
Introduction
최근 LLM은 self-consistency를 통해 다양한 추론 trace를 샘플링한 뒤 다수결로 최종 답을 집계하여 추론 정확도를 높이는 방식을 보여주고 있다. 하지만 입력마다 많은 추론 trace를 생성하면 추론 오버헤드가 선형적으로 증가해 상당한 계산 비용을 초래하며 실사용에는 어려움이 발생한다.
게다가 추론 trace 수가 증가한다고 성능이 일관성 있게 좋아지는 것도 아니다. self consistency는 다양한 추론 trace의 품질 차이를 무시하고 모두 동일하게 취급하여 병렬 추론을 하며 저품질 경로가 투표 과정을 지배하면 성능이 최적의 상태 그 이하로 떨어지는 경우가 발생한다.
추론 경로의 품질을 평가하기 위해 next token의 분포를 활용하는게 최근 연구의 추세인데, 일반적으로 높은 예측의 confidence는 낮은 엔트로피와 낮은 불확실성과 상관관계가 있다. 기존 방법은 token 단위의 엔트로피와 confidence 점수를 집계하여 전체 추론 trace의 global confidence를 계산하고, 이를 통해 저품질 trace를 식별하고 filtering해 voting 성능을 개선하였다. 그러나 이 방법도 한계가 있다.
- local 추론 단계에서 발생하는 confidence의 변동을 가려 trace 품질 추정에 필요한 신호를 놓칠 수가 있다.
- global cofidence 측정은 전체 추론 trace가 완성된 후 계산이 가능하기 때문에, 저품질의 trace를 early stopping할 수가 없다.
이러한 문제를 해결하기 위해 Deep Think with Confidence를 본 연구에서 제안한다. local confidence를 기반으로 병렬 추론과 confidence aware filtering을 결합하는 방법이다. 이는 offline, online의 두 모드에서 작동할 수 있도록 제안한다. 이 방법은 최종 정확도를 유지하거나 향상시키면서 불필요한 토큰 생성을 줄인다고 한다.
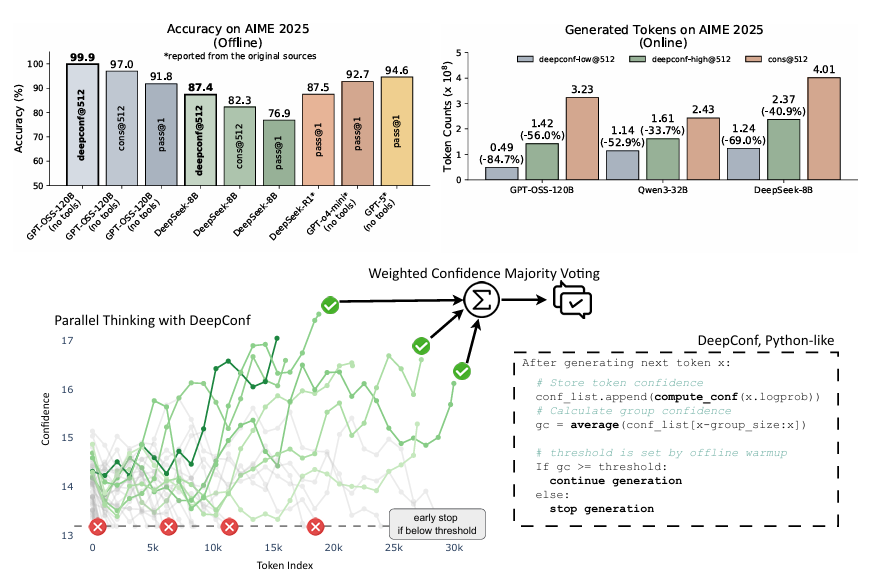
결과를 요약하면, DeepConf가 표준 다수결 방식보다 훨씬 적은 토큰으로 더 우수한 추론 성능을 달성함을 입증했다. 오프라인 모드에서 GPT-OSS-120B를 사용한 DeepConf@512는 AIME 2025에서 99.9% 정확도를 기록했으며, cons@512(97.0%), pass@1(91.8%)보다 높았다. 온라인 모드에서는 표준 병렬 추론 대비 토큰 생성을 최대 84.7% 줄이면서도 정확도를 유지하거나 초과하였다.
Method
DeepConf 의 핵심은 모델 내부 confidence 신호를 활용해 저품질의 추론 trace를 filtering하거나 early stopping하는 것이라고 한다.
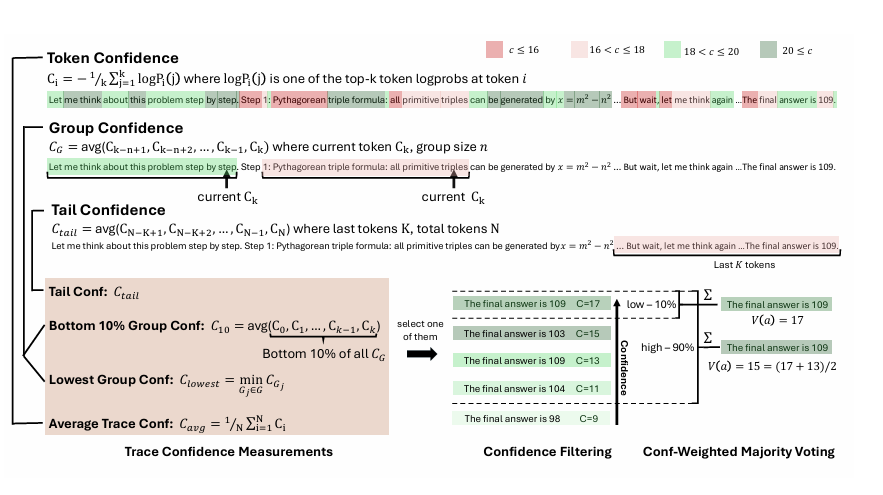
CONFIDENCE MEASUREMENTS
Group Confidence
중간 추론 단계의 confidence를 Group Confidence로 정의한다. Group Confidence는 토큰 단위의 confidence를 겹치는 구간 단위로 평균내어 더 국소적인 신호를 제공한다. 각 토큰은 크기가 n(e.g. n=1024 or 2048)인 이전 토큰들로 이루어진 슬라이딩 윈도우 그룹에 속한다.
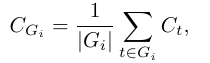
추론 trace의 품질을 평가하기 위해서는 그룹 confidence으로부터 신호를 집계해야 한다. 추론 과정에서 매우 낮은 확신도를 보이는 중간 단계가 최종 해답의 정확성에 큰 영향을 미친다는 점을 발견했다고 한다. 예를 들어, “wait”, “however”, “think again”과 같이 낮은 확신도를 가진 토큰들이 반복적으로 등장하면, 추론의 흐름이 깨지고 이후 단계에서 오류로 이어지는 현상을 발견했다고 한다.
Bottom 10% Group Confidence
추론 과정에서 극도로 낮은 확신도 구간의 영향을 포착하기 위해, Bottom 10% Group Confidence를 정의한다.
이는 하나의 trace 안에서 가장 낮은 10% 그룹들의 평균 확신도로 계산된다
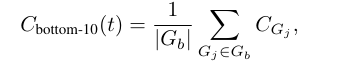
실험적으로, 10% 구간이 다양한 모델과 데이터셋에서 가장 문제가 되는 추론 구간을 잘 포착한다는 사실을 확인했다.
Lowest Group Confidence
Lowest Group Confidence는 Bottom 10%의 특수한 경우로, 가장 낮은 하나의 그룹 확신도만을 사용한다
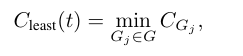
여기서 는 trace 전체의 그룹 집합이다.
이 지표는 특히 온라인 추론에서 조기 종료(early stopping)를 위한 효율적 기준으로 사용된다.
Tail Confidence
Group 기반 측정을 넘어, Tail Confidence라는 지표도 제안한다.
이는 reasoning trace의 마지막 구간에 집중하여, 결론부의 신뢰도를 평가한다.
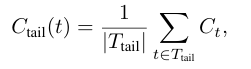
은 마지막 일정 길이(e.g. 2048 토큰)의 집합이다.
이 지표의 동기는, 긴 chain-of-thought에서 끝부분 reasoning 품질이 흔히 저하되며, 결론부 오류가 전체 정답을 망친다는 관찰에서 출발했다. 특히 수학적 추론에서는 마지막 단계의 결론이 정확도에 결정적이다.
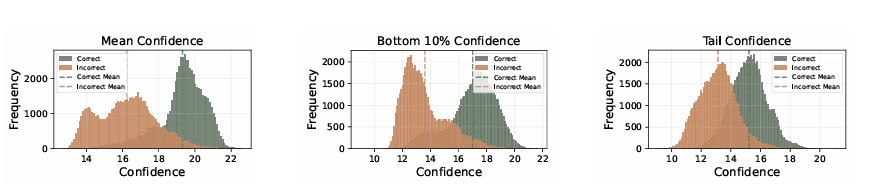
Figure 2 (논문 p.3) 비교에 따르면, Bottom 10% Confidence와 Tail Confidence가 단순 평균 confidence보다 정답/오답 구분 성능이 더 우수하다. 따라서 trace 품질 평가에 더 효과적이다.
OFFLINE THINKING WITH CONFIDENCE
오프라인 세팅에서는 문제별로 여러 개의 reasoning trace가 이미 생성되어 있다.
핵심 과제는 이 여러 trace들로부터 정보를 효과적으로 집계(aggregation) 하여 최종 답변을 더 정확히 결정하는 것이다.
Majority Voting
기본적인 방식은 다수결 투표이다.
각 trace의 최종 답변이 모두 동등하게 취급되어, 가장 많이 등장한 답변이 최종 결과로 선택된다.
여기서 는 전체 trace 집합, 는 indicator 함수이다.
Confidence-Weighted Majority Voting
일반적인 다수결과 달리, 각 trace의 확신도(confidence)에 비례하는 가중치를 부여한다.
여기서
는 해당 trace의 confidence 점수이다.
이렇게 하면 확신도가 높은 trace가 결과에 더 큰 영향을 미치게 되어, 불확실하거나 저품질 trace의 영향을 줄일 수 있다.
Confidence Filtering
Confidence-Weighted Voting을 적용하기 전에, Confidence Filtering으로 아예 저품질 trace를 제거한다.
-
상위 n% trace만 남기고 나머지를 버림.
-
두 가지 설정 제공: n = 10% / n = 90%
-
Top 10% (Aggressive)
극도로 확신도가 높은 trace만 사용. 적은 수의 trace만으로도 높은 정확도를 기대할 수 있음. 하지만, 모델이 잘못된 답에 과신하는 경우 오답 위험 증가. -
Top 90% (Conservative)
대부분의 trace를 포함하면서도 확신도가 낮은 일부는 제거. 다양성을 유지하고 모델 bias를 줄임. 안정적인 결과를 보장하지만, Top 10%만큼 공격적인 성능 향상은 어려움.
ONLINE THINKING WITH CONFIDENCE
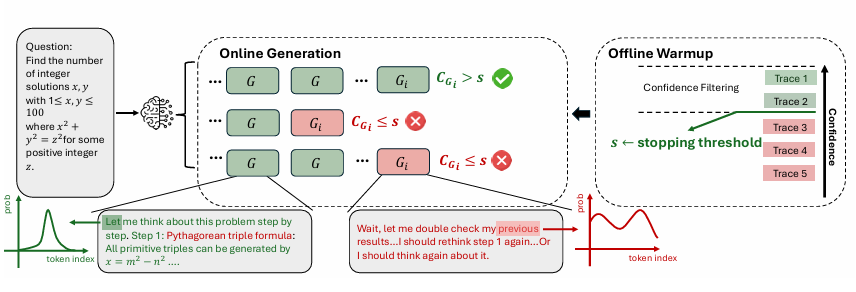
온라인 세팅에서는 추론이 진행되는 동안 실시간으로 confidence를 평가하여, 품질이 낮은 trace를 조기에 종료할 수 있다.
이는 특히 자원이 제한된 환경이나 빠른 응답이 필요한 상황에서 매우 유용하다.
여기서는 Lowest Group Confidence를 활용해 online control을 수행한다.
특정 구간의 confidence가 기준치 이하로 떨어지면 trace 생성을 멈춘다.
DeepConf-low & DeepConf-high
두 가지 온라인 알고리즘을 제안한다:
- DeepConf-low: 상위 10%의 trace만 유지 (공격적, 토큰 절약 극대화)
- DeepConf-high: 상위 90%의 trace를 유지 (보수적, 안정적 정확도 보장)
Offline Warmup
온라인 모드에 들어가기 전, 먼저 offline warmup 단계가 필요하다.
- 새로운 프롬프트마다 개(예: 16개)의 trace를 완전히 생성.
- 이들의 confidence 분포를 기준으로 stopping threshold 를 계산
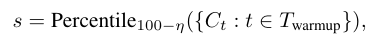
- : warmup trace 집합
- → DeepConf-low (상위 10% 유지 → 90th percentile)
- → DeepConf-high (상위 90% 유지 → 10th percentile)
이렇게 설정된 threshold는 이후 online generation에서 confidence < s 인 trace를 조기 종료시키는 기준이 된다.
Adaptive Sampling
DeepConf는 문제 난이도에 따라 trace 수를 동적으로 조절(adaptive sampling) 한다.
- 난이도는 trace들 간의 합의(consensus) 수준으로 평가된다.
- 정의:
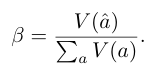
여기서
- : 현재 다수결 최다 득표 답변의 가중치
- : 전체 가중치 합
조건:
- (합의 부족) → 더 많은 trace를 생성 (최대 budget 까지).
- (충분한 합의) → 생성 중단, 현재 결과를 최종 답변으로 확정.
특징
- 충분히 큰 warmup set을 사용하면 threshold 의 추정이 정확해진다.
- 따라서 online에서 조기 종료된 trace는 offline filter에서도 어차피 제외될 trace에 해당한다.
- 결과적으로, online 방법은 offline 정책을 근사하며, 이 증가할수록 offline 성능에 가까워진다.
Figure 4 (논문 p.6) 은 online generation 과정에서 confidence drop → trace 조기 종료되는 흐름을 시각화한다.
Results
Experimental Setup
모델: DeepSeek-8B, Qwen3-8B, Qwen3-32B, GPT-OSS-20B, GPT-OSS-120B
데이터셋: AIME24, AIME25, BRUMO25, HMMT25, GPQA
비교 기준:
Pass@1 (단일 trace 정확도)
Cons@K (majority voting)
Measure@K (confidence-weighted voting)
Measure+top-η%@K (confidence filtering, η=10%/90%)
Offline Evaluations
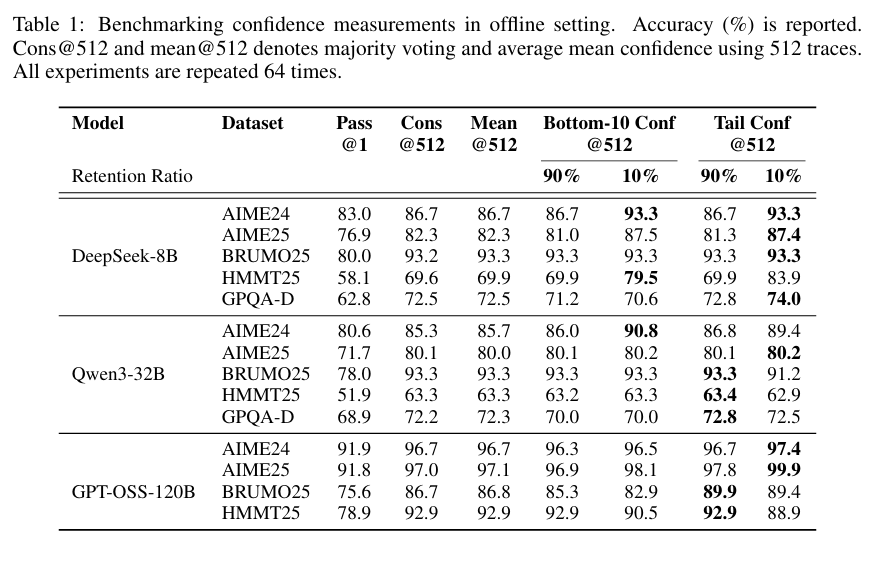
Confidence-aware weighting + filtering → 항상 Cons@512 (majority voting)보다 우수.
Top 10% filtering (Aggressive): 가장 큰 성능 향상.
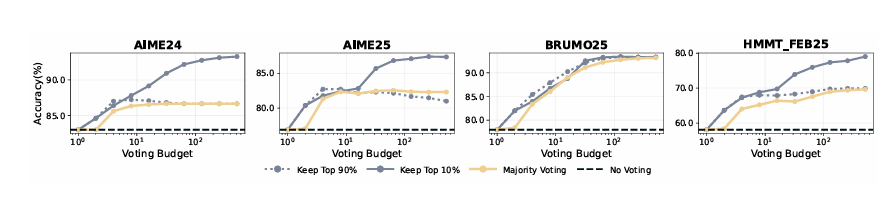
DeepSeek-8B @ AIME25 → 82.3% → 87.4%
Qwen3-32B @ AIME24 → 85.3% → 90.8%
GPT-OSS-120B @ AIME25 → 97.0% → 99.9%
Top 90% filtering (Conservative): 안정성↑, 성능 소폭 개선.
결론: Bottom-10%, Tail, Mean 모두 효과적이나, Bottom-10% & Tail Confidence가 특히 잘 구분.
Online Evaluations
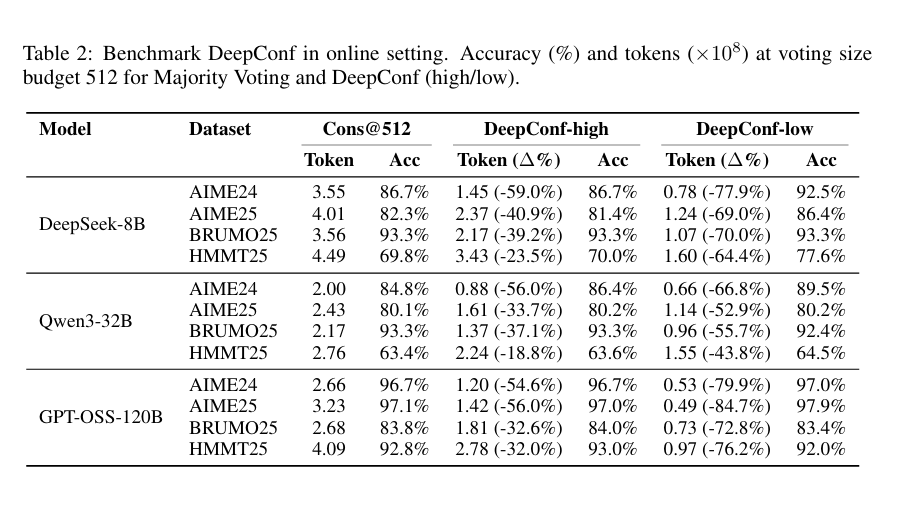
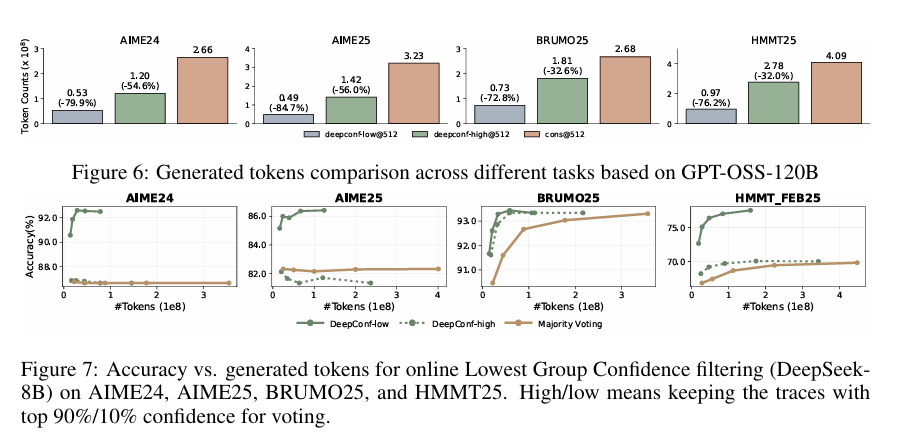
DeepConf-low (Top 10%)
토큰 사용량 43~79% 절감, 정확도는 대체로 유지/개선.
예: DeepSeek-8B @ AIME24 → +5.8% 정확도, -77.9% 토큰
일부 세팅에서는 성능 하락 (예: Qwen3-32B @ BRUMO25: -0.9%)
DeepConf-high (Top 90%)
토큰 사용량 18~59% 절감, 정확도 거의 동일.
GPT-OSS-120B 결과:
토큰 절감 최대 85.8%, 정확도는 baseline 수준 유지.
DeepSeek-8B 결과:
DeepConf-low: 평균 62.9% 토큰 절약
DeepConf-high: 평균 47.7% 토큰 절약
핵심 인사이트
Offline: Confidence filtering (특히 Top 10%) → 정확도 크게 상승.
Online: Lowest Group Confidence + Adaptive Sampling →
대규모 토큰 절약 (최대 85.8%)
정확도는 offline baseline에 근접.
Trade-off:
Aggressive(Top 10%) = 효율↑, 때때로 정확도↓
Conservative(Top 90%) = 안정적 정확도 유지
Discussion and conclusion
Future Work
-
강화학습(RL) 적용
- DeepConf의 confidence 기반 early stopping을 RL 탐색 과정에 적용 → 정책 탐색 효율 및 샘플 효율 개선 가능.
-
잘못된 추론에 대한 과신 문제
- 모델이 틀린 reasoning path에도 높은 confidence를 부여하는 경우가 있음 → 주요 한계.
- 이를 완화하기 위해 더 견고한 confidence calibration 기법 및 불확실성 정량화(uncertainty quantification) 필요.
Conclusion
-
DeepConf 제안: 간단하지만 효과적인 방법으로,
- 추론 성능(accuracy) 향상
- 계산 효율(token 절감) 두 가지를 동시에 달성.
-
실험 결과:
- 다양한 reasoning LLM (8B ~ 120B) & 난도 높은 데이터셋에서 검증.
- 정확도 대폭 향상 (예: AIME25에서 99.9% 달성).
- 토큰 사용량 최대 85% 이상 절감.
-
의의:
- Test-time compression의 가능성을 보여줌.
- 효율적이고 확장 가능한 LLM reasoning을 위한 실용적 솔루션으로 자리매김.
