Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Paper Review
서론

기존 기계 독해(MRC) 모델은 SQuAD 벤치마크에서 인간 수준을 뛰어넘는 성능을 보였지만, 자연어에 대한 완전한 이해를 의미하지는 않는다. 특히 적대적 방법론을 사용하면 현재 모델들이 자연어를 정확하게 이해하지 못함을 알 수 있다. 또한, 기존 멀티-홉(multi-hop) 데이터셋의 많은 예시들이 실제로 멀티-홉 추론을 요구하지 않는다는 문제점이 지적되었다. HotpotQA와 같은 데이터셋은 설명 가능한 요소를 포함하지만, 이는 모델의 추론 능력을 평가하기에는 불충분하고, R4C와 같은 다른 데이터셋은 규모가 작아서 엔드-투-엔드 시스템 훈련에 사용하기 어렵다.
이 연구에서는 이러한 한계점을 극복하기 위해 구조화된 데이터(Wikidata)와 비구조화된 데이터(Wikipedia)를 결합하여 새로운 대규모 고품질 멀티-홉 질의응답(QA) 데이터셋인 2WikiMultiHopQA를 제시한다. 이 데이터셋은 질문에서 답변으로 이어지는 추론 경로를 설명하는 '증거(evidence)' 정보를 포함한다. 이 증거 정보는 예측에 대한 포괄적인 설명을 제공하고 모델의 추론 기술을 평가하는 데 유용하다. 연구진은 질문-답변 쌍 생성 시 멀티-홉 단계와 질문의 품질을 보장하기 위해 파이프라인과 템플릿 세트를 신중하게 설계했다. 또한, Wikidata의 구조화된 형식을 활용하고 논리 규칙을 사용하여 자연스러우면서도 멀티-홉 추론이 필요한 질문을 생성했다. 실험을 통해 이 데이터셋이 멀티-홉 모델에 도전적이며 멀티-홉 추론이 반드시 필요함을 입증한다.
Task 개요
2.1 Task 형식화 및 측정 항목
이 연구에서는 세 가지 task를 형식화한다: (1) 답변 예측, (2) 문장 수준 지원 사실(SFs) 예측, (3) 증거 생성.
- 입력: 질문 와 문서 집합 .
- 출력:
- (1) 에 대한 답변 (텍스트 스팬)를 에서 찾는다.
- (2) 모델이 에 답변하는 데 사용한 내의 문장 수준 집합 (문장들)을 찾는다.
- (3) 에서 로의 추론 경로를 설명하는 트리플(subject entity, property, object entity)로 구성된 증거 집합을 생성한다.
세 가지 작업의 평가는 정답 일치(EM) 및 F1 점수를 사용한다. 모델의 전체 능력을 평가하기 위해 답변 스팬, 문장 수준 , 증거의 평가를 결합한 조인트 측정 항목을 도입한다.
여기서 이고 이다. 는 답변 스팬의 정밀도와 재현율을, 는 문장 수준 의 정밀도와 재현율을, 는 증거의 정밀도와 재현율을 나타낸다. 은 세 가지 작업 모두에서 정확히 일치할 때만 1이고, 그렇지 않으면 0이다.
2.2 질문 유형
데이터셋은 다음과 같은 네 가지 질문 유형을 포함한다:
1. 비교 질문(Comparison question): 동일 그룹의 두 개 이상의 엔티티를 특정 측면에서 비교하는 질문이다. 예를 들어, "누가 먼저 태어났는가, 알베르트 아인슈타인인가 아브라함 링컨인가?"와 같이 태어난 날짜나 사망 날짜를 비교한다.
2. 추론 질문(Inference question): 지식 베이스(KB) 내의 두 트리플 과 로부터 생성된다. 논리 규칙을 활용하여 새로운 트리플 를 얻는데, 여기서 은 과 로부터 추론된 관계이다. 이 새로운 트리플을 사용하여 질문-답변 쌍이 생성된다. 예를 들어, (아브라함 링컨, 어머니, 낸시 행크스 링컨)과 (낸시 행크스 링컨, 아버지, 제임스 행크스)로부터 (아브라함 링컨, 외할아버지, 제임스 행크스)를 추론하고, "아브라함 링컨의 외할아버지는 누구인가?"와 같은 질문이 생성된다.
3. 조합 질문(Compositional question): KB 내의 두 트리플 과 로부터 생성된다. 추론 질문과 달리 두 관계 과 로부터 추론 관계 이 존재하지 않는 경우이다. 예를 들어, (라 라 랜드, 배급사, 서밋 엔터테인먼트)와 (서밋 엔터테인먼트, 설립자, 베른트 아이힝거) 트리플에서, 배급과 설립자 관계 사이에 직접적인 추론 관계가 없다. 이 경우, "라 라 랜드를 배급한 회사의 설립자는 누구인가?"와 같이 엔티티 와 두 관계 로부터 질문이 생성된다. 답변은 두 번째 트리플의 엔티티 이다.
4. 브릿지-비교 질문(Bridge-comparison question): 브릿지 질문과 비교 질문이 결합된 유형이다. 브릿지 엔티티를 찾고 비교를 수행해야 답변을 얻을 수 있다. 예를 들어, 두 영화를 직접 비교하는 대신, "라 라 랜드와 테넷 중 감독이 먼저 태어난 영화는 무엇인가?"와 같이 두 영화 감독의 정보를 비교한다. 이 유형의 질문에 답변하려면 모델은 두 단락을 연결하는 브릿지 엔티티(영화와 감독)를 찾아 생년월일 정보를 얻고, 비교를 통해 최종 답변을 도출해야 한다.
데이터 수집
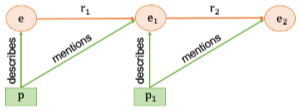
이 연구에서는 Wikipedia의 텍스트 설명과 Wikidata의 스테이트먼트 세트를 활용하여 데이터셋을 구축한다. 각 Wikipedia 문서의 요약 부분만 엔티티를 설명하는 단락으로 사용한다. Wikidata는 트리플(주체, 관계, 객체) 형태로 데이터를 저장하는 협력적인 지식 베이스이다.
멀티-홉 데이터셋 생성 과정은 세 가지 주요 단계로 구성된다: (1) 템플릿 세트 생성, (2) 데이터 생성, (3) 생성된 데이터 후처리.
(1) 템플릿 세트 생성
- 비교 질문: HotpotQA 훈련 데이터의 비교 질문(17,456개)에서 Spacy를 사용하여 개체명 인식(NER) 태그와 레이블을 추출한다. 이를 통해 질문의 단어를 NER 태거에서 얻은 레이블로 대체하여 템플릿 세트 을 얻는다. Wikipedia에서 가장 인기 있는 상위 50개 엔티티에 대해 을 기반으로 수동으로 템플릿 세트를 생성한다. 이 과정에서 Min et al. (2019)에서 논의된 바와 같이 질문을 싱글-홉 또는 문맥-의존적 멀티-홉으로 만드는 모든 템플릿은 제거하여 멀티-홉을 보장한다. 브릿지-비교 질문 템플릿은 비교 질문 템플릿을 기반으로 수동으로 확장된다.
- 추론 질문: 지식 그래프의 논리 규칙을 활용하여 멀티-홉 추론이 필요하지만 간단한 질문을 생성한다. 예를 들어,
spouse(a, b) ∧ mother(b, c) ⇒ mother in law(a, c)와 같은 논리 규칙을 사용한다. AMIE 모델 (Gal´arraga et al., 2013) 결과를 기반으로, Wikidata 관계에 적합하도록 모든 논리 규칙을 수동으로 확인하고 검증하여 28개의 논리 규칙을 얻는다. - 조합 질문: 이 질문 유형을 위해 Wikidata의 다양한 엔티티와 속성을 활용한다. 첫 번째 관계로 13개 속성 (예: composer, director), 두 번째 관계로 22개 속성 (예: date of birth, occupation)을 사용한다. 인간, 영화 등 15개 엔티티를 사용하여 총 799개의 템플릿을 얻는다.
(2) 데이터 생성
- 비교 질문 (알고리즘 1): 각 엔티티 그룹에 대해 두 개의 엔티티 를 무작위로 선택한다. Wikidata에서 각 엔티티의 모든 트리플(관계 및 객체)을 얻는다. 두 엔티티 간의 상호 관계 집합 을 얻는다. 각 엔티티의 Wikipedia 정보를 얻는다. 내의 각 관계 에 대해, 트리플 과 에서 얻은 이 의 Wikipedia 문서에, 가 의 Wikipedia 문서에 나타나는지 확인하는 요구 사항을 통과하면, 질문 , 문맥 , 문장 수준 , 증거 , 답변 를 포함하는 질문-답변 쌍을 생성한다. 는 과 트리플이다.
- 브릿지 질문 (알고리즘 2): 각 엔티티 그룹에 대해 엔티티 를 무작위로 선택하고, Wikidata에서 해당 엔티티의 스테이트먼트 집합을 얻는다. 미리 정의된 관계 에서 첫 번째 관계 정보를 기반으로 스테이트먼트 집합을 필터링하여 1-홉 집합을 얻는다. 의 각 요소에 대해 동일한 프로세스를 수행하여 2-홉 집합을 얻는데, 의 각 요소는 튜플 이다. 의 각 튜플에 대해 엔티티 와 의 Wikipedia 문서를 얻는다. 샘플이 멀티-홉 데이터셋이 될 수 있는지 확인하는 요구 사항을 검사한다. 예를 들어, 브릿지 엔티티 요구 사항은 (e를 설명하는 단락)가 을 언급해야 한다는 것이고, 스팬 추출 답변 요구 사항은 (e1을 설명하는 단락)이 를 언급해야 한다는 것이다. 2-홉 요구 사항은 가 를 포함하지 않고 이 를 포함하지 않아야 한다는 것이다. 최종적으로 를 생성한다.
(3) 생성된 데이터 후처리
생성된 데이터에서 예/아니오 질문 중 '아니오' 질문의 수가 많으므로, 이를 균형 있게 맞추기 위해 후처리를 수행한다. 또한, 여러 개의 참 답변이 가능한 질문은 하나의 샘플이 하나의 답변만 갖도록 모호한 경우를 모두 제거한다.
방해 단락 수집: Yang et al. (2018) 및 Min et al. (2019)에 따라, bigram tf-idf를 사용하여 질문과 가장 유사한 Wikipedia 단락 상위 50개를 검색한다. 그런 다음, 두 골드 단락(브릿지-비교 질문의 경우 네 개)의 엔티티 유형을 사용하여 상위 8개 단락(브릿지-비교 질문의 경우 상위 6개)을 선택하여 방해 단락으로 간주한다. 10개의 단락(골드 및 방해 단락 포함)을 섞어 문맥을 구성한다.
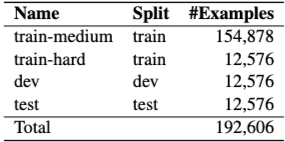
데이터셋 통계 (벤치마크 설정): 단일-홉 모델을 사용하여 데이터를 훈련, 개발, 테스트 세트로 분할한다. 5-겹 교차 검증을 수행하며, 모델의 평균 F1 점수는 86.7%이다. 단일-홉 모델이 해결한 모든 질문은 train-medium 부분집합으로 간주된다. 나머지는 train-hard, dev, test로 분할되며, 각 부분집합에 다른 유형의 질문 수가 균형을 이루도록 한다. 총 192,606개의 샘플을 포함한다.
데이터 분석
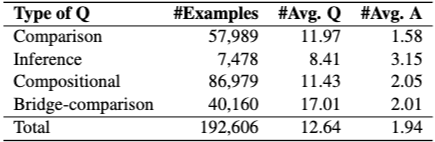
질문 및 답변 길이
데이터셋의 질문 및 답변 특성을 정량적으로 분석한다. 조합 질문이 가장 많은 예시를 포함하고, 추론 질문이 가장 적은 예시를 포함한다. 하나의 질문이 하나의 가능한 답변만 갖도록 보장하기 위해 Wikidata 정보를 사용하여 여러 추론 질문을 제거했다. 추론 질문의 평균 질문 길이는 가장 짧고, 브릿지-비교 질문의 평균 질문 길이는 가장 길다. 비교 및 브릿지-비교 질문의 평균 답변 길이는 추론 및 조합 질문보다 짧다.
멀티-홉 추론 유형
데이터셋의 멀티-홉 추론 유형은 다음과 같다:
- 비교 질문: 두 엔티티 간의 양적 또는 논리적 비교를 통해 답변을 얻는다.
- 조합 질문: 여러 기본 질문에 순차적으로 답변하고 이를 결합해야 한다. 예를 들어, "Versus의 설립자는 왜 죽었는가?"에 답변하려면 "(1) Versus의 설립자는 누구인가?"와 "(2) 그/그녀는 왜 죽었는가?"라는 두 하위 질문에 순차적으로 답변해야 한다.
- 추론 질문: 여러 논리 규칙을 이해해야 한다. 예를 들어, 손주를 찾으려면 먼저 자녀를 찾고, 그 자녀를 기반으로 다시 자녀를 찾아야 한다.
- 브릿지-비교 질문: 브릿지 엔티티를 찾고 비교를 수행하여 최종 답변을 얻어야 한다.
답변 유형
답변 정보(문자열 및 Wikidata ID)를 사용하여 답변 유형을 분류한다. Wikidata의 instance of 속성 값을 기반으로 708개의 고유한 답변 유형을 얻는다. 데이터셋에서 상위 5개 답변 유형은 예/아니오(31.2%), 날짜(16.9%), 영화(13.5%), 인간(11.7%), 대도시(4.7%)이다.
실험

5.1 데이터셋 품질 평가
데이터셋의 난이도와 멀티-홉 추론 능력을 평가한다.
- 난이도 평가: Yang et al. (2018)에서 설명된 멀티-홉 모델을 사용하여 HotpotQA와 본 연구의 데이터셋에서 성능을 비교한다. 문장 수준 SFs 예측 작업의 점수는 본 데이터셋이 HotpotQA보다 높지만, 답변 예측 작업의 점수는 HotpotQA보다 낮다. 전반적으로 조인트 측정 항목에서 본 데이터셋의 점수가 HotpotQA보다 낮다. 이는 두 데이터셋의 인간 성능이 유사한 점을 고려할 때, 본 데이터셋의 어려운 질문 수가 HotpotQA보다 많다는 것을 시사한다.
- 멀티-홉 추론 평가: Min et al. (2019)과 유사하게, 단일-홉 BERT 모델 (Devlin et al., 2019)을 사용하여 본 데이터셋의 멀티-홉 추론 능력을 테스트한다. HotpotQA의 F1 점수는 64.6인 반면, 본 데이터셋의 F1 점수는 55.9이다. 본 데이터셋의 결과는 HotpotQA보다 8.7 F1 낮다. 이는 본 데이터셋의 많은 예시들이 해결하기 위해 멀티-홉 추론을 필요로 함을 나타낸다.
이러한 결과는 본 데이터셋이 멀티-홉 모델에게 도전적이며 멀티-홉 추론을 필요로 한다는 것을 보여준다.
5.2 기준선 결과
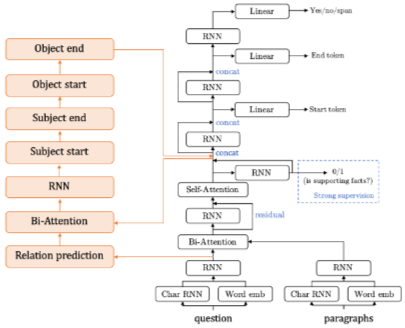
Yang et al. (2018)의 기준선 모델을 수정하여 증거 생성 작업을 수행하는 새로운 구성요소를 추가했다. 기존 기준선의 bi-attention과 같은 여러 기술을 재사용하여 증거를 예측한다. 증거 정보는 주체 엔티티, 관계, 객체 엔티티를 포함하는 트리플 집합이다. 질문을 사용하여 관계를 예측한 다음, 예측된 관계와 문맥(문장 수준 SFs 예측 후)을 사용하여 주체 및 객체 엔티티를 얻는다.
기준선 모델의 결과는 다음과 같다: 문장 수준 SFs 예측 작업의 점수는 상당히 높지만, 증거 생성 작업의 점수는 매우 낮다. 이는 증거 생성이 어려운 작업임을 나타낸다. 오류 분석 결과, 모델은 트리플 집합에서 하나의 올바른 트리플을 예측할 수 있지만, 트리플 집합 전체를 정확하게 얻는 것은 매우 어렵다. 이는 EM 점수가 매우 낮은 이유이다. 증거 생성 작업을 추가하는 것이 추론 및 추론 기술을 테스트하는 데 적합하다고 판단한다.
질문 유형별 난이도를 조사하기 위해 각 유형별 성능을 분류한다. 답변 예측 작업에서는 추론 및 조합 질문에서 높은 점수를 얻었지만, 문장 수준 SFs 예측 작업에서는 비교 및 브릿지-비교 질문에서 높은 점수를 얻었다. 전반적으로 추론 질문의 조인트 측정 점수가 가장 낮다. 이는 이 유형의 질문이 모델에게 더 도전적임을 시사한다. 증거 생성 작업은 다른 두 작업에 비해 모든 유형의 질문에서 가장 낮은 점수를 보인다.
5.3 인간 성능
테스트 세트에서 무작위로 선택된 100개 샘플에 대해 인간 성능을 측정한다. 각 샘플은 세 명의 작업자(대학원생)에 의해 주석 처리된다. 작업자에게 질문, 문맥, 그리고 미리 정의된 관계(증거 생성용)를 제공하고, 답변, 문장 수준 SFs 집합, 증거 집합을 제공하도록 요청한다. 이전 연구와 유사하게, 각 샘플에 대해 최대 EM 및 F1을 획득하여 인간 성능의 상한값을 계산한다.
인간 작업자들은 모델보다 훨씬 높은 성능을 달성했다. 답변 예측 작업에서 인간 성능은 91.0 EM 및 91.8 F1이다. 이는 Wikipedia와 Wikidata 간의 불일치 정보로 인해 질문에 답할 수 없는 경우가 발생하기 때문에 여전히 개선의 여지가 있음을 시사한다. 본 데이터셋의 답변 예측 작업에 대한 인간 성능(91.8 F1 UB)은 HotpotQA의 98.8 F1 UB와 비교할 때 상대적으로 작은 차이를 보인다. 모델은 답변과 문장 수준 SFs를 예측할 수 있지만, 증거를 찾는 데는 효과적이지 않다. 증거 생성 작업에서 인간과 모델 간의 성능 격차가 크다(78.8 F1 대 16.7 F1). 따라서 이는 멀티-홉 추론을 설명하는 새로운 도전적인 작업이 될 수 있다. 증거 생성 작업의 점수가 낮은 주된 이유는 Wikidata 이름의 모호성 때문이다. 전반적으로, 본 연구의 기준선 결과는 인간 성능에 훨씬 못 미친다. 이는 데이터셋이 도전적이며 미래에 개선할 여지가 많음을 보여준다.
5.4 Wikipedia와 Wikidata 간의 불일치 예시 분석
데이터셋에는 Wikipedia 문서와 Wikidata 지식 간의 불일치 정보로 인해 답변할 수 없는 질문이 존재한다. 데이터셋 생성 과정에서 트리플 에 대해, 먼저 객체 엔티티 가 주체 엔티티 를 설명하는 Wikipedia 문서에 나타나는지 확인한다. 본 연구의 가정은 객체 엔티티 가 나타나는 문서의 첫 문장이 가장 중요하다는 것이다. 그러나 객체 엔티티 가 문장에 나타나는지만 확인했기 때문에, 문장과 트리플 간에 의미론적 불일치가 있을 수 있다. 예를 들어, (Rakel Dink, spouse, Hrant Dink) 트리플과 Wikipedia 문장 "Rakel Dink (born 1959) is a Turkish Armenian human rights activist and head of the Hrant Dink Foundation."에서 후자로부터 "Hrant Dink"가 "Rakel Dink"의 배우자임을 추론할 수 없다.
따라서 이러한 불일치 사례를 최대한 배제하기 위한 휴리스틱을 정의했다. 일부 예시에서 주체 엔티티가 객체 엔티티와 유사하거나 동일하며 불일치 사례가 될 가능성이 높다는 것을 발견했다. 이러한 경우, 수동으로 샘플을 확인하고 최종 데이터셋에 포함할지 제거할지 결정한다. 그럼에도 불구하고, 휴리스틱으로 포착할 수 없는 사례가 여전히 존재한다. 훈련 세트에서 100개 샘플을 무작위로 선택하여 수동으로 확인한 결과, Wikipedia 문서와 Wikidata 트리플 간에 불일치가 있는 8개의 샘플을 발견했다. 다음 버전의 데이터셋에서는 각 관계에 대한 키워드 목록을 구축하여 Wikipedia 문장과 Wikidata 트리플 간의 대응을 확인하여 휴리스틱을 개선할 계획이다.
관련 연구
MRC 도메인의 멀티-홉 질문
현재 텍스트 데이터에 대해 제안된 네 가지 멀티-홉 MRC 데이터셋은 ComplexWebQuestions, QAngaroo, HotpotQA, R4C이다. 최근에는 Chen et al. (2020)이 표 형식 및 텍스트 데이터 모두에 대한 멀티-홉 질의응답 데이터셋인 HybridQA를 소개했다.
KB 도메인의 멀티-홉 질문
지식 그래프에 대한 질의응답은 수십 년 동안 연구되어 왔지만, 대부분의 현재 데이터셋은 간단한 질문(싱글-홉)으로 구성된다. Zhang et al. (2018b)은 싱글-홉 및 멀티-홉 질문을 모두 포함하는 METAQA 데이터셋을 소개했다. Abujabal et al. (2017)은 150개의 조합 질문으로 구성된 ComplexQuestions 데이터셋을 소개했다. 이 모든 데이터셋은 KB만을 사용하여 해결된다. 본 연구의 데이터셋은 Wikipedia와 Wikidata의 교차점을 기반으로 구축되었으므로, 구조화되거나 비구조화된 데이터를 사용하여 해결될 수 있다.
조합 지식 베이스 추론
KB에서 Horn 규칙을 추출하는 연구는 Inductive Logic Programming 문헌에서 광범위하게 다루어졌다. KB로부터 연관 규칙 및 논리 규칙을 마이닝하는 여러 접근 방식이 있다. 이 연구에서는 이러한 규칙이 모델의 추론 기술을 테스트하는 데 사용될 수 있음을 확인했다. 따라서, 본 연구에서는 r1(a, b) ∧ r2(b, c) ⇒ r(a, c) 형식의 논리 규칙을 활용한다. ComplexWebQuestions 및 QAngaroo 데이터셋도 데이터셋 구축 시 KB를 활용했지만, 본 연구처럼 논리 규칙을 활용하지는 않았다.
설명을 포함하는 RC 데이터셋
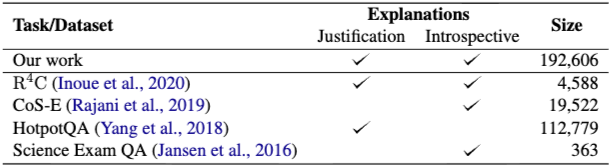
HotpotQA 및 R4C는 본 연구와 가장 유사한 작업이다. HotpotQA는 문장 수준 SFs 형태로 정당화 설명(결정을 뒷받침하는 증거 모음)을 제공한다. R4C는 정당화 및 내성적 설명(결정이 어떻게 이루어졌는지)을 모두 제공한다. 본 연구도 정당화 및 내성적 설명을 모두 제공하지만, 본 데이터셋의 설명은 Wikidata에서 얻은 구조화된 데이터인 트리플 집합인 반면, R4C의 설명은 반구조화된 데이터 집합이다. R4C는 HotpotQA를 기반으로 생성되었으며 4,588개의 질문을 포함한다. 데이터셋의 작은 규모는 포괄적인 설명을 포함한 멀티-홉 추론과 관련된 엔드-투-엔드 신경망 모델 훈련에 사용하기 어렵다는 것을 의미한다.
결론
이 연구에서는 예측에 대한 포괄적인 설명을 제공하는 대규모 고품질 멀티-홉 데이터셋인 2WikiMultiHopQA를 제시한다. 지식 베이스의 논리 규칙을 활용하여 자연스러우면서도 멀티-홉 추론이 필요한 질문을 생성했다. 실험을 통해 본 데이터셋이 멀티-홉 모델에 도전적이며 멀티-홉 추론을 반드시 요구한다는 것을 입증한다. 또한, Wikipedia와 Wikidata에서 사용 가능한 대규모 데이터를 활용함으로써 멀티-홉 MRC 데이터셋을 부트스트래핑하는 것이 유익함을 보여준다.
