Benchmarking Retrieval-Augmented Multimodal Generation for Document Question Answering
Paper Review

이 논문은 문서 질의응답(DocVQA) 분야에서 시각적 정보와 텍스트 정보를 모두 활용하는 Retrieval-Augmented Multimodal Generation을 위한 새로운 벤치마크인 MMDocRAG를 소개한다. MMDocRAG는 긴 다중 모달 문서에서 복잡한 교차 모달 추론을 수행하고 관련 증거를 선택하며, 텍스트와 시각적 요소가 혼합된 답변을 생성하는 모델의 능력을 평가하는 데 중점을 둔다.

서론
문서 시각 질의응답(DocVQA)은 금융 보고서, 기술 매뉴얼, 의료 기록과 같은 다중 모달 문서에서 질문에 답하는 데 초점을 맞춘다. 이러한 문서는 길이가 길어 핵심 증거를 식별하기 어렵고, 이미지, 테이블, 차트, 레이아웃 구조 등 다양한 모달리티에 걸쳐 복잡한 추론을 요구한다. 최근에는 문서의 관련 페이지를 검색한 후 이를 바탕으로 답변을 생성하는 문서 검색-증강 생성(DocRAG) 방법이 도입되었다. 그러나 기존 DocRAG 시스템은 텍스트 중심적인 접근 방식으로 인해 차트나 테이블과 같은 중요한 시각 정보를 간과하는 단점을 가진다. 또한, 기존 벤치마크들은 주로 검색된 텍스트의 재현율이나 텍스트 답변의 품질 평가에 초점을 맞추어, 노이즈가 포함된 검색 결과에서 관련 다중 모달 증거를 선택하고 이를 응집력 있게 통합하는 모델의 능력을 평가하는 데는 한계가 있다.
이러한 문제에 대응하여, 이 논문은 포괄적인 다중 모달 문서 질의응답 벤치마크인 MMDocRAG를 제안한다. MMDocRAG는 4,055개의 전문가 주석이 달린 질문-답변 쌍으로 구성되며, 각 쌍은 여러 페이지와 모달리티에 걸친 다중 모달 증거 사슬을 포함한다. 이 벤치마크는 다중 모달 인용문 선택을 위한 혁신적인 측정 지표와 텍스트와 관련 시각적 요소를 교차 배치하는 답변 형식을 도입하여 모델의 시각 정보 활용 능력을 평가한다. 60개의 VLM/LLM 모델과 14개의 검색 시스템을 사용한 대규모 실험을 통해, 이 논문은 다중 모달 증거 검색, 선택 및 통합에서 지속적인 도전 과제를 식별한다. 주요 발견으로는 고급 독점 VLM이 오픈소스 대안보다 우수한 성능을 보이며, 다중 모달 입력을 사용할 때 텍스트 전용 입력에 비해 중간 정도의 이점을 얻는 반면, 오픈소스 대안은 성능 저하를 보인다는 점이다. 또한, 파인튜닝된 VLM/LLM이 다중 모달 생성에서 상당한 성능 향상을 이룬다는 점을 확인한다.
MMDocRAG 벤치마크
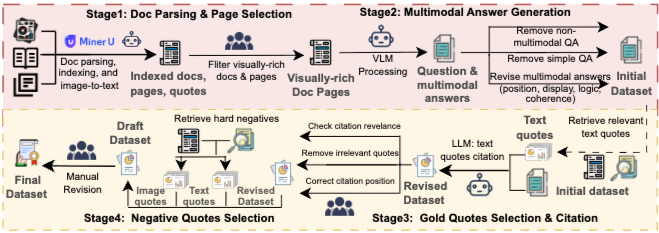
MMDocRAG 벤치마크는 질문-답변 쌍, 페이지 및 인용 증거, 노이즈 인용문, 다중 모달 답변을 포함하는 주석을 제공한다. 데이터셋 구축은 네 단계의 주석 파이프라인(Figure 3)을 따른다.
-
문서 구문 분석 및 페이지 선택 (Doc Parsing & Page Selection): MMDocIR 데이터셋 [19]의 문서 코퍼스를 활용한다. MinerU [77]를 사용하여 LayoutLMv3 [32] 기반으로 페이지 레이아웃을 감지하고, 본문 텍스트, 제목, 수식, 그림, 테이블 등으로 분류한다. 각 식별된 레이아웃은 내용 인식 청크, 즉 "인용문(quote)"으로 사용된다. 텍스트 인용문은 텍스트 형식으로 저장되며, 이미지 인용문(테이블 또는 그림)의 경우 OCR [71]을 사용하여 텍스트를 추출하고 VLM [55, 60]을 사용하여 상세 설명을 생성한다. 결과적으로 각 이미지 인용문은 원본 이미지, OCR-text, VLM-text의 세 가지 형식으로 저장된다. 이후 시각적으로 풍부한 고품질 페이지 2,373개를 선별한다.
-
다중 모달 답변 생성 (Multimodal Answer Generation):
- 기존 QA 쌍: MMDocIR 데이터셋의 1,658개 QA 쌍 중 다중 모달 답변 생성에 적합한 943개 질문을 선정한다. 이 질문들과 텍스트 답변을 GPT-4o [55]에 입력하여 초안 다중 모달 답변을 생성한다. 시각적 내용이 없거나 너무 간단한 QA 쌍은 제거하고, 다중 모달 콘텐츠의 위치, 형식, 응집력을 수정하여 821개 QA 쌍을 확보한다.
- 신규 QA 쌍: VLM이 증거를 기반으로 질문과 텍스트 답변을 자율적으로 생성한다. 서술형(descriptive), 비교형(comparative), 절차형(procedural), 해석형(interpretative), 인과형(causal), 분석형(analytical), 추론형(inferential), 응용 기반형(application-based)의 8가지 질문 유형을 정의한다. 단일 또는 다중 문서 페이지를 입력으로 사용하여 난이도를 높인다. 결과적으로 1,719개의 단일 페이지 및 1,630개의 다중 페이지 질문이 생성된다.
-
Gold Quote 인용 (Gold Quotes Citation): 답변의 환각(hallucination)을 줄이고 추적 가능성을 높이기 위해, 답변 내에서 gold quote를 명시적으로 인용한다. 이미지 인용문은
형식으로, 텍스트 인용문은[i]형식으로 인용한다. 밀집 검색기(dense retriever)를 사용하여 상위 20개의 관련 텍스트 인용문을 식별하고, LLM이 문맥적으로 가장 관련 있는 증거를 선택하여 적절한 위치에 인용문을 삽입한다. 전문가 평가자가 인용 품질을 검증하여 2,457개의 답변에 걸쳐 총 4,641개의 텍스트 인용문이 수정된다. -
Negative Quote 증강 (Negative Quotes Augmentation): 작업 난이도를 높이기 위해 질문이나 답변과 텍스트적/시각적으로 유사하지만 관련 없는 "hard negative" 인용문을 gold quote와 섞어 컨텍스트에 추가한다. 각 질문에 대해 15개(이미지 5개, 텍스트 10개) 또는 20개(이미지 8개, 텍스트 12개)의 후보 세트를 생성한다.
데이터셋 분석:
MMDocRAG 벤치마크는 총 4,055개의 질문으로 구성되며, 개발/평가 세트로 각각 2,055개/2,000개로 분할된다. 질문들은 평균 67페이지, 약 33k 단어의 길고 복잡한 222개의 문서에서 파생되었다. 전체 질문의 52.0%가 교차 페이지(2개 이상 페이지에서 증거 필요), 39.2%가 다중 이미지(2개 이상 이미지 인용문 포함), 61.7%가 교차 모달(여러 증거 모달리티 필요) 질문이다. 질문 유형은 비교형(35.9%), 서술형(31.0%), 해석형(17.2%), 분석형(12.0%), 추론형(1.8%) 등으로 구성된다. 증거 모달리티는 텍스트(60.1%), 테이블(66.0%), 그림(24.8%), 차트(15.9%)를 포함한다. 총 48,618개의 텍스트 인용문(4,640개 gold)과 32,071개의 이미지 인용문(6,349개 gold)이 포함된다. 평균적으로 각 질문은 15/20개 후보 중 2.7개의 gold quote(18.0%/13.5% 관련)와 연관된다. VLM-text는 OCR-text보다 훨씬 길고 상세하다. 답변 길이는 짧은 답변이 평균 23.9 토큰, 다중 모달 답변이 평균 221.0 토큰이다.
품질 보증 (Quality Assurance):
MMDocRAG의 품질을 보증하기 위해 초안 주석의 반자동 검증과 최종 주석의 수동 교차 검증을 병행한다. 문서 페이지 선택에서는 레이아웃 감지 모델로 시각적 콘텐츠가 풍부한 페이지를 식별한 후 전문가 주석자가 검토한다. 인용문 통합 및 다중 모달 답변 생성에서는 VLM으로 관련 시각적 콘텐츠를 선택 및 삽입하고, LLM으로 통합된 텍스트의 정확성과 일관성을 확인한다. 답변이 유효성 검사를 통과하지 못하면 최대 3회 재구성한다. 초안 주석을 두 부분으로 나누어(각각 약 2,300개 QA 쌍), 500개 겹치는 쌍을 검증 지점으로 사용하여 두 주석 그룹 간의 품질을 상호 검증한다.
작업 정의
문서 검색-증강 다중 모달 생성은 사용자 질문과 대상 문서 코퍼스를 기반으로 다중 모달 답변을 생성하는 것을 목표로 한다. 이 작업은 두 가지 주요 단계로 구성된다.
-
다중 모달 검색 (Multimodal Retrieval): 문서 구문 분석을 통해 추출된 텍스트 인용문 과 이미지 인용문 으로 구성된 문서 코퍼스에서, 질의 와 가장 관련 있는 인용문들의 부분 집합을 검색한다. 이는 유사도 점수 및 를 기준으로 순위를 매겨 상위 개()의 인용문을 후보 증거로 선택한다.
-
다중 모달 답변 생성 (Multimodal Answer Generation): 다양한 문서 구문 분석, 청크 전략 또는 검색 모델의 결과가 달라 답변 생성 평가의 공정성을 해칠 수 있으므로, 고정된 후보 인용문 세트를 입력 컨텍스트로 사용하여 LLM/VLM의 인용문 선택 및 답변 생성 능력만을 평가한다. 구체적으로, 컨텍스트로 15개() 또는 20개()의 후보 인용문을 사용한다. 사용자 질문 와 주어진 인용문 컨텍스트 및 을 바탕으로 모델은 다중 모달 답변 를 생성해야 하며, 관련 없는(노이즈) 인용문은 제외되어야 한다. MMDocRAG는 다중 모달 콘텐츠를 처음부터 생성하는 것이 아니라, 주어진 및 에서 콘텐츠를 선택하고 통합하는 작업을 수행한다.
실험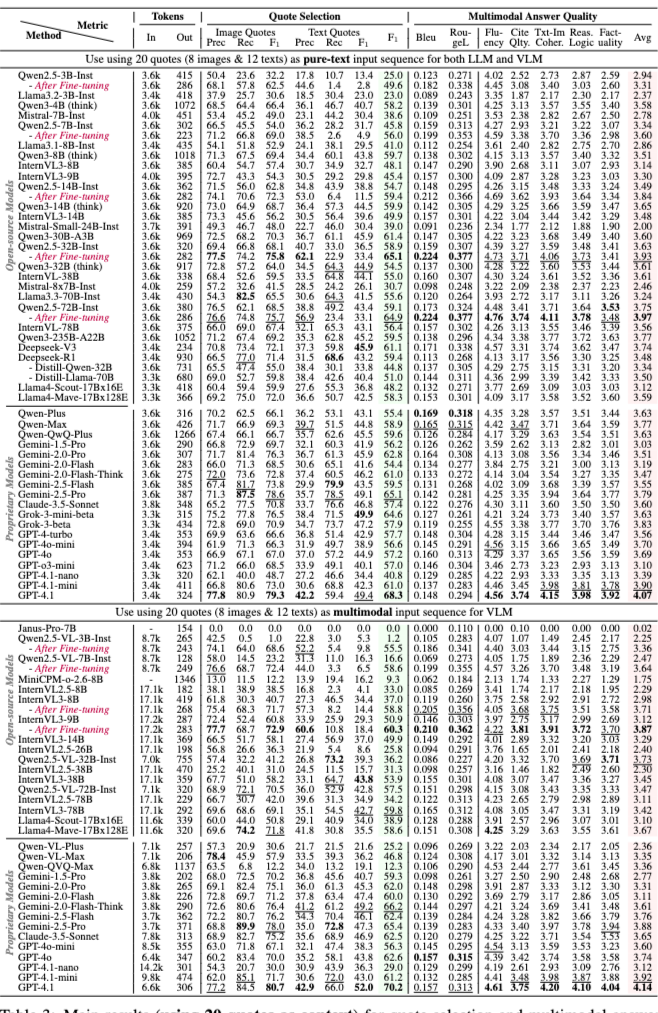
평가 지표:
- 다중 모달 검색 (Multimodal Retrieval): 검색된 gold quote 증거의 비율을 계산하는 recall@k를 사용한다.
- 다중 모달 답변 생성 (Multimodal Answer Generation): 인용문 선택 정확도, 표면 수준 답변 유사성, 정성적 답변 품질을 포괄하는 자동 및 LLM-as-judge 측정 지표를 조합한다.
- Quotes Selection: 예측된 인용문 집합 와 실제 인용문 집합 를 기준으로 Precision, Recall, F1 점수를 계산한다.
모델 답변에서 텍스트([i]) 및 이미지() 인용문 패턴을 정규 표현식으로 추출한다. 텍스트 및 이미지 인용문에 대해 F1을 개별적으로 계산한 후 평균하여 전체 인용문 선택 F1을 도출한다. - Surface-level Similarity: 생성된 답변이 참조 답변과 얼마나 유사한지 평가하기 위해 BLEU [59]와 ROUGE-L [42]을 사용한다.
- BLEU는 생성된 텍스트 와 참조 텍스트 간의 n-gram 중복을 계산한다.
여기서 은 n-gram의 수정된 정밀도, 은 각 n에 대한 가중치, 는 길이 불일치를 보정하는 간결성 페널티이다. - ROUGE-L은 생성된 답변과 참조 답변 간의 최장 공통 부분열(LCS)에 초점을 맞춘다.
여기서 와 는 LCS 길이에 기반한 재현율과 정밀도이며, 는 생성된 답변 또는 참조 답변의 길이를 나타낸다. 는 일반적으로 재현율을 선호하도록 설정된다( 기본값).
- BLEU는 생성된 텍스트 와 참조 텍스트 간의 n-gram 중복을 계산한다.
- LLM-as-Judge Criteria: LLM을 사용하여 유창성(Fluency), 인용 품질(Citation Quality), 텍스트-이미지 응집력(Text-Image Coherence), 추론 논리(Reasoning Logic), 사실성(Factuality)의 다섯 가지 측면에서 생성된 답변을 0-5점 척도로 평가한다.
- Quotes Selection: 예측된 인용문 집합 와 실제 인용문 집합 를 기준으로 Precision, Recall, F1 점수를 계산한다.
기준 모델:
- Quotes Retrieval: 6개의 텍스트 검색기, 4개의 시각적 검색기, 그리고 이들을 조합한 하이브리드 검색기를 평가한다.
- Multimodal Answer Generation: 60개의 최신 모델(33개의 VLM, 27개의 LLM)을 평가한다. LLM의 경우, OCR [71] 도구를 사용하여 이미지에서 텍스트를 추출하거나 VLM [55, 60]을 사용하여 상세 이미지 설명을 생성한다. 입력 인용문의 수는 15개 또는 20개로 고정한다. 또한, MMDocRAG 개발 세트를 사용하여 파인튜닝된 9개 모델(Qwen2.5 LLM, Qwen2.5-VL VLM, InternVL-3 VLM)을 평가한다.
주요 결과:
- Quote Selection (20개 인용문 기준): GPT-4.1이 70.2%의 가장 높은 F1 점수를 달성했으며, 다른 주요 독점 모델은 60%에서 66% 사이의 점수를 보인다. 반면, 소형 독점 모델 및 오픈소스 모델은 20%에서 60% 사이의 F1 점수를 보여 개선의 여지가 크다.
- Answer Quality (20개 인용문 기준): GPT-4.1이 4.14점으로 가장 높은 점수를 얻었으며, 다른 독점 모델은 3.6에서 4.0 사이의 점수를 보인다. 대부분의 소형 독점 모델 및 오픈소스 모델은 3.0에서 3.6 사이의 점수를 기록하며, 주로 인용, 추론, 사실성 오류가 원인이다.
- Multimodal vs Pure-text Quotes: 독점 VLM은 다중 모달 입력을 사용할 때 일반적으로 순수 텍스트 입력보다 성능이 우수하거나 비슷하지만, 상당한 계산 오버헤드와 지연 시간을 수반한다. 반면, 소형 VLM은 다중 모달 설정에서 인용문 선택과 답변 생성 모두에서 어려움을 겪는다. Qwen 모델은 순수 텍스트 입력에서 더 나은 성능을 보인다.
- Thinking 모델: 사고(thinking) 모델은 3배 더 많은 출력 토큰을 사용함에도 불구하고 성능이 크게 향상되지 않는다. 이는 다중 모달 인용문 선택 및 통합에 대한 단계별 추론이 최종 답변 생성에 큰 도움이 되지 않음을 시사한다.
- 파인튜닝 (Fine-tuning): 파인튜닝은 다중 모달 정보 선택 및 생성 성능을 크게 향상시킨다.
- 세분화된 분석: 모델 성능은 문서 복잡성("Workshop" 문서가 가장 쉬웠고, "Brochure" 문서가 가장 어려웠다), 질문 추론 요구 사항("Descriptive" 질문이 "Interpretative" 질문보다 성능이 좋았다), 증거 구조(단일 이미지/페이지 증거가 다중 이미지/페이지 시나리오보다 지속적으로 우수했다)에 따라 크게 달라진다.
Multimodal Quotes as text: VLM-text vs OCR-text:
VLM-text를 활용하는 모델은 OCR-text를 사용하는 모델보다 이미지 인용문 선택과 다중 모달 답변 생성 모두에서 훨씬 뛰어난 성능을 보인다. 이는 VLM-text가 OCR 도구로 추출된 원시 텍스트보다 더 풍부한 다중 모달 정보를 보존함을 시사한다. VLM-text는 테이블의 경우 0.5배, 그림의 경우 2.8배 더 길다.
Quotes Selection Analysis:
gold quote와 노이즈 quote가 무작위로 혼합되어 있지만, 모델은 인용문의 위치에 따라 선택 정확도에서 편향을 보인다. 특히 이미지 기반 gold quote는 초반 위치에 있을 때 선택될 가능성이 가장 높으며, 인용문이 시퀀스 뒤로 갈수록 선택 정확도는 감소한다.
Quotes Retrieval Results:
시각적 검색기는 이미지 검색에서 텍스트 검색기보다 우수하지만, 텍스트 검색에서는 뒤처진다. 하이브리드 검색은 두 가지 유형의 검색기 강점을 활용한다. 긴 문서에서 효과적인 인용문 검색은 여전히 어려운 과제로 남아있다.
End-to-end Multimodal RAG Analysis:
검색 재현율과 하위 작업 성능 사이에 명확한 양의 상관관계가 존재한다. 검색 재현율이 100%에서 71.0%로 떨어지면, GPT-4.1의 인용문 선택 F1은 70.2%에서 54.4%로 감소하고, 답변 품질은 4.14점에서 3.53점으로 떨어진다. 질의 확장(query expansion)은 다중 절(multi-clause) 질의를 통해 검색 재현율을 일관되게 향상시켜 더 나은 생성 성능으로 이어진다. 다중 검색기 앙상블 접근 방식은 단일 검색기보다 훨씬 높은 재현율(84.9%)을 달성하여, 완벽한 검색과의 성능 격차를 줄인다. 선도적인 모델조차도 현실적인 검색 조건에서 약 10%의 성능 저하를 겪으며, 이는 종단간 다중 모달 RAG의 지속적인 어려움을 보여준다.
관련 연구
이 논문은 인터리브드 텍스트-이미지 생성(Interleaved Text-Image Generation)에 대한 최근 연구(diffusion models와 LLM 결합, autoregressive frameworks 내에서 이미지 처리)를 검토한다. 또한, 멀티모달 RAG(MRAG)와 기존 벤치마크들을 언급하며, DocVQA의 초기 단일 페이지 VQA 벤치마크(DocVQA, InfoVQA, TAT-DQA)에서부터 컨텍스트 길이를 확장한 DUDE, MP-DocVQA, SlideVQA, 그리고 긴 컨텍스트 태스크로서 전체 문서를 입력으로 사용하는 MMLongBench-Doc 및 DocBench까지의 발전을 추적한다. DocRAG 작업은 M3DocVQA, M-Longdoc, MMDocIR에서 증거 검색과 답변 생성을 포함한다. 이 논문은 기존 DocVQA 또는 DocRAG 벤치마크 중 다중 모달 인터리브드 생성을 중점적으로 다루는 것은 없다고 지적한다.
결론
이 논문은 다중 모달 문서 질의응답 및 검색 증강 생성(RAG)을 위한 포괄적인 벤치마크인 MMDocRAG를 제시한다. MMDocRAG는 4,000개 이상의 전문가 주석이 달린 QA 쌍과 다중 모달 증거 사슬, 그리고 인용문 선택 및 인터리브드 다중 모달 답변 생성에 대한 새로운 평가 지표를 특징으로 한다. 58개의 주요 LLM과 VLM, 그리고 다양한 검색 방법을 광범위하게 벤치마킹한 결과, 현재 모델들이 노이즈가 많고 다양한 문서 시나리오에서 효과적인 다중 모달 증거 선택 및 인터리브드 이미지-텍스트 답변 생성에 어려움을 겪는다는 사실을 발견한다. 독점 모델이 오픈소스 모델보다 상당한 우위를 보이지만, 파인튜닝과 고품질 시각 설명의 사용이 상당한 개선을 가져올 수 있음을 시사한다. 이러한 발전에도 불구하고, 현재 시스템과 포괄적인 다중 모달 DocVQA/DocRAG 작업의 요구 사항 사이에는 상당한 성능 격차가 존재한다. MMDocRAG가 문서 이해 및 RAG 분야에서 보다 효과적이고 해석 가능한 다중 모달 추론을 위한 향후 연구에 영감을 주기를 기대한다.
