
서론
LLM은 일반 도메인에서 뛰어난 성능을 보이며 현재 법률과 같은 전문 도메인으로 확장되고 있다. 기존 법률 벤치마크는 LLM의 법률 능력을 평가하기 위해 제안되었으나, open-ended 및 provision-grounded QA을 평가하는 데에는 한계가 있었다. 특히 복잡한 법률 질문은 실제 법률 조문에 근거한 답변을 요구하지만, 기존 벤치마크는 주로 객관식 또는 이진 형식에 의존하며 명시적인 법률 조문 연결이 부족했다. 이는 hallucination 또는 부정확한 정보가 심각한 결과를 초래할 수 있는 법률 도메인에서 중요한 문제이다. 이러한 한계를 해결하기 위해 본 논문은 provision-grounded, multi-hop legal reasoning을 평가하도록 설계된 한국어 법률 설명 가능 QA 벤치마크인 KOBLEX를 소개한다. KOBLEX는 226개의 시나리오 기반 QA 인스턴스와 이를 뒷받침하는 조문들로 구성되며, 하이브리드 LLM-인간 전문가 파이프라인을 통해 구축되었다. 또한, 법률적으로 근거 있고 신뢰할 수 있는 답변을 유도하기 위해 LLM 생성 parametric provisions를 사용하는 Parametric provision-guided Selection Retrieval (PARSER) 방법을 제안한다. PARSER는 parametric provisions를 생성하고 3단계 순차적 검색 프로세스를 사용하여 복잡한 법률 질문에 대한 multi-hop reasoning을 용이하게 한다. 나아가, 생성된 답변의 legal fidelity를 더 잘 평가하기 위해 질문, 답변, supporting provisions를 종합적으로 고려하는 자동 지표인 Legal Fidelity Evaluation (LF-EVAL)을 제안한다. LF-EVAL은 인간 판단과의 높은 상관관계를 보인다. 실험 결과, PARSER는 강력한 베이스라인보다 지속적으로 우수한 성능을 보이며, 여러 LLM에 걸쳐 최고 결과를 달성한다. 특히, GPT-4o를 사용한 표준 검색과 비교할 때 PARSER는 F-1에서 37.91, LF-EVAL에서 30.81 높은 성능을 보인다. 추가 분석에 따르면 PARSER는 추론 깊이에 관계없이 일관된 성능을 효율적으로 제공하며, ablation study는 PARSER의 효과성을 입증한다.
본 논문의 주요 기여는 다음과 같다.
- KOBLEX: LLM과 인간 검증 파이프라인을 통해 구축된 226개의 provision-grounded, multi-hop legal QA 인스턴스로 구성된 한국어-영어 이중 언어 벤치마크를 소개한다.
- PARSER: LLM 생성 parametric provisions와 3단계 검색 파이프라인을 결합한 방법으로, 기존 검색 증강 추론 베이스라인을 여러 LLM에서 크게 능가한다.
- LF-EVAL: 생성된 답변의 법률적 정확성 및 provision 정합성을 평가하는 데 탁월한 법률 충실도 평가 지표를 제안한다.
- 실험 및 분석: PARSER의 모델, 지표, 추론 깊이에 걸친 효과성 및 효율성을 입증한다.
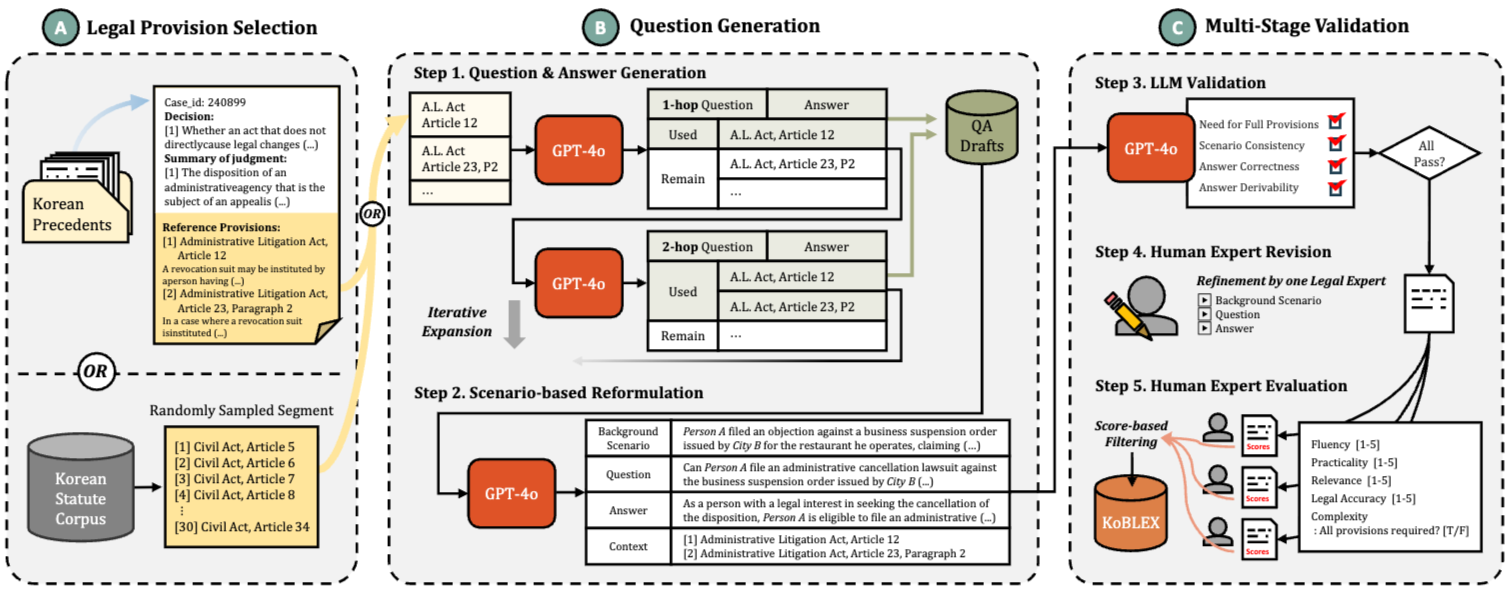

KOBLEX 데이터셋
KOBLEX는 open-ended, provision-grounded 법률 QA를 평가하기 위해 구축되었다.
구축 과정
1. Legal Provision Selection (3.1절): 한국어 법령 코퍼스에서 무작위로 연속적인 조문 세그먼트를 샘플링하거나, 실제 한국 판례에 인용된 참조 조문들을 추출하여 법률 콘텐츠를 선정한다. 이 두 가지 방식은 질문의 다양성을 보장한다.
2. Question Generation (3.2절):
Question & Answer Generation: GPT-4o를 사용하여 단일 조문을 기반으로 하는 single-hop 질문-답변 쌍을 생성한다. 이후 이 single-hop 질문을 기반으로 추가 조문들을 논리적으로 통합하여 2-hop 및 3-hop 버전으로 점진적으로 확장한다.
Scenario-based Reformulation: 생성된 각 QA 초안을 GPT-4o를 사용하여 사실 기반의 법률 시나리오(예: Person A, Person B 등 익명화된 주체 사용)로 재작성하여 현실적인 multi-hop reasoning을 유도한다. 이 과정을 거쳐 각 QA 인스턴스는 Background Scenario (B), Question (Q), Answer (A), Context (C) (참조 법률 조문 집합)의 네 가지 구성 요소로 구조화된다.
3. Multi-Stage Validation (3.3절):
LLM Validation: GPT-4o를 평가자로 활용하여 인간 검증 전 부정확한 QA 샘플을 필터링한다.
Partial Check: 질문 (Q)이 Context (C)의 모든 조문 세트를 진정으로 요구하는지 평가한다. C의 비어있지 않은 부분 집합으로 답변 가능한 경우 해당 인스턴스는 true multi-hop 특성이 부족하다고 간주하여 제외한다.
Full Check: (B, Q, A) 삼중항의 일관성을 포괄적으로 검증한다. 이는 (1) 시나리오 일관성(Scenario consistency): (B, Q)가 C와 논리적/법률적으로 일관되는지, (2) 답변 정확성(Answer correctness): A가 C의 법령 해석과 일치하는지, (3) 답변 도출 가능성(Answer derivability): A가 C로부터 어떠한 추가 가정 없이 완전히 추론될 수 있는지 등을 포함한다.
Human Expert Revision: LLM 검증을 통과한 QA 인스턴스는 한국 법학 전문대학원 졸업생 및 학생들에 의해 법률적 정확성, 명확성, 언어적 유창성 측면에서 수정 및 검증된다. 'Pass', 'Revise', 'Hold'로 분류되며, 수정이 필요한 인스턴스는 적절히 교정된다.
* Human Expert Evaluation: 수정 후, 3명의 법률 전문가가 각 QA 인스턴스를 Fluency, Practicality, Relevance, Legal Accuracy, Complexity의 5가지 기준으로 평가한다. Fluency, Practicality, Relevance, Legal Accuracy는 5점 Likert 척도로, Complexity는 이진(True/False)으로 평가한다. 이 평가를 통과한 인스턴스만이 최종 데이터셋에 포함된다.
데이터 통계
KOBLEX는 226개의 고품질 QA 인스턴스로 구성된다. Table 1에 따르면, 1-hop 55개, 2-hop 125개, 3-hop 46개로 이루어져 있다. 추론 깊이가 증가함에 따라 각 QA 구성 요소의 평균 단어 수가 일관되게 증가하며, 이는 multi-hop 법률 추론에 수반되는 언어적, 논리적 복잡성이 더 크다는 점을 명확히 반영한다. 최종 벤치마크는 민법, 형법, 형사소송법 등 83개의 고유한 한국어 법령을 포함한다. 226개 QA 인스턴스 중 153개는 한국 법원 판결에서 추출된 참조 조문을 사용하여 생성되었고, 나머지 73개는 한국 법령 코퍼스의 무작위 샘플링된 세그먼트에서 구축되었다. 5가지 평가 차원에 걸친 전반적인 평균 점수는 Fluency 4.385, Practicality 4.435, Relevance 4.540, Legal Accuracy 4.515, Complexity 0.915이다. 평가자 간 동의율은 96%에 달한다(3명의 전문가 중 최소 2명이 일관된 라벨 부여).
영문 버전의 KOBLEX
KOBLEX는 한국어 데이터만 제공하는 기존 한국어 법률 벤치마크와 달리, 더 넓은 접근성과 다국어 연구를 촉진하기 위해 영어 번역 버전을 제공한다. B, Q, A는 GPT-4o를 사용하여 번역되었고, 법률 조문 C는 주로 한국법제연구원(KLRI)이 제공하는 고품질 공식 번역에 기반한다. 공식 소스에서 다루지 않는 일부 조문은 GPT-4o를 통해 번역되었으며, %MACHINE_TRANSLATED% 태그로 표시된다.

PARSER 방법론
본 논문은 복잡한 법률 질문에 대한 supporting legal provisions를 효과적으로 검색하도록 설계된 Parametric provision-guided Selection Retrieval (PARSER)를 소개한다.
-
Parametric Provision Generation (4.1절):
복잡한 법률 질문 (Q)은 여러 법률 조문에 대한 추론을 요구하는 경우가 많다. 그러나 LLM의 parametric knowledge에만 의존하는 것은 신뢰할 수 없는데, 환각(hallucination)에 취약하고 정확한 법률 텍스트를 기억하지 못할 수 있기 때문이다. 이를 해결하기 위해 실제 법령 코퍼스에 대한 검색을 통합하여 모델의 답변을 권위 있는 법률 텍스트에 기반을 둔다. Step 1 (Figure 4)에서 보듯이, LLM에게 multi-hop 법률 질문 (Q)으로부터 잠재적으로 관련 있는 조문 집합 ()을 생성하도록 지시한다. 여기서 은 생성된 parametric provisions의 수이다. 각 은 Q에 대한 추론을 지원할 수 있는 개별 법정 구성 요소를 반영한다. 은 오직 LLM의 parametric knowledge에 기반하여 생성되므로, 이를 parametric provisions라 부르며 중간 쿼리로만 사용한다. 이는 타겟 질문과 유사한 쿼리를 기반으로 검색을 활용할 수 있게 한다. -
Retrieve, Rerank, and Selection (4.2절):
검색 정확도를 향상시키기 위해 Bi-encoder 검색, Cross-encoder reranking, 그리고 LLM을 통한 Selection을 포함하는 새로운 3단계 검색 접근 방식을 제안한다. Step 2 (Figure 4)에서 보듯이, 각 parametric provision 은 쿼리로 사용되어 Bi-encoder retriever를 통해 코퍼스에서 상위 개의 가장 관련성 높은 법률 조문(Top-)을 검색한다. 각 에 대해 검색된 Top- 조문들은 Cross-encoder reranker를 사용하여 더 미세한 관련성을 포착하도록 rerank된다. reranking 후, Top- 조문들에서 Top- () 조문들을 선택한다. 그 다음, LLM에게 Top- 조문들 중에서 각 에 대해 가장 관련성이 높은 조문을 선택하도록 지시한다. 이 프로세스는 생성된 parametric provisions를 활용하여 신뢰할 수 있는 supporting legal provisions를 수집할 수 있게 한다. -
Question Answering (4.2절):
최종적으로, 수집된 supporting legal provisions는 LLM에 입력되어 provision-grounded reasoning을 통해 복잡한 multi-hop legal question을 해결하는 데 사용된다. 초기 단계에서 생성된 parametric provisions는 PARSER가 각 supporting provision 조각을 검색할 수 있도록 하여 multi-hop reasoning을 용이하게 한다.
LF-EVAL 평가 지표
KOBLEX는 LLM이 생성한 답변의 법률적 충실도를 평가하도록 설계된 벤치마크이다. 그러나 기존 평가 지표들은 이러한 답변의 법률적 정확성을 평가하는 데 실패하는 경우가 많다. 이를 해결하기 위해 본 논문은 법률적 충실도를 측정하기 위한 평가 프레임워크인 Legal Fidelity Evaluation (LF-EVAL)을 소개한다.
LF-EVAL은 대표적인 LLM-as-a-Judge 평가 접근 방식인 G-Eval (Liu et al., 2023)을 기반으로 구축되었다. KOBLEX의 인스턴스를 사용하여 답변을 참조 법률 조문 및 예상 답변과 비교하여 법률적 충실도를 평가한다. Figure 5는 LF-EVAL에 사용되는 프롬프트를 보여준다. 법률 질문에 답변하는 작업 설명 하에, LF-EVAL은 강력한 LLM judge를 사용하여 1-10점 척도로 점수를 부여한다. 평가는 다음과 같은 5가지 명확하게 정의된 단계를 따른다: Answer Relevance, Legal Consistency, Conclusion Accuracy, Context Fidelity, Avoid Generic Responses. 최종적으로 LF-EVAL은 스칼라 점수와 함께 5가지 평가 단계 각각에 맞춰 상세한 정당화를 생성한다. 이는 LF-EVAL이 신뢰할 수 있는 점수를 제공할 뿐만 아니라 해석 가능한 설명도 제공함을 시사한다.
LF-EVAL의 신뢰성을 평가하기 위해 KOBLEX에서 생성된 답변에 대한 인간 평가 연구를 두 개의 독립적인 annotator 그룹을 대상으로 수행했다. 결과에 따르면 LF-EVAL은 인간 판단과 Pearson 상관계수 84.90을 달성하여 기존 평가 지표들을 능가한다.
실험 설정
모델
본 연구는 Qwen3 (Team, 2025), EXAONE-3.5 (Research, 2024), GPT-4o (OpenAI et al., 2024)의 세 가지 LLM을 사용한다. 이 모델들은 강력한 한국어 이해 능력으로 선정되었다. BM-25 (Robertson and Zaragoza, 2009)를 retriever로, 한국어 데이터셋에 fine-tuned된 BGE (Chen et al., 2024)를 reranker로 사용한다. 오픈소스 모델인 Qwen3와 EXAONE 3.5는 vLLM (Kwon et al., 2023)을 사용하여 temperature 0, top-p 0.9의 nucleus sampling으로 실행되었다. GPT-4o는 OpenAI API를 통해 동일한 샘플링 파라미터로 사용되었다.
지표
KOBLEX는 복잡한 법률 질문을 해결하는 데 필요한 해당 법률 조문을 식별해야 하므로, LLM 성능 평가 시 검색 정확성과 생성 정확성 모두를 평가하는 것이 필수적이다.
- 검색 성능 (Retrieval Performance): 예측된 조문 세트와 gold 조문 세트 간의 조문 수준 일치를 비교하여 Exact Match (EM) 및 F-1 점수를 사용한다. 예측된 조문 세트를 , gold 조문 세트를 라고 할 때, EM 점수는 이면 1, 아니면 0이다. F-1 점수는 정밀도 , 재현율 를 계산하여 로 계산된다.
- 생성 성능 (Generation Performance): 생성된 답변의 품질을 평가하기 위해 token-level F-1 및 LF-EVAL 지표를 사용한다. token-level F-1은 정규화 및 단어 수준 토큰화 후 예측과 ground truth 답변을 비교하여 계산된다. LF-EVAL은 GPT-4o를 사용하여 Figure 5의 프롬프트로 1-10점 사이의 점수 를 10회 생성하고, 각 점수 에 해당하는 토큰 확률 를 사용하여 가중 평균 으로 최종 LF-EVAL 점수를 산출한다.
법령 코퍼스
세밀한 법률 정보를 제공하기 위해 조문 단위의 법령 코퍼스를 구축했다. 이 코퍼스에는 1998년부터 2024년까지 한국 법원 판결에서 인용된 모든 활성 법령이 포함된다. 최종 코퍼스는 608개의 고유 법령과 약 233,544개의 조문 단위로 구성되며, 이 법령 코퍼스는 실험에서 실제 조문을 얻기 위한 검색 풀로 사용된다.
베이스라인
PARSER의 효과성을 평가하기 위해 다양한 multi-hop reasoning 베이스라인과 비교한다. 대부분의 베이스라인은 일반 도메인 작업을 대상으로 하므로, 공식 구현을 KOBLEX에 직접 적용하기는 어려웠다. 따라서 공정한 비교를 위해 수동으로 재구현했다. retrieval이 필요한 방법에 대해서는 본 연구의 법령 코퍼스에 대한 검색을 수행하여 일관성을 확보했다. 베이스라인에는 Standard Prompting (SP), Chain of Thought (CoT), Self-Ask, IRCoT, FLARE, ProbTree, BeamAggr가 포함된다. 또한, 각 KOBLEX 인스턴스의 추론 홉 수와 동일한 수의 gold reference provisions에 oracle 접근 권한을 부여하는 간단한 One-Time Retrieval 베이스라인도 포함한다.
결과
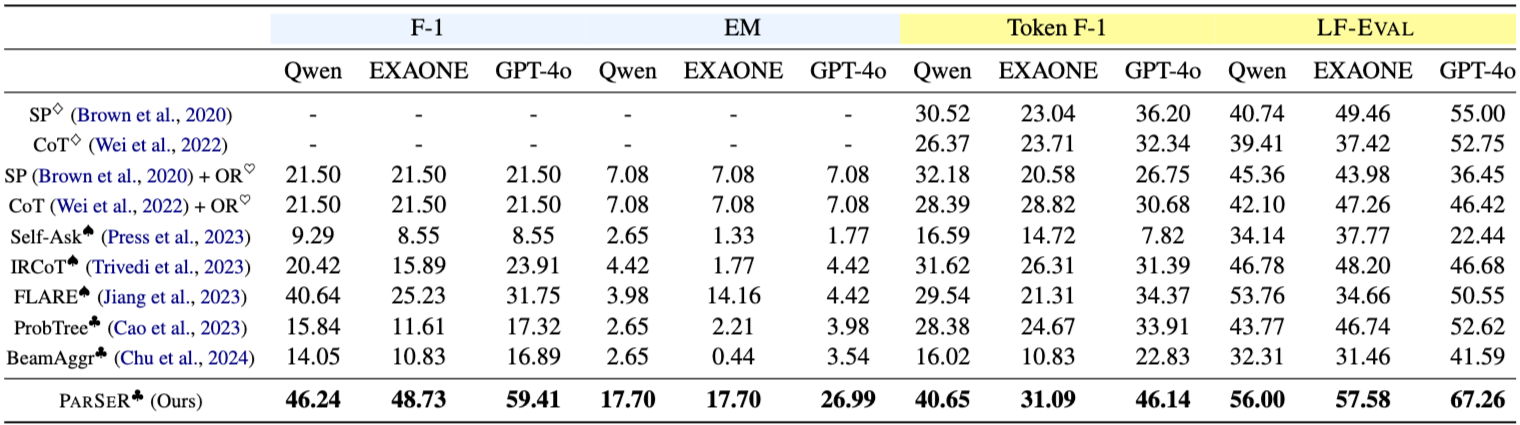
Table 2는 KOBLEX에 대한 다양한 베이스라인 방법의 실험 결과를 보여준다. F-1 및 EM 점수가 낮은 베이스라인은 No-retrieval 베이스라인보다 Token F-1 및 LF-EVAL 점수가 낮은 경향을 보인다. 이는 관련 없는 조문을 검색하는 것이 multi-hop 법률 추론에 부정적인 영향을 미친다는 것을 시사한다. 반면, PARSER는 모든 LLM에 걸쳐 모든 검색 및 생성 지표에서 모든 베이스라인 방법을 지속적으로 능가한다. 특히, GPT-4o에서 PARSER는 가장 강력한 베이스라인인 ProbTree를 Token F-1에서 +12.23, LF-EVAL에서 +14.64 향상시켰다. 이는 PARSER가 복잡한 multi-hop 법률 질문에 대한 추론을 효과적으로 수행할 수 있음을 나타낸다. Appendix J의 작은 LLM에 대한 추가 결과도 유사한 경향을 보인다.
분석
추론 깊이
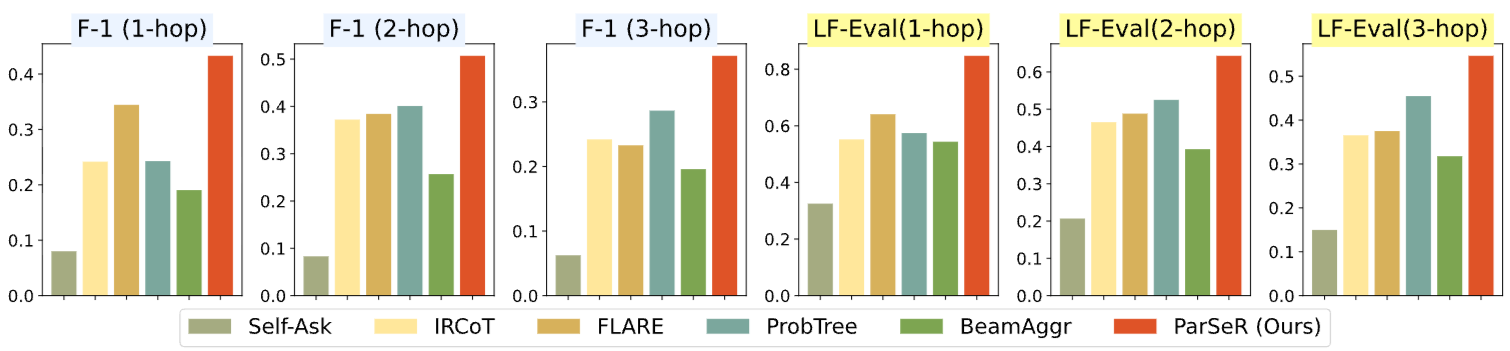
KOBLEX가 다양한 수준의 추론 깊이를 요구하는 시나리오 기반 QA 작업을 포함하므로, 본 논문은 추론 깊이 수준별 성능을 평가하여 상세한 분석을 수행했다. Figure 6은 각 방법의 추론 깊이별 성능을 보여준다. PARSER는 모든 홉 수준에서 일관되게 최상의 성능을 달성한다. PARSER를 제외하면 FLARE와 ProbTree 같은 confidence-based 방법이 다른 베이스라인보다 우수한 성능을 보인다. 특히, FLARE는 1-hop 수준에서 2위를 차지하며, ProbTree는 2-hop 및 3-hop 수준에서 더 깊은 추론에서 탁월하다. 이러한 결과는 기존 방법들의 성능이 요구되는 추론 깊이에 따라 달라질 수 있음을 시사한다. 반면, PARSER는 모든 추론 깊이 수준의 질문에 걸쳐 강건한 성능을 보인다.
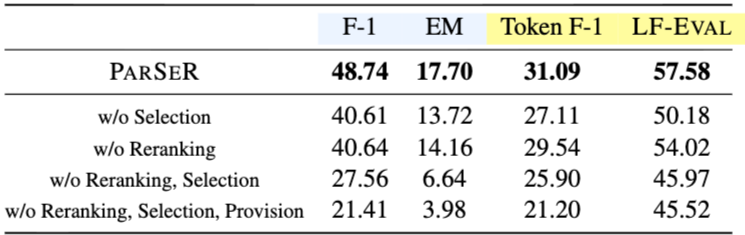
Ablation Study
PARSER의 성능 향상을 이끄는 각 모듈의 역할을 분석하기 위해 각 구성 요소의 영향을 분리하는 ablation study를 수행했다. Table 3은 EXAONE 3.5-32B (Research, 2024)에 대한 PARSER의 ablation study 결과를 보여준다. Selection을 제거하면 Reranking을 제거하는 것보다 더 큰 성능 저하가 발생하며, 이는 LLM의 관련 조문 선택 능력이 cross-encoder보다 더 효과적임을 시사한다. Reranking과 Selection을 모두 제거하면 상당한 성능 저하가 관찰된다. 더욱이, parametric provision generation을 원래 질문을 기반으로 하는 단순 top- 검색(여기서 는 생성된 조문 수와 일치)으로 대체하면 성능이 더욱 악화된다. 이는 parametric provision generation이 단순 검색보다 multi-hop retrieval-augmented reasoning을 더 잘 지원한다는 것을 나타낸다.
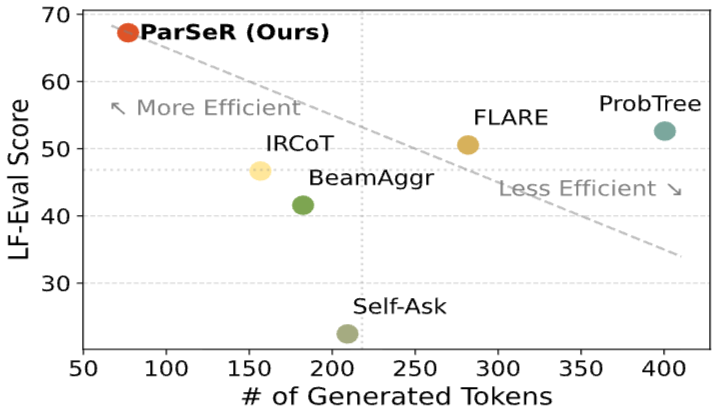
효율성
검색 증강 추론 방법은 복잡한 질문에 대한 성능을 크게 향상시키지만, 최종 답변 예측을 위해 많은 토큰을 요구하는 경우가 많다. 효과성과 효율성을 모두 평가하기 위해 각 방법의 성능을 답변 예측 중 소비된 토큰 수와 비교하여 분석했다. Figure 7은 평균 생성 토큰 수에 대한 LF-EVAL 점수를 보여준다. 생성 토큰 수가 많을수록 성능이 향상되는 경향이 있지만, 이러한 개선은 일반적으로 계산 오버헤드에 비해 미미하여 잠재적 비효율성을 시사한다. 그러나 PARSER는 가장 적은 토큰을 생성하면서도 가장 높은 성능을 보여주어 가장 효율적인 접근 방식임을 입증한다. 다른 베이스라인과 달리, PARSER는 초기 단계에서 생성된 parametric provisions를 활용하여 목표 지향적인 multi-hop 증거 검색을 용이하게 하고, 3단계 검색 파이프라인을 통해 검색 정확도를 향상시키는 데 중점을 둔다. 이 특징은 PARSER가 효과적일 뿐만 아니라 multi-hop legal reasoning에 대해 비용 효율적이라는 점을 이끈다.
Retriever 유형의 영향
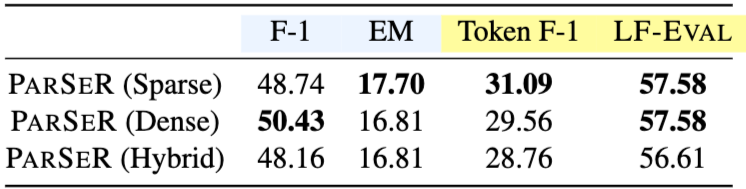
다양한 유형의 검색 도구가 존재하므로, retriever 유형이 PARSER 성능에 미치는 영향을 조사했다. 법률 조문 검색 작업에 대해 sparse retriever로 BM25 (Robertson and Zaragoza, 2009), 강력한 한국어 임베딩 능력으로 알려진 dense retriever로 BGE-M3 (Chen et al., 2024), 그리고 이 둘의 조합을 hybrid retriever로 고려했다. Table 4는 EXAONE-3.5-32B를 사용하여 다른 retriever 유형으로 실험한 결과를 보여준다. 전반적으로 retriever 유형 간에 유의미한 성능 차이는 없었지만, sparse retriever (BM25)가 가장 높은 EM, token-level F1, LF-EVAL 점수를 달성했다. 따라서 재현성, 효율적인 검색 속도, 그리고 비교의 공정성을 고려하여 BM25를 검색 도구로 채택했다.
PARSER의 k 및 l 값 영향
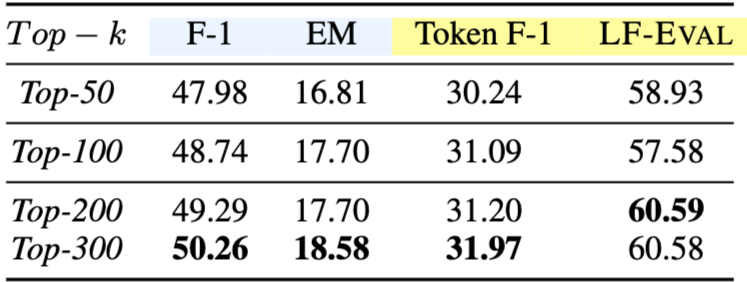
3단계 검색 파이프라인의 두 가지 주요 하이퍼파라미터인 (retrieval scope)와 (reranking scope)의 영향을 조사했다. Table 5는 PARSER의 다른 모듈을 고정한 상태에서 를 변경한 결과를 보여준다. 가 증가함에 따라 검색 지표는 약간 향상되지만, 생성 지표에는 미미한 영향을 보인다. Table 6은 동일한 조건에서 을 변경한 결과를 보여준다. 와 달리 을 증가시키는 것이 일관된 성능 향상을 가져오지는 않는다. 와 값이 클수록 더 넓은 문맥과 더 나은 재현율을 제공하지만, reranking 시 계산 비용이 증가하고 Selection 중 context limit를 초과할 위험이 있다. 따라서 본 논문에서는 PARSER에 대해 으로 설정했다.
결론
본 연구에서는 LLM의 provision-grounded, open-ended 한국어 법률 QA 능력 평가를 위한 벤치마크인 KOBLEX를 소개했다. 또한, 검색 정확성과 답변 품질 모두에서 기존 검색 증강 추론 방법을 크게 능가하는 PARSER를 제시한다. 자유 형식 답변의 법률적 충실도를 신뢰성 있게 평가하기 위해 인간 판단과 일치하는 자동 평가 지표인 LF-EVAL을 제안한다. 본 실험은 PARSER가 모든 지표에서 비용 효율적이고 추론 깊이에 무관하게 모든 베이스라인을 지속적으로 능가함을 입증한다. KOBLEX, LF-EVAL, 그리고 PARSER가 법률 자연어 처리(NLP) 연구 발전에 귀중한 자원이 되기를 희망한다.
제한사항
- 제한된 규모 및 전문가 의존성: 현재 KOBLEX는 규모가 상대적으로 제한적이다. 자동화된 파이프라인이 초기 QA 초안의 대규모 생성을 가능하게 하지만, 법률적 정확성 및 문맥적 일관성을 보장하기 위해 각 인스턴스에 대한 법률 전문가의 신중한 검토 및 수정이 여전히 필요하다. 이는 LLM이 미묘한 법률 해석을 인간 감독 없이 신뢰성 있게 처리하는 데 현재 한계가 있기 때문이다.
- 민법 시스템 초점: KOBLEX, PARSER 및 LF-EVAL은 성문법이 주요 법률 권위의 원천이 되는 민법 시스템의 특성을 반영하여 한국 법령을 기반으로 개발되었다. 이러한 설계는 법령 기반 법률 추론의 엄격한 평가를 가능하게 하지만, 법률 해석이 판례법(case law)에 크게 의존하는 미국 또는 영국과 같은 영미법계 관할권에는 적용 가능성이 제한될 수 있다.
KOBLEX 개발 과정에서 윤리적인 데이터 구축 및 사용을 보장하기 위해 다음과 같이 진행하였다고 한다.
- 데이터셋 구축: 첫째, 데이터셋의 모든 질문 및 답변 인스턴스는 가상의 법률 시나리오에서 파생되었으며 개인 식별 정보를 포함하지 않는다. 모든 배경 시나리오는 익명화된 인물(예: Person A, Person B)을 사용하여 구성되었으며, 실제 인물, 사건 또는 민감한 세부 정보는 포함되지 않았다. 둘째, 수정 및 평가 과정에 참여한 모든 법률 전문가들은 작업의 목적이 법률 추론에 대한 LLM 성능 평가를 위한 데이터셋 구축임을 사전에 통보받았다. 마지막으로, KOBLEX 구축에 사용된 모든 법률 문서(법령 및 판례)는 공식 정부 API에서 수집되었으며, 연구 목적으로의 재배포를 허용하는 한국의 공공 데이터 정책에 해당된다. 법률 조문의 영어 버전의 경우, 한국법제연구원(KLRI)의 공개 번역을 사용했으며, 이는 비상업적 연구 사용을 위한 재배포가 허용됨을 확인했다. 기계 번역된 모든 내용은 투명성을 유지하기 위해 데이터셋 내에 명시적으로 라벨링되어 있다.
- 의도된 사용: 본 연구는 한국 법률에서 open-ended, provision-grounded 법률 질문 답변을 평가하기 위한 벤치마크 및 방법론을 제시한다. 이는 오직 연구 목적으로만 설계되었으며, 실제 법률 의사결정에 직접 사용되거나 전문 법률 자문을 대체하기 위한 것이 아니다. 벤치마크는 법률 NLP 시스템의 개발 및 평가를 지원하는 것을 목표로 한다.
