[논문리뷰] TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS
Paper Review

Introduction
배경
-
시계열 예측(time series forecasting)은 수요 예측, 재고 관리, 에너지 부하 예측, 기후 모델링 등 다양한 실제 시스템에서 핵심적인 역할을 한다. 그러나 기존 시계열 모델들은 특정 도메인 혹은 Task에 맞춰 개별적으로 설계되기 때문에 범용성이 부족하다. 따라서 더 일반화된 접근 방식을 찾는 것이 중요하다.
-
NLP와 CV 분야에서는 GPT-3, GPT-4, LLaMA와 같은 대규모 언어 모델이 등장하여 범용적 성능과 few-shot, zero-shot 학습 능력을 보여주었다. 그러나 시계열 분야는 데이터 부족 문제로 인해 이러한 발전이 더디다. 따라서 LLM의 강점을 시계열 예측에 어떻게 적용할 수 있을지가 중요하다.
- LLM은 transfer learning을 통한 generalizability, data efficiency, reasoning, multimodal knowledge, easy optimization 등 여러 이점을 갖고 있다. 따라서 이러한 능력을 시계열 예측에 활용할 수 있다면 기존 특화 모델의 한계를 극복할 수 있다는 점에서 중요하다.
문제점
- 하지만 LLM은 discrete token을 기반으로 동작하는 반면 시계열은 연속 데이터이기 때문에 양자 간의 alignment가 어렵다. 또한 LLM은 시계열 지식을 사전에 학습하지 않았기 때문에 단순히 적용하기 어렵다. 따라서 새로운 정렬 방식을 고안하는 것이 중요하다.
제안
- 본 연구에서는 시계열 데이터를 텍스트 프로토타입(text prototypes)으로 재구성하는 Reprogramming 기법과, 도메인 지식 및 태스크 설명을 자연어로 추가하는 Prompt-as-Prefix (PaP) 기법을 제안한다. 이를 통해 LLM의 reasoning 능력을 강화하고, 최종 출력은 다시 시계열 값으로 투영한다. 따라서 TIME-LLM은 LLM을 시계열 예측기로 재활용할 수 있도록 하는 중요한 방법론이다.
기여점 요약
-
시계열을 언어 과제로 재정의하여 LLM이 활용 가능함을 보였다. 이는 시계열 예측을 또 다른 “언어 태스크”로 보는 관점을 제공한다는 점에서 중요하다.
-
Prompt-as-Prefix 기법을 통해 LLM의 reasoning을 강화하여 시계열 예측 성능을 높였다. 이는 LLM 활용의 새로운 가능성을 보여준다는 점에서 중요하다.
-
다양한 벤치마크에서 최신 특화 모델보다 우수한 성능을 보였으며, 특히 few-shot과 zero-shot 상황에서도 강력한 성능을 달성했다. 이는 LLM의 잠재력을 실질적으로 입증했다는 점에서 중요하다.
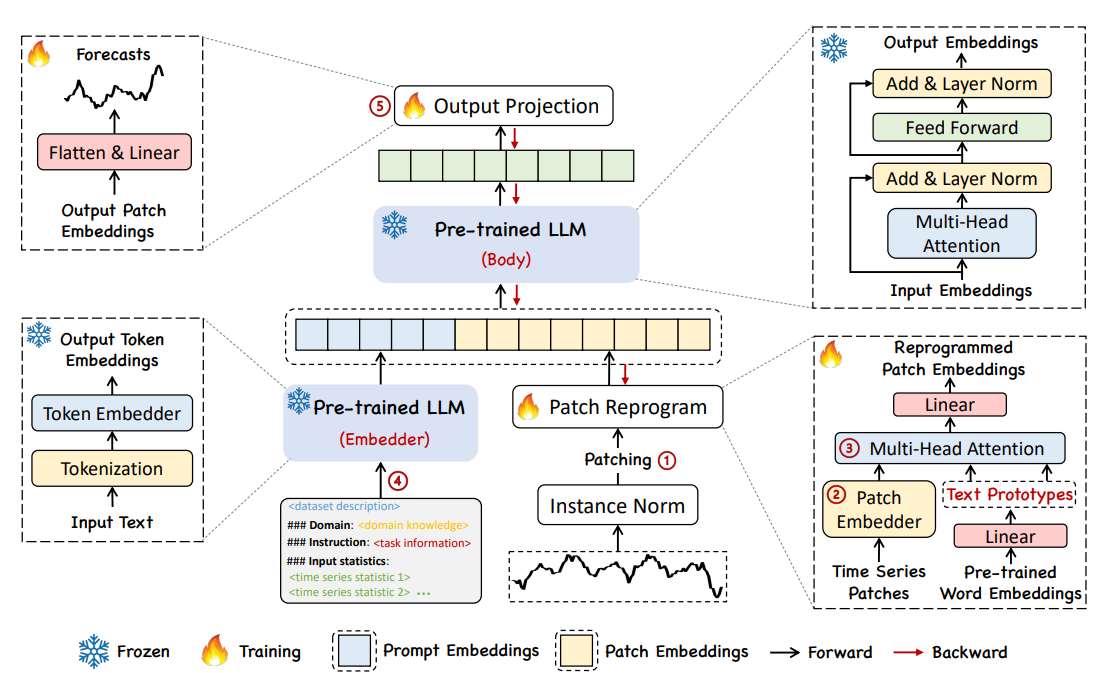
Method
TIME-LLM은 Reprogramming + Prompt-as-Prefix라는 두 가지 핵심 아이디어를 통해, 동결된 LLM을 그대로 시계열 예측기로 활용할 수 있도록 한다. 전체 구조는 Input Transformation → Frozen Backbone → Output Projection 세 단계로 구성된다.
1. Input Transformation
-
정규화 (Normalization)
각 시계열 채널 은 분포 차이를 줄이기 위해 Reversible Instance Normalization (RevIN)을 거친다.- 평균 0, 표준편차 1로 변환하여 데이터셋 간 분포 차이를 보정한다.
-
패칭 (Patching)
정규화된 시계열을 길이 의 패치 단위로 잘라 토큰화한다.-
겹치거나(non-overlapping/overlapping) 슬라이딩 윈도우 방식으로 분할 가능하다.
-
입력 길이가 라면, 총 패치 개수는
여기서 는 stride이다.
-
목적: (1) 지역적 의미 보존, (2) 토큰 수 축소로 연산 효율 향상.
-
-
패치 임베딩 (Patch Embedding)
각 패치를 linear patch embedder를 통해 차원 벡터로 변환한다.
2. Patch Reprogramming
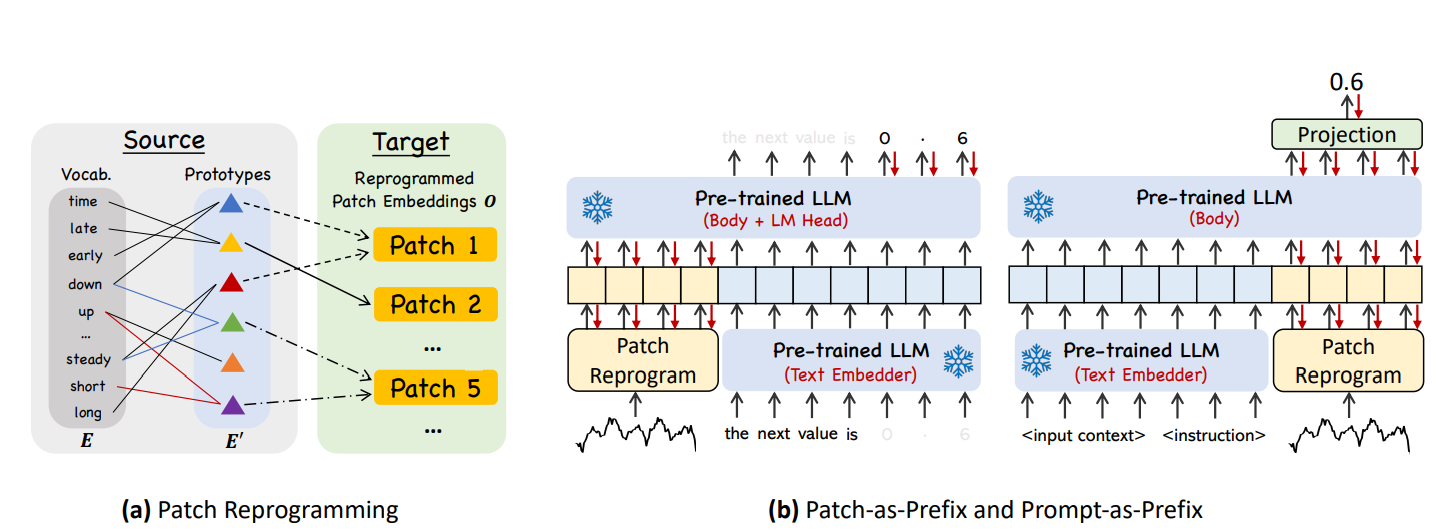
아이디어
시계열 패치를 LLM의 언어 임베딩 공간으로 정렬(alignment)하는 과정.
- 기존 LLM 임베딩 공간은 텍스트 토큰 기반 → 시계열 패치를 직접 매핑하기 어려움.
- 따라서 text prototypes을 학습하여 브릿지 역할을 하게 함.
텍스트 프로토타입 (Text Prototypes)
- LLM의 거대한 단어 임베딩 에서 직접 사용하지 않고,
- 소수의 대표 임베딩 ()를 선형 탐색(linear probing)으로 선택.
- 예: "short up", "steady down" 같은 언어적 표현이 시계열 패턴을 대표하도록 학습됨.
크로스 어텐션 기반 변환
-
Query: 패치 임베딩
-
Key/Value: 텍스트 프로토타입
-
다중 헤드 크로스 어텐션을 적용하여 패치를 텍스트 공간으로 변환:
-
모든 헤드를 모아 최종적으로 생성.
-
이를 다시 선형 변환해 LLM hidden dimension 와 맞춘다.
3. Prompt-as-Prefix (PaP)

문제점
단순히 "Patch-as-Prefix" 방식(시계열을 자연어로 바꿔 LLM에 입력)으로는 수치 예측이 어렵다.
- LLM은 고정밀 숫자 처리에 약하다.
- 모델별 토큰화 방식 차이 때문에 후처리가 복잡하다.
해결책 (Prompt-as-Prefix)
시계열 입력과 함께 자연어 지식과 태스크 설명을 프롬프트 접두(prefix)로 제공한다.
프롬프트 구성 요소
- Dataset context: 데이터셋의 의미 (예: ETT 데이터는 변압기 온도와 전력 부하 기록).
- Task instruction: 수행할 예측 작업에 대한 지시문 (예: "이전 96 스텝을 기반으로 다음 96 스텝을 예측하라").
- Input statistics: 시계열의 기초 통계 (최소/최대/중앙값, 추세, 상위 지연값(lags)).
효과
- 프롬프트는 LLM이 시계열 패치를 처리할 때 추론 경로(reasoning path)를 제공.
- 단순 수치 나열보다 맥락적이고 해석 가능한 방식으로 예측을 유도한다. 중요하다.
4. Output Projection
- LLM의 출력을 받아 프롬프트 부분을 제거하고, 시계열 패치에 해당하는 출력만 추출한다.
- 이를 평탄화(flatten)한 후 선형 변환(linear projection)하여 최종 예측값 을 생성한다.
- 학습 시 MSE 손실을 최소화하도록 최적화한다.
Main Results
TIME-LLM은 여러 벤치마크와 설정에서 SOTA 모델들을 큰 폭으로 능가하며, 특히 few-shot과 zero-shot 시나리오에서 두드러진 성능을 보였다. 기본 백본 모델은 Llama-7B를 사용했다.
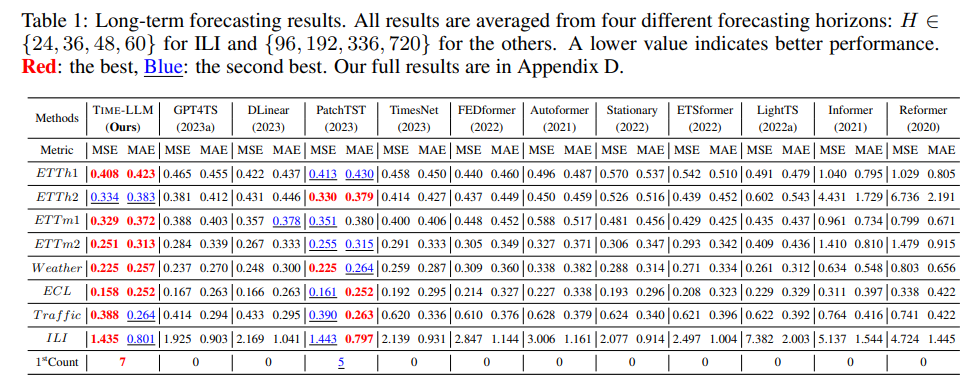
Setups
장기 예측 모델의 벤치마크로 널리 사용되는 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity(ECL), Traffic, ILI 데이터셋을 사용하여 평가를 진행하였다 입력 시계열 길이
는 512로 설정하였고, 예측 구간은 {96, 192, 336, 720} 네 가지로 구성하였다. 평가 지표는 MSE와 MAE를 사용하였다.
Results
표 1에 요약된 결과에서 볼 수 있듯, TIME-LLM은 대부분의 경우 모든 베이스라인을 넘기며, 그중 상당수에서는 통계적으로 유의미한 성능 향상을 보였다. 특히 GPT4TS와의 비교가 주목할 만하다. GPT4TS는 백본 언어 모델을 파인튜닝하는 방식을 사용한다. 이에 비해 TIME-LLM은 GPT4TS 대비 평균 12%, TimesNet 대비 평균 20% 성능 향상을 기록하였다. 또한 최신 Transformer 기반 시계열 모델인 PatchTST와 비교했을 때, 가장 작은 규모의 LLaMA를 단순히 재프로그래밍만 했음에도 평균 MSE에서 1.4% 개선을 달성하였다. DLinear와 같은 다른 모델들과 비교했을 때도 12% 이상의 성능 향상이 확인되었다.
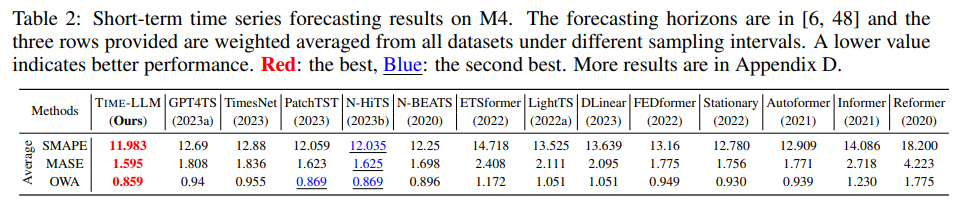
Setups
M4 벤치마크를 사용하였다. 이 데이터셋은 다양한 주기(연간, 분기별, 월간, 주간 등)로 수집된 마케팅 데이터를 포함한다. 예측 구간은 [6, 48] 범위이며, 입력 길이는 예측 구간의 두 배로 설정하였다. 평가지표로는 대칭 SMAPE, MASE, OWA을 사용하였다.
Results
TIME-LLM은 모든 베이스라인을 일관되게 초월했으며, GPT4TS 대비 8.7% 개선된 성능을 기록했다. 또한 최상위 성능을 보이는 N-HiTS와 비교했을 때도 MASE와 OWA 지표에서 경쟁력을 유지하였다.
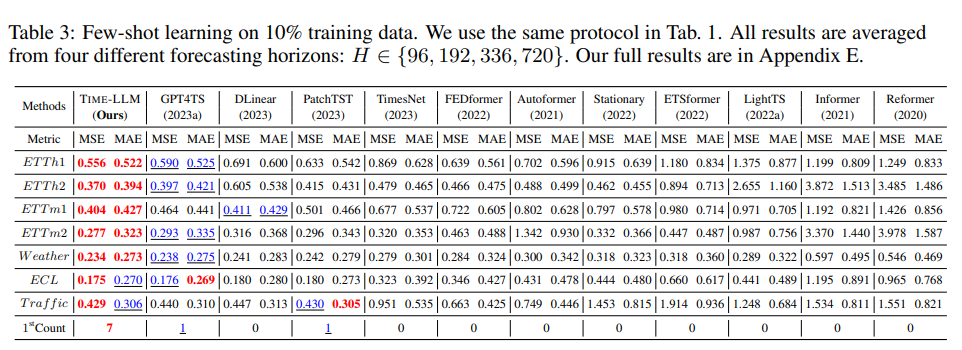
Setups
훈련 데이터의 10% 이하만을 사용하는 상황에서 평가를 진행하였다.
Results
TIME-LLM은 모든 베이스라인을 초월하였다.
- 10% 데이터 사용 시: GPT4TS 대비 MSE 5% 감소
- PatchTST, DLinear, TimesNet 대비 각각 8%, 12%, 33% 향상
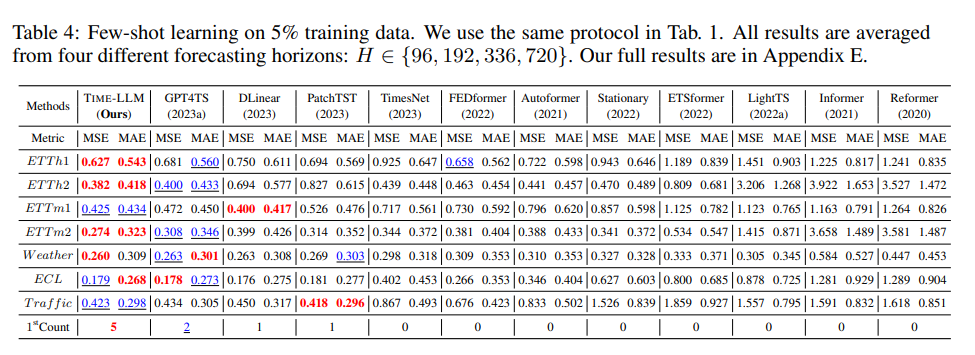
- 5% 데이터 사용 시: GPT4TS 대비 5% 이상 개선, 다른 최신 모델들보다 평균 20% 이상 향상
이는 TIME-LLM이 소량 데이터 환경에서도 강력한 예측 성능을 발휘함을 보여준다.
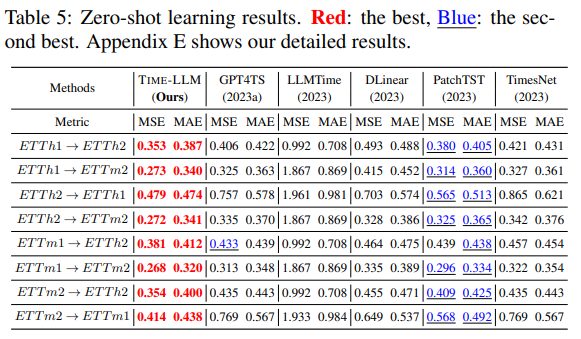
Setups
훈련 데이터가 전혀 없는 상태에서, 한 데이터셋에서 학습한 모델을 다른 데이터셋으로 cross-domain adaptation하여 평가하였다. ETT 계열 데이터셋 간 전이 실험을 수행하였다.
Results
TIME-LLM은 다른 최신 모델들을 큰 폭으로 초월했다. 두 번째로 좋은 성능을 기록한 모델 대비 평균 14.2% 이상의 MSE 감소를 보였다. 특히 GPT4TS와 비교했을 때, few-shot 실험에서는 7.7~8.4% 개선을 보였던 반면 zero-shot에서는 22% 개선을 기록하였다. 이는 데이터 부족 상황일수록 TIME-LLM의 우위가 더욱 두드러짐을 의미한다. LLMTime과 비교해도 75% 이상의 성능 향상을 보였다.
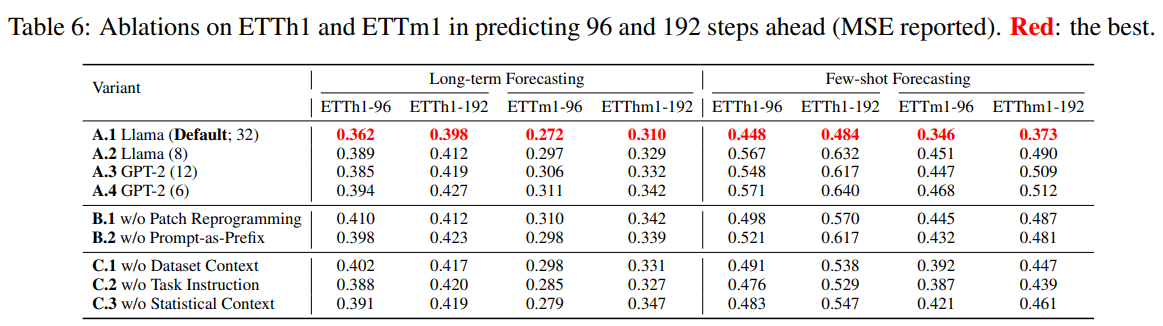
Model Analysis
Language Model Variants
다양한 LLM 백본(LLaMA, GPT-2 등)을 비교한 결과, LLaMA-7B가 가장 뛰어난 성능을 보였다. LLM 크기가 커질수록 성능이 개선되는 경향이 확인되었다.
Cross-modality Alignment
Patch Reprogramming이나 Prompt-as-Prefix를 제거하면 성능이 크게 저하되었다. 특히 few-shot 환경에서는 17% 이상의 성능 하락이 발생하였다.
Reprogramming Interpretation
입력 통계(statistical context), 태스크 지시문, 데이터셋 설명을 각각 제거했을 때 모두 성능이 저하되었으며, 특히 통계 정보를 제외했을 때 평균 MSE가 10% 이상 악화되었다. 이는 프롬프트 설계가 모델 성능에 직접적으로 기여함을 보여준다.
텍스트 프로토타입 학습 과정을 시각화한 결과, 특정 소수의 프로토타입만이 실제 시계열 패치를 표현하는 데 활용되었으며, 이들이 시계열 패턴(예: 주기성, 추세)을 언어적으로 요약하는 역할을 한다는 점을 확인하였다.
Reprogramming Efficiency
TIME-LLM의 추가 학습 파라미터는 약 6.6M으로, 전체 LLaMA-7B 파라미터의 0.2% 수준에 불과하다. 이는 QLoRA와 같은 파라미터 효율적 파인튜닝 방법보다도 더 높은 효율성을 보였다.
Conclusion
결론
TIME-LLM은 시계열 데이터를 텍스트 프로토타입으로 재프로그래밍하고, Prompt-as-Prefix를 통해 자연어 기반 지침을 제공함으로써, frozen LLM을 효과적인 시계열 예측기로 전환할 수 있음을 보여주었다. 실험 결과, TIME-LLM은 기존의 특화된 전문가 모델들을 초월하는 성능을 기록했으며, 이를 통해 시계열 예측을 또 하나의 “언어 태스크”로 재정의할 수 있음을 입증하였다. 이러한 결과는 LLM이 언어뿐만 아니라 시계열과 같은 순차적 데이터 처리에도 강력한 잠재력을 가지고 있음을 시사한다.
