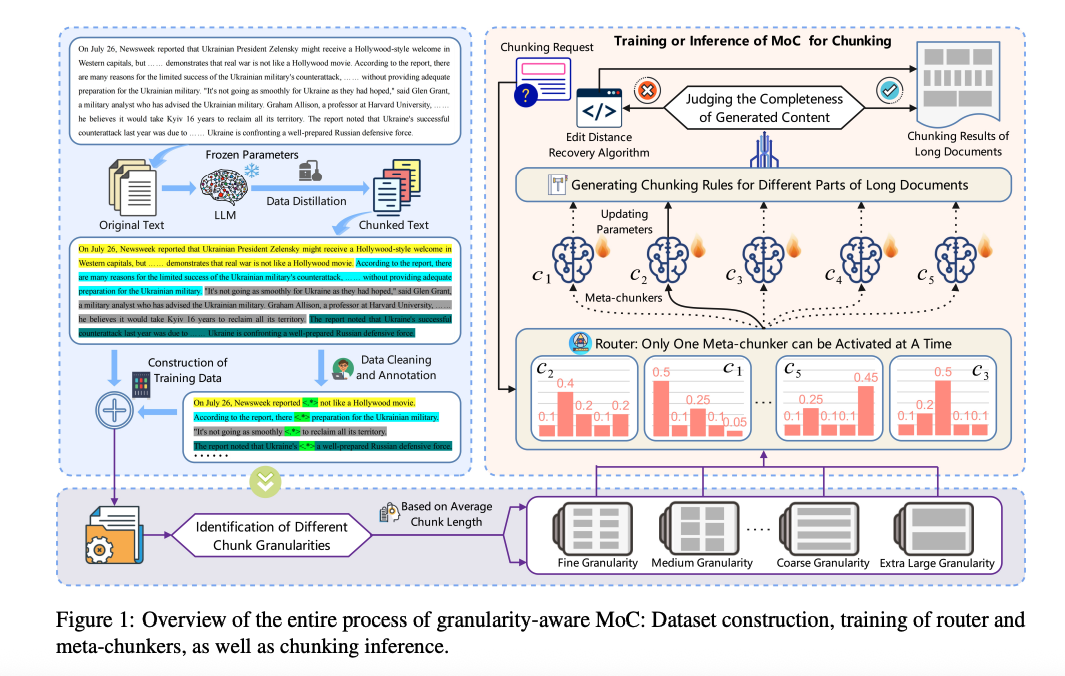
Mixture-of-Chunkers (MoC)
두 번째 핵심 기여는 Mixture-of-Chunkers(MoC) 프레임워크이다. 이는 하나의 청킹 모델이 모든 문서를 처리하는 방식이 아니라, 여러 개의 청킹 전문가 모델을 상황에 따라 선택적으로 사용하는 구조이다.
MoC는 크게 세 가지 구성 요소로 이루어진다.
-
Router
입력 텍스트의 특성을 분석하여 어떤 청킹 전문가를 사용할지 결정한다. -
Meta-Chunker Experts
각 전문가는 특정 수준의 granularity나 구조적 특징에 특화된 청킹을 수행한다. -
Regex-based Extraction
각 전문가 모델은 정규식 형태로 청크 경계를 출력하며, 이를 통해 실제 텍스트 분할이 이루어진다.
이 구조는 mixture-of-experts 개념을 청킹 문제에 적용한 사례로 볼 수 있으며, 필요할 때만 특정 전문가를 활성화함으로써 효율성을 유지한다.
Experiments
실험에서는 다양한 기존 청킹 방식(고정 길이, 임베딩 기반, LLM 기반)과 MoC를 비교한다.
결과적으로 MoC 기반 청킹은 Boundary Clarity와 Chunk Stickiness 두 지표 모두에서 더 우수한 성능을 보였다. 또한 이러한 청킹 품질 향상이 RAG downstream 성능 개선으로도 이어지는 경향을 확인할 수 있다.
중요한 점은, 본 논문이 단순히 “RAG 성능이 좋아졌다”에 그치지 않고, 왜 좋은지를 청킹 품질 지표로 설명하려 했다는 점이다.
Discussion
이 논문의 의의는 텍스트 청킹을 더 이상 단순한 전처리 단계로 취급하지 않고, 명확한 평가 대상이자 설계 대상으로 끌어올렸다는 데 있다.
특히 Boundary Clarity와 Chunk Stickiness는 향후 청킹 연구에서 일반적으로 활용될 수 있는 지표로 보인다. 또한 MoC 구조는 실제 시스템에서 품질과 효율 사이의 균형을 맞추는 하나의 실용적인 방향을 제시한다.
다만, 라우터와 다수의 전문가 모델을 운용하는 구조가 실제 서비스 환경에서 어느 정도의 복잡도와 비용을 요구하는지는 추가적인 검증이 필요해 보인다.
Conclusion
본 논문은 RAG 시스템에서 오랫동안 암묵적으로 사용되던 텍스트 청킹 문제를 명시적으로 정의하고, 평가 지표와 아키텍처를 함께 제안했다는 점에서 의미가 크다.
청킹 품질을 정량적으로 분석하고 싶은 경우, 혹은 RAG 파이프라인을 구조적으로 개선하고자 하는 경우 참고할 만한 연구라고 생각된다.
