VisDoM: Multi-Document QA with Visually Rich Elements Using Multimodal Retrieval-Augmented Generation
Paper Review
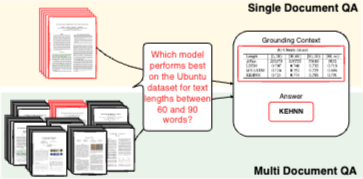
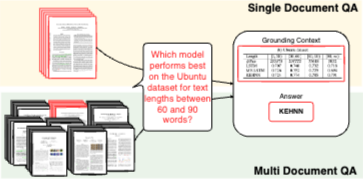
Introduction
정보가 풍부한 환경에서 PDF 문서는 재무, 법률, 과학 연구 등 다양한 분야에서 정보를 저장하고 전파하는 데 중요한 역할을 한다. 이러한 문서는 종종 텍스트, 시각 자료 및 표 형식 데이터가 풍부하게 혼합되어 있어 정보 검색 시스템에 고유한 과제를 제기한다. 데이터베이스와 같은 구조화된 형식과 달리 PDF는 본질적으로 비구조화되어 있으며 단락, 이미지, 차트 및 표를 결합한 다양한 레이아웃을 포함한다. 이러한 복잡성은 텍스트 및 시각적 콘텐츠를 모두 해석할 수 있는 정교한 멀티모달 처리 기술을 요구한다. PDF의 멀티모달 콘텐츠를 효과적으로 처리하는 것은 질문 답변(Ding et al., 2022; Mathew et al., 2021), 요약(Pang et al., 2023) 및 지식 추출(Pal et al., 2023)과 같은 다운스트림 작업에 필수적이며, 여기서 정확하고 상황 인식적인 데이터 추출은 의사 결정 프로세스를 크게 향상시킬 수 있다.
실제 문서 QA 시스템에서 쿼리는 단일 소스가 아닌 원본 문서 모음에 대해 직접 수행되는 경우가 많으므로 시스템은 관련 답변을 포함하는 문서를 식별해야 한다. 기존의 다중 문서 QA 데이터셋은 부족하며, 주로 텍스트 정보에 중점을 두어 표, 차트, 시각적 요소 등 실제 문서에서 발견되는 다양한 콘텐츠 형식을 간과하는 경향이 있다. 이러한 모달리티를 포함하는 데이터셋이 없으면 현재 QA 모델이 복잡한 멀티모달 질문을 처리하는 능력이 제한된다.
시각적으로 풍부한 콘텐츠 기반 문서의 맥락에서 기존 RAG 시스템은 검색을 위해 단일 모달리티(텍스트 또는 시각)에 의존하기 때문에 심각한 한계에 직면한다. 텍스트 기반 시스템은 언어적 추론에 능숙하지만 핵심 정보를 포함할 수 있는 표나 그림과 같은 중요한 시각적 요소를 종종 간과한다. 반대로, 시각 기반 검색을 활용하는 멀티모달 RAG(Chen et al., 2022) 시스템은 시각 데이터를 효과적으로 추출할 수 있지만, 텍스트가 시각 입력보다 더 나은 성능을 보이는 경우가 많으므로 LLM의 시각적 추론 능력에 의해 종단 간 성능이 제한되는 경우가 흔하다.
본 논문은 이러한 한계를 해결하기 위해 VisDoMBench라는 새로운 다중 문서, 멀티모달 QA 벤치마크를 소개하고, 시각적 및 텍스트적 RAG를 동시에 활용하는 새로운 멀티모달 RAG 접근 방식인 VisDoMRAG를 제안한다.
Methodology
VisDoMBench는 표, 차트, 슬라이드 등 시각적으로 풍부한 콘텐츠를 다루도록 특별히 설계된 최초의 다중 문서, 멀티모달 QA 데이터셋이다. VisDoMBench는 다양한 복잡한 콘텐츠와 질문 유형을 포함하며, 주석 처리된 증거를 통해 멀티모달 QA 시스템에 대한 포괄적인 평가를 제공한다.
VisDoMBench 데이터셋은 다음 기준에 따라 큐레이션되었다: 1) 표, 차트, 프레젠테이션 슬라이드를 포함하는 시각적으로 풍부한 콘텐츠 포함, 2) 공개적으로 접근 가능한 원본 문서 활용, 3) 근거 기반 증거 존재. 이러한 매개변수는 데이터셋의 멀티모달 정보 검색 관련성과 실제 질문 답변 작업에 대한 적용 가능성을 보장하기 위해 설정되었다. 이 코퍼스는 UDA 벤치마크(Hui et al., 2024)에서 파생된 PaperTab 및 FeTaTab 분할, SciGraphQA(Li and Tajbakhsh, 2023), SPIQA(Pramanick et al., 2024), SlideVQA(Tanaka et al., 2023)를 포함한다.
데이터 샘플링 과정에서는 중복을 제거하고, 질문 수준의 중복을 방지하며, 레이아웃 및 문서 메타데이터와 관련된 사소한 질문을 필터링한다. 또한, 현실적인 다중 문서 설정을 시뮬레이션하기 위해 각 질문에 다양한 수의 방해 문서가 추가되며, 쿼리당 평균 페이지 수를 50에서 200 사이로 유지하여 충분한 방해 콘텐츠를 확보한다. 모호한 질문을 처리하기 위해 GPT-4o를 사용하여 질문 증강 절차를 구현하여 주어진 질문과 해당 질문에만 답변하는 문서 간에 일대일 매핑을 생성한다.
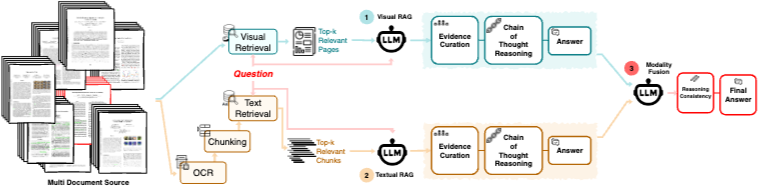
VisDoMRAG (그림 2)는 시각적으로 풍부한 문서 QA를 위한 멀티모달 RAG 접근 방식이다. 이는 다음 두 단계로 구성된다:
Evidence-driven Parallel Unimodal RAG Pipelines
:
Textual Retrieval Pipeline
: OCR을 사용하여 문서에서 텍스트를 추출하고, 추출된 텍스트를 더 작고 인덱싱 가능한 청크로 분할한다. 원본 문서 및 페이지 번호를 나타내는 메타데이터는 추적성을 위해 보존된다. 이 청크는 텍스트 임베딩 모델(BGE-1.5)을 사용하여 인덱싱되어 효율적인 검색을 가능하게 한다. 관련 청크는 텍스트 검색 모델에 의해 지정된 쿼리와 관련하여 검색되고, 텍스트 답변 생성을 위해 쿼리와 함께 LLM에 컨텍스트 입력으로 제공된다.
Visual Retrieval Pipeline
: 시각 RAG 파이프라인은 이미지, 차트 및 다이어그램을 포함한 그래픽 요소의 추출 및 분석에 전념한다. 주어진 PDF 세트에 대해 시각 임베딩 모델(ColQwen2)은 모든 문서에 대해 페이지 수준 세분성으로 인덱스를 생성한다. 관련 페이지는 지정된 쿼리를 기반으로 시각 검색 모델에 의해 검색되며, 이 페이지는 멀티모달 LLM에 시각 컨텍스트로 제공된다.
* Prompting Strategy
: 텍스트 및 시각 파이프라인은 정교한 3단계 프롬프팅 전략을 사용한다.
1. Evidence Curation: 검색된 컨텍스트에서 관련 증거를 추출하도록 LLM을 프롬프트한다. LLM은 쿼리에 답변할 가능성이 가장 높은 핵심 섹션(단락, 표, 그림 세부 정보 등)을 분리하고 구조화된 형식으로 표현해야 한다.
2. Chain-of-Thought Reasoning
: 다중 문서 아티팩트에서 추론 연쇄를 추출하는 것은 최종 답변 생성을 위해 큐레이션된 증거를 상황화하는 데 도움이 된다. 사고 연쇄(CoT) 추론(Wei et al., 2022)을 활용하여 일관된 단계별 서술을 형성하는 개별 증거 조각을 연결한다.
3. Answer Generation
: 큐레이션된, 컨텍스트적으로 관련된 증거와 CoT 추론 프로세스의 통찰력을 활용하여 답변 생성 단계는 정확하고 잘 정당화된 응답을 생성한다. 또한, 질문 유형에 따라 적절한 답변 형식에 대해 LLM을 안내하기 위해 타겟팅된 프롬프트를 사용한다.
Modality Fusion:
모달리티 융합 단계는 VisDoMRAG의 핵심 기여로, 더 간단한 멀티모달 접근 방식과 차별화된다. 이 단계는 큐레이션된 증거, 추론 연쇄 및 생성된 답변을 포함하여 텍스트 및 시각 파이프라인의 출력을 입력으로 사용한다. 융합 프로세스는 텍스트 및 시각 파이프라인에서 생성된 추론 연쇄 간의 일관성을 평가하도록 LLM을 프롬프트함으로써 조율된다. 이는 CoT의 자기 일관성(Wang et al., 2023)에서 영감을 얻은 것으로, 개별 연쇄 결과의 일관성을 기반으로 답변을 도출한다. 일관성 제약 프롬프팅은 서로 다른 모달리티의 별도 처리에서 발생할 수 있는 불일치, 모순 및 추론 공백을 식별하고 해결하는 데 중요하다.
Experiments
실험에서는 먼저 벤치마크에서 서로 다른 검색 및 인덱싱 모델을 평가한 다음, 식별된 최적의 검색 모델과 서로 다른 LLM을 사용하여 종단 간 QA 평가를 수행한다.
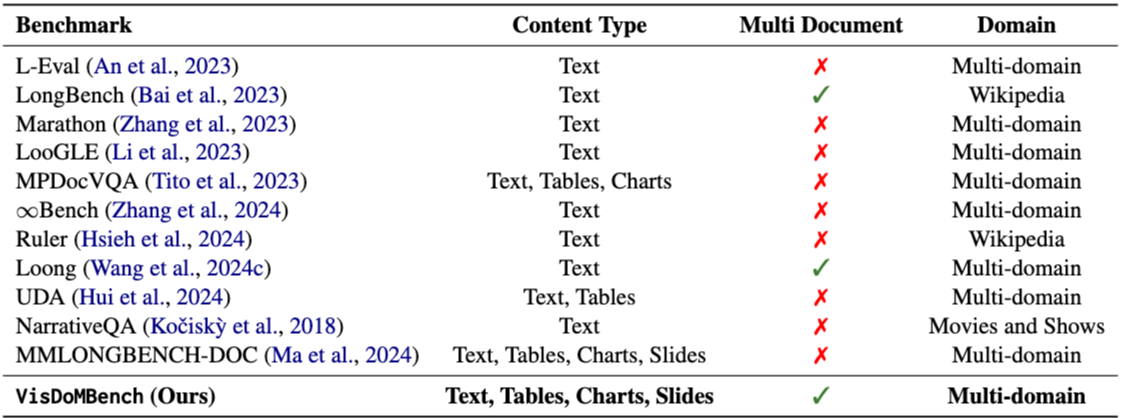

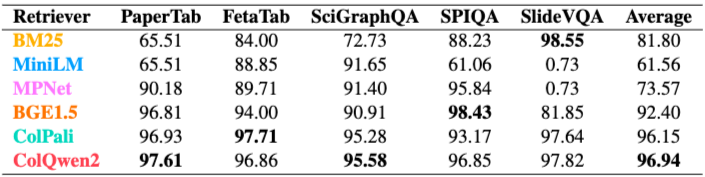
Retrieval: BM25(Robertson et al., 1995), MPNet(Song et al., 2020), MiniLM(Wang et al., 2020), BGE-1.5(Xiao et al., 2023)와 같은 인기 있는 텍스트 기반 검색 모델이 사용되었다. 시각 검색의 경우, ColPali 및 ColQwen2와 같은 LLM 기반의 후기 상호 작용 기반 멀티 벡터 검색 모델(Faysse et al., 2024)이 활용되었다. 평가는 검색된 증거와 정답 증거 간의 평균 정규화 최장 공통 부분열(ANLCS)과 문서 식별 능력으로 이루어진다.
End-to-End QA: 멀티 이미지 입력 및 긴 컨텍스트를 처리할 수 있는 LLM인 Gemini-1.5-Flash(Reid et al., 2024), ChatGPT-4o(OpenAI, 2024), 그리고 오픈 소스 LLM인 Qwen2-VL-7B-Instruct(Yang et al., 2024)가 사용되었다. 다음 네 가지 접근 방식이 평가되었다: 1. Long Context: 모든 문서 텍스트를 컨텍스트로 전달. 2. TextualRAG. 3. VisualRAG. 4. VisDoMRAG. 평가는 Word Overlap F1 점수를 사용한다.
Ablations: ChatGPT4o를 사용하여 VisDoMRAG 프레임워크의 다양한 구성 요소의 효과를 평가하고, 모달리티 통합을 위한 초기 융합 및 후기 융합 전략을 비교하는 어블레이션 연구가 수행되었다.
Results
Retrieval Evaluation
: 그림 3은 문서에서 증거를 추출하는 다양한 검색 모델의 성능을 보여준다. ANLCS를 기준으로 ColQwen2는 강력한 LLM 백본(Qwen2)의 존재로 인해 다른 검색 기준선보다 뛰어난 성능을 보인다. 표 4는 정확한 원본 문서를 식별하는 검색기 성능을 평가한다. ColQwen2가 BGE1.5 모델보다 4.5% 더 나은 성능을 보인다. SlideVQA의 경우, 시각 모델이 텍스트 전용 모델보다 훨씬 뛰어난 성능 차이를 보였다. 이는 슬라이드에 텍스트가 희소하여 쿼리와 컨텍스트 간에 직접 일치하는 키워드로 구성된 경우가 많기 때문이다.
**End-to-End Evaluation
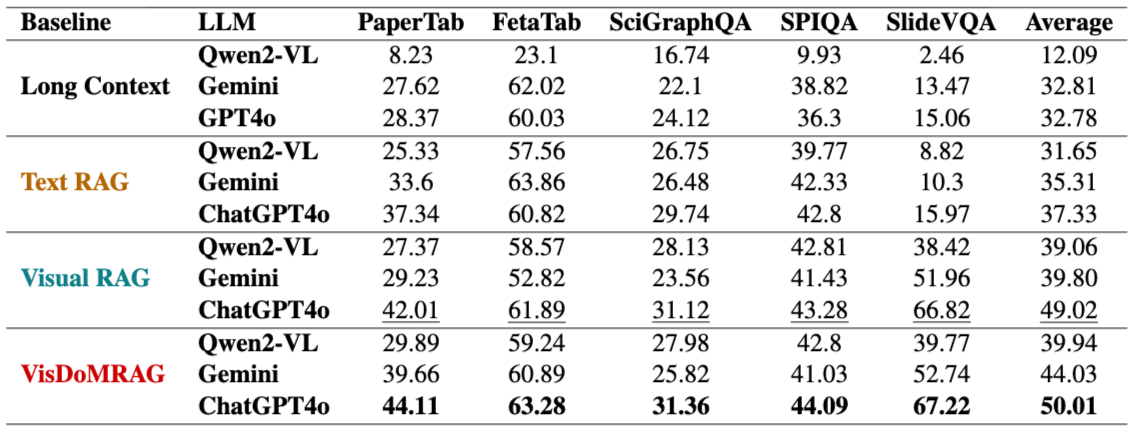
: 표 3은 VisDoMRAG가 다양한 LLM(Qwen2VL (7B), Gemini Flash, GPT-4)에서 Visual RAG, Textual RAG 및 Long Context 방법에 비해 일관되게 우수한 성능을 달성함을 나타낸다. 성능 향상은 PaperTab에서 2.1-21.6%, FetaTab에서 0.67-36.14%, SciGraphQA에서 0.24-11.24%, SPIQA에서 0.81-32.87%, SlideVQA에서 0.40-52.16% 범위로 나타난다.
텍스트 RAG와 시각 RAG를 비교하면, 시각 RAG가 일관되게 텍스트 RAG보다 우수한 성능을 보였다. 이는 데이터셋 구성이 시각적으로 풍부한 콘텐츠로 주로 이루어져 있으며, 시각 RAG가 시각 정보를 직접 활용할 수 있기 때문이다. Long-Context LLM 기준선은 높은 토큰 수와 특정, 국지적 증거 검색을 요구하는 작업의 특성(본질적으로 "건초 더미 속 바늘 찾기" 문제)으로 인해 덜 효과적인 것으로 나타났다. 모달리티 융합을 통한 VisDoMRAG는 이러한 과제를 완화하여 더 견고한 답변 생성을 가능하게 한다.
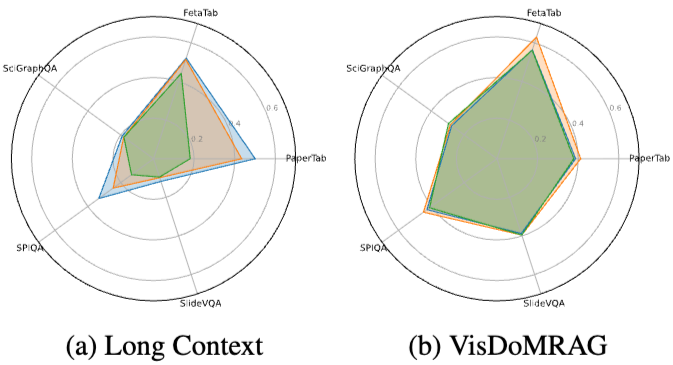
Effect of Increasing Page Volume
: 그림 4는 쿼리당 페이지 수 볼륨별로 세분화된 접근 방식의 성능을 보여준다. 예상대로, Long-Context 모델은 컬렉션의 페이지 수가 증가함에 따라 상당한 성능 저하를 보인다. 반면, 멀티모달 RAG 접근 방식은 LLM이 질문에 효과적으로 답변하기 위해 처리해야 하는 컨텍스트 양을 제한할 수 있어 높은 페이지 수에서도 일관된 QA 성능을 보인다.
Ablation Analysis
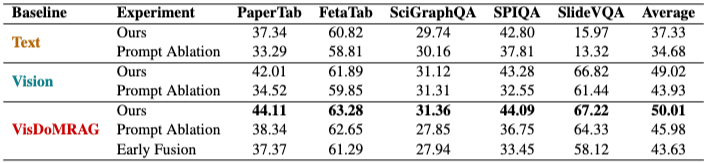
:** 표 5의 어블레이션 연구 결과, VisDoMRAG에서 사용된 후기 융합(late fusion) 전략이 초기 융합(early fusion)보다 우수한 성능을 보였다. 이는 각 모달리티를 독립적으로 처리한 후 결합하는 것이 더 효과적임을 시사한다. 또한, 증거 큐레이션, 사고 연쇄(CoT) 프롬프팅 및 추론 일관성을 포함하는 제안된 프롬프팅 전략의 중요성이 확인되었다. 이러한 구성 요소를 제거하면 텍스트 전용 설정에서 평균 점수가 37.33에서 34.68로, 시각 전용 설정에서 49.02에서 43.93으로, VisDoMRAG 설정에서 50.01에서 45.98로 감소하는 등 상당한 성능 저하가 발생했다.
Conclusion and Future Work
본 연구에서는 표, 차트, 슬라이드 등 시각적으로 풍부한 요소를 포함하는 다중 문서 시스템을 평가하기 위해 설계된 최초의 QA 데이터셋인 VisDoMBench를 소개한다. 텍스트 및 시각적 이해가 모두 필요한 문서를 대상으로 함으로써 VisDoMBench는 멀티모달 검색 시스템의 기능을 평가하기 위한 새로운 벤치마크를 제공한다. 또한, 일관성 제약 모달리티 융합을 사용하여 시각적 및 텍스트적 파이프라인을 융합하는 멀티모달 검색 증강 생성(RAG) 접근 방식인 VisDoMRAG를 제시했다. 이 방법은 기존의 긴 컨텍스트, 텍스트 및 시각 RAG보다 12-20%의 상당한 개선을 보였다. 현재 작업은 멀티모달 다중 문서 환경에서 RAG에 중점을 두지만, 향후 작업에서는 이 접근 방식을 종단 간 학습 모델을 통한 추론으로 확장할 계획이다.
Ethical Statement
본 연구는 공개적으로 이용 가능한 데이터셋을 사용한다. 인간 평가자의 신원은 기밀로 유지되며, 개인 식별 정보(PII)는 실험의 어떤 단계에서도 사용되지 않는다. 본 연구는 문서 QA 애플리케이션만을 목적으로 한다. LLM 안전성에서 발생할 수 있는 잠재적 위험 및 완화 전략에 대한 더 깊은 이해를 위해 (Kumar et al., 2024; Cui et al., 2024; Luu et al., 2024)의 관련 연구를 참고한다.
Limitations
본 연구에서 제시된 발전에도 불구하고 몇 가지 한계가 있다. 텍스트 추출 및 문서 파싱 파이프라인이 여전히 필요하며, 이는 추가적인 복잡성과 처리 시간을 야기할 수 있다. 또한, 본 방법론은 여러 LLM 호출을 필요로 한다. 이 접근 방식이 최적은 아닐 수 있지만, 긴 컨텍스트 모델을 사용하는 것보다는 여전히 비용 효율적이다. 모든 대규모 언어 모델(LLM)을 포함하는 작업과 마찬가지로, 본 접근 방식은 AI 안전 및 환각 위험과 관련된 내재적인 한계에 직면한다. 이러한 문제는 생성된 출력의 신뢰성과 정확성에 영향을 미칠 수 있으며 안전 위험을 강조하며, 이러한 문제를 완화하기 위한 AI 분야의 지속적인 연구 및 개선의 필요성을 시사한다.
