MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Paper Review
서론

LLM은 외부 지식을 검색해 활용하는 RAG (Retrieval-Augmented Generation) 시스템을 통해 hallucination을 완화하고 응답 품질을 향상시킨다. 그러나 기존 RAG 시스템은 여러 개의 evidence를 검색하고 종합적으로 추론해야 하는 multi-hop queries에 적합하지 않으며, 이러한 multi-hop 쿼리에 특화된 RAG benchmark dataset도 부족한 상황이다.
본 논문은 이러한 공백을 해소하기 위해 MultiHop-RAG라는 새로운 benchmark dataset을 제안한다. 이 데이터셋은 뉴스 기사 기반 knowledge base, multi-hop queries, 정답, 그리고 관련 supporting evidence로 구성된다.
논문은 데이터셋 구축 절차를 상세히 설명하고, 두 가지 실험을 통해 MultiHop-RAG의 benchmark로서의 유용성을 검증한다.
- 첫 번째 실험: embedding model의 retrieval 성능 비교
- 두 번째 실험: GPT-4, PaLM, Llama2-70B 등 최신 LLM의 multi-hop reasoning 및 answer generation 능력 평가
두 실험 모두 기존 RAG 방식이 multi-hop query 검색 및 응답 생성에서 충분히 만족스럽지 못한 성능을 보임을 보여준다.
RAG와 Multi-Hop Queries
2.1 Retrieval-Augmented Generation (RAG)
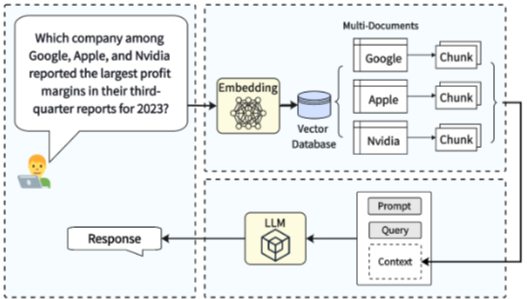
RAG 애플리케이션은 외부 corpus (D)를 knowledge base로 사용한다. 각 문서 (d_i \in D)는 chunk 단위로 분할되고, embedding model을 통해 vector representation으로 변환되어 vector database에 저장된다.
사용자 query (q)가 주어지면, 시스템은 query와 가장 유사한 top-K chunks를 검색하여 retrieval set (R_q = {r_1, r_2, ..., r_K})를 구성한다.
이 retrieved chunks는 query 및 optional prompt와 함께 LLM에 입력되어 최종 답변을 생성한다.
[
LLM(q, R_q, prompt) \rightarrow answer
]
2.2 Multi-Hop Queries
Multi-hop query는 답변을 생성하기 위해 여러 개의 supporting evidence를 검색하고 종합적으로 추론해야 하는 질의이다.
즉, multi-hop query의 경우 retrieval set (R_q)에 포함된 여러 chunk들을 통합적으로 reasoning해야 최종 답을 도출할 수 있다.
예시:
"Google, Apple, Nvidia 중 2023년 3분기 보고서에서 가장 높은 profit margin을 기록한 회사는 어디인가?"
이 경우 세 회사의 보고서를 각각 검색하고, 여러 evidence를 비교 및 종합 추론해야 한다.
논문은 실제 RAG 시스템에서 자주 등장하는 multi-hop query를 네 가지 유형으로 분류한다.
- Inference query: retrieval set으로부터 추론을 통해 답을 도출
- Comparison query: retrieval set 내 evidence를 비교하여 답 도출
- Temporal query: 시간 정보를 분석하여 답 도출
- Null query: retrieval set만으로는 답을 도출할 수 없는 query (hallucination 평가에 중요)
2.3 Evaluation Metrics
Multi-hop RAG 시스템 평가는 두 축으로 나뉜다.
1. Retrieval Evaluation
retrieval set의 품질은 최종 generation 품질을 결정한다. 각 query에 대해 ground-truth evidence와 비교하여 평가한다 (null query 제외).
사용 지표:
- MAP@K (Mean Average Precision at K)
- MRR@K (Mean Reciprocal Rank at K)
- Hit@K
2. Response Evaluation
LLM이 생성한 답변을 ground-truth answer와 비교하여 reasoning 능력을 평가한다.
MultiHop-RAG Dataset
3.1 Dataset Construction
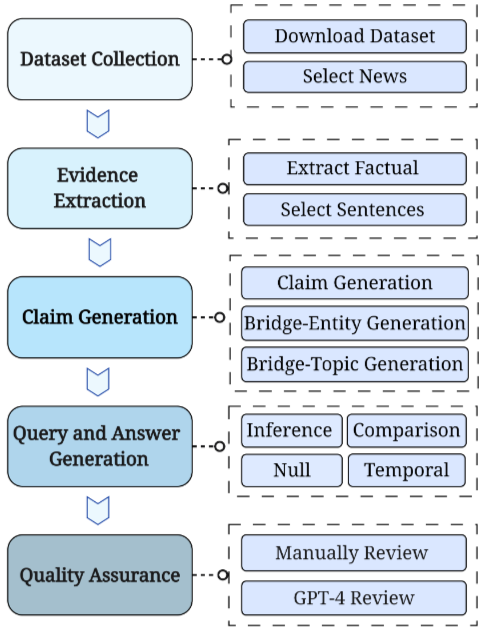
Step 1: Dataset Collection
- mediastack API를 통해 영어 뉴스 기사 수집
- 기간: 2023년 9월 26일 ~ 12월 26일
- LLM knowledge cutoff 이후 데이터 사용
- 1,024 tokens 이상 기사만 유지
Step 2: Evidence Extraction
각 기사에서 fact 또는 opinion 문장을 추출하여 supporting evidence로 사용한다.
다른 기사와 overlapping keyword를 가지는 evidence가 포함된 기사만 유지하여 multi-source reasoning이 가능하도록 설계했다.
Step 3: Claim, Bridge-Entity, Bridge-Topic Generation
GPT-4를 사용하여 multi-hop query 생성을 자동화한다.
원시 evidence는 구조적으로 불균일하므로, GPT-4가 이를 claim 형태로 재작성한다.
claim과 evidence 간 factual consistency 검증을 위해 UniEval framework를 사용한다.
- Bridge-entity / Bridge-topic:
여러 evidence에 공통으로 등장하는 entity 또는 topic으로, multi-hop reasoning을 연결하는 핵심 연결 고리 역할을 한다.
Step 4: Query and Answer Generation
동일한 bridge-entity 또는 bridge-topic을 공유하는 claim을 그룹화한다 (2~4개).
각 query 유형별로 GPT-4에 입력하여 multi-hop query를 생성한다.
실제 RAG 시나리오를 모방하기 위해 supporting evidence의 뉴스 source metadata를 query에 포함한다.
Step 5: Quality Assurance
- 일부 샘플을 수동 검토
- GPT-4 기반 자동 검증:
- 모든 evidence를 활용해야 함
- 제공된 evidence만으로 답이 도출 가능해야 함
- 답은 single word 또는 specific entity
- query는 지정된 유형을 준수해야 함
3.2 Descriptive Statistics
- 609개 뉴스 기사 (평균 2,046 tokens)
- 총 2,556개 multi-hop queries
- 약 88%는 non-null queries
필요 evidence 개수:
- 2개: 약 42%
- 3개: 약 30%
- 4개: 약 15%
Benchmarking RAG with MultiHop-RAG
4.1 Retrieval Task
embedding model 선택은 RAG 성능에 중요한 영향을 미친다.
실험 설정
- LlamaIndex framework 사용
- 문서 256-token chunking
- cosine similarity 기반 top-K retrieval
- reranker: bge-reranker-large
테스트 embedding models:
- ada-embeddings
- voyage-02
- llm-embedder
- bge-large-en-v1.5
- jina-embeddings-v2-base-en
- e5-base-v2
- instructor-large
실험 결과
- reranking은 성능을 개선하지만
- Hits@10 최고 0.7467
- Hits@4 최고 0.6625
이는 multi-hop query에서 단순 semantic similarity 기반 retrieval이 여전히 한계를 가진다는 점을 보여준다.
4.2 Generation Task
두 가지 설정을 비교한다.
- Retrieved chunks 사용
- Ground-truth evidence 직접 제공 (upper bound)
사용 모델
- GPT-4
- GPT-3.5
- Claude-2
- Google-PaLM
- Mixtral-8x7B-Instruct
- Llama-2-70B-chat-hf
실험 결과
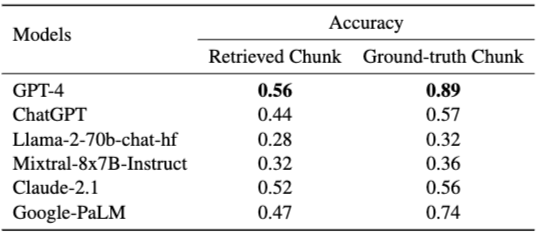
- Retrieved chunks 사용 시 GPT-4도 accuracy 0.56에 그친다.
- Ground-truth evidence 제공 시:
- GPT-4: 0.89
- PaLM: 0.74
- Llama-2-70B: 0.32
- Mixtral-8x7B: 0.36
Mixtral은 logical negation 처리와 temporal ordering에서 취약한 모습을 보였다.
이 실험은 multi-hop reasoning에서 특히 open-source LLM의 성능 개선 여지가 크다는 점을 보여준다.
4.3 Other Use Cases
- Query decomposition (예: LlamaIndex)
- LLM-based agent (예: AutoGPT)
- Hybrid retrieval (keyword + embedding)
MultiHop-RAG는 multi-hop query 기반 RAG 성능 향상을 위한 다양한 연구에 활용될 수 있다.
결론
MultiHop-RAG는 multi-hop query를 위해 설계된 RAG benchmark dataset 중 하나이다.
이 데이터셋은 다음 요소를 포함한다.
- Knowledge base
- Multi-hop queries
- Ground-truth answers
- Supporting evidence
Hybrid human + GPT-4 pipeline을 통해 구축되었으며, RAG 시스템 발전을 위한 중요한 benchmark로 활용될 수 있다.
한계점
-
정답 형식이 단순하다 (Yes/No, entity, temporal indicator 등).
향후에는 free-form generation을 허용하고, 더 정교한 evaluation metric을 도입할 수 있다. -
Supporting evidence가 최대 4개로 제한되어 있다.
더 복잡한 multi-hop reasoning으로 확장 가능하다. -
기본적인 RAG framework (LlamaIndex) 기반 실험을 수행했다.
향후에는 더 advanced한 RAG framework 또는 LLM-agent framework를 활용한 평가가 가능하다.
