
Abstract
멀티모달 문서 검색은 다양한 형태의 멀티모달 컨텐츠를 식별하고 검색하는 것이 목표이다. 이 태스크의 수요가 높아지고 있음에도, 성능을 효과적으로 평가할 수 있는 포괄적이고 견고한 벤치마크가 부족하다. 이 격차를 해소하기 위해, 해당 연구는 페이지 수준과 레이아웃 수준 검색의 고유한 태스크를 포함한 MMDocIR이라는 새로운 벤치마크를 소개한다.
페이지 수준은 긴 문서에서 가장 관련성이 높은 페이지를 식별하는 성능을 평가, 레이아웃 수준은 특정 레이아웃을 감지하는 능력을 평가한다. 즉, 텍스트의 단락, 방정식, 그림, 표 혹은 차트를 포함한 다양한 요소를 참조한다.
MMDocIR 벤치마크는 전문가가 주석을 단 1,685개 질문과 부트스트랩된 레이블이 있는 173,843개의 질문을 특징으로 한다.
이 실험을 통해 visual 리트리버가 text only 리트리버 보다 성능이 우수하고, MMDocoIR Train 세트가 멀티모달 문서 검색 성능을 향상시키며, VLM-text를 활용하는 텍스트 검색기가 OCR-text에 의존하는 검색기보다 더 우수함을 입증한다.
Introduction
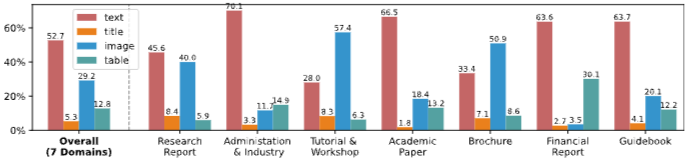
멀티모달 문서 검색은 사용자 쿼리를 기반으로 시각적으로 풍부한 문서에서 정보를 검색하는 것을 주 목표로 한다. 이미지, 표, 차트, 레이아웃 디자인과 같은 멀티모달 요소에 대한 이해에 훨씬 더 큰 요구 사항을 부과하고 이러한 요소들은 종종 일반 텍스트로는 전달하기 어려운 중요한 정보를 담고 있다. 표는 구조화된 데이터 패턴을 보여주고, 차트는 추세나 상관관계를 시각화하며, 이미지는 맥락적 및 의미론적 단서를 제공하는 등, 이러한 시각적 요소를 결합하면 검색된 콘텐츠의 품질이 향상된다. MMLongBench-Doc 벤치마크에 대한 분석은 텍스트가 콘텐츠 영역의 52.7%를 차지하고, 표와 이미지는 29.2%와 12.8%를 차지하는 것을 보면, 멀티모달 정보를 효과적으로 처리하는 검색 시스템의 필요성이 강조된다.
하지만 기존 벤치마크들은 포괄적인 평가를 저해하는 몇가지 요소가 있다.
1. 질문 품질: 기존 벤치마크에 사용된 많은 질문은 시각 질의응답(VQA) 작업 데이터셋에서 직접 가져온 것입니다. 일부 질문은 입력이 이미 관련성이 있다고 가정하는 경우가 많아, 검색 능력에 대한 의미 있는 평가에 적합하지 않다.
2. 문서 완전성 및 다양성: 기존 벤치마크는 종종 부분적인 문서만 제공하여 전체 문서 맥락 내에서의 평가 능력을 제한한다. 또한, 문서 도메인의 좁은 범위는 실제 다양한 사용 사례에 대한 적용 가능성을 더욱 제한한다.
3. 검색 세분성: 대부분의 벤치마크는 페이지 수준 검색만 지원한다. 사용자 쿼리가 종종 전체 페이지보다는 그림이나 표와 같은 특정 요소에 집중되기 때문에, 이러한 세분성은 종종 불충분하다.
MMDOCIR은 이러한 한계를 해결하기 위해 페이지 수준(Page-level)과 레이아웃 수준(Layout-level) 검색이라는 두 가지 태스크를 중심으로 설계된 멀티모달 문서 검색 벤치마크이다.
페이지 수준 검색은 사용자 쿼리에 답하기 위해 문서 전체 페이지 중 가장 관련성이 높은 페이지를 식별하는 것을 목표로 하며, 레이아웃 수준 검색은 해당 페이지 내에서 단락, 제목, 수식, 표, 그림, 차트와 같은 구체적인 문서 요소를 직접 검색하는 태스크이다. 이를 통해 단순히 “어느 페이지에 답이 있는가”를 넘어서, “그 페이지에서 어떤 요소가 핵심 증거인가”까지 평가할 수 있도록 한다.
이 두 가지 태스크를 지원하기 위해, 저자들은 313개의 문서로 구성된 MMDOCIR 평가 세트를 구축하였다. 각 문서는 평균 65.1페이지로 구성되어 있으며, MMLongBench-Doc과 DocBench에서 파생된 1,658개의 수정된 쿼리가 포함되어 있다. 각 쿼리에는 정답 증거가 포함된 2,107개의 페이지 수준 레이블과, 페이지 내부에서 핵심 증거를 정밀하게 표시한 2,638개의 레이아웃 수준 레이블이 주석으로 제공된다. 레이아웃 레이블은 식별된 페이지 내에서 핵심 증거를 둘러싼 바운딩 박스 형태로 정의된다.
또한 저자들은 검색기 학습을 지원하기 위한 MMDOCIR 훈련 세트를 함께 제안한다. 해당 훈련 세트는 7개의 DocQA 계열 데이터셋에서 수집한 73,843개의 질문과 6,878개의 문서로 구성되어 있으며, 수동 문서 수집과 준자동화된 파이프라인을 통해 페이지 및 레이아웃 수준 정답 레이블이 주석되었다.
이러한 데이터셋을 기반으로, 본 연구는 멀티모달 문서 검색에서 사용되는 검색기를 시각 기반 검색기와 텍스트 기반 검색기의 두 가지 유형으로 구분한다. 시각 기반 검색기는 비전 언어 모델(VLM)을 활용하여 이미지, 표, 레이아웃 등 다양한 멀티모달 단서를 직접 반영한 임베딩을 생성한다. 반면 텍스트 기반 검색기는 OCR 또는 VLM을 통해 멀티모달 콘텐츠를 텍스트로 변환한 뒤, 언어 모델을 사용해 쿼리와 문서를 임베딩한다.
정리하면, 본 논문의 기여는 다음과 같다.
페이지 수준과 레이아웃 수준을 동시에 고려하는 이중 검색 태스크 프레임워크를 정의하고,
이를 체계적으로 평가할 수 있는 MMDocIR 벤치마크(평가 세트 및 훈련 세트)를 구축하며,
멀티모달 문서 검색에서 서로 다른 검색기 설계를 비교·분석할 수 있는 기반을 제공한다.
Dual-task Retrieval Setting
본 논문에서는 멀티모달 문서 검색을 페이지 수준과 레이아웃 수준을 동시에 고려하는 이중 작업(Dual-task Retrieval) 문제로 정의한다.
하나의 문서 코퍼스는 여러 개의 문서 페이지(Page)와, 각 페이지에서 레이아웃 감지를 통해 추출된 레이아웃 요소(Layout)들로 구성된다. 레이아웃은 단락, 표, 그림, 차트 등 문서 페이지를 이루는 개별 요소를 의미하며, 일반적으로 하나의 페이지에는 약 5~15개의 레이아웃이 포함된다.
이 설정에서 검색의 목표는, 주어진 사용자 쿼리에 대해
가장 관련성이 높은 페이지들과
그 안에서 가장 관련성이 높은 레이아웃 요소들
을 각각 상위 k개씩 검색하는 것이다. 여기서 k는 전체 페이지 수나 레이아웃 수에 비해 매우 작은 값으로 설정된다.
페이지와 레이아웃의 관련성은 각각 쿼리와의 유사도 점수로 측정된다. 즉, 쿼리와 페이지 간의 유사도, 그리고 쿼리와 개별 레이아웃 간의 유사도를 별도로 계산하여 순위를 매긴다. 이를 통해 단순히 “어느 페이지가 중요한가”뿐만 아니라, “그 페이지 안에서 어떤 요소가 실제로 쿼리에 답하는 증거인가”를 정밀하게 평가할 수 있다.
검색 시스템은 전체적으로 두 단계 파이프라인으로 구성된다.
먼저 오프라인 인덱싱 단계에서는 모든 문서 페이지와 레이아웃 요소를 벡터 표현으로 인코딩하여 미리 저장한다. 이후 온라인 쿼리 단계에서는 입력 쿼리를 동일한 벡터 공간으로 변환한 뒤, 미리 인덱싱된 페이지 및 레이아웃 벡터들과의 유사도를 계산하여 최종 검색 결과를 반환한다.
이와 같은 이중 작업 검색 설정은, 긴 멀티모달 문서 환경에서 페이지 단위의 거친 검색과 레이아웃 단위의 세밀한 검색을 동시에 수행할 수 있도록 설계되었다.
MMDOCIR: Evaluation Set
Document Corpus Construction
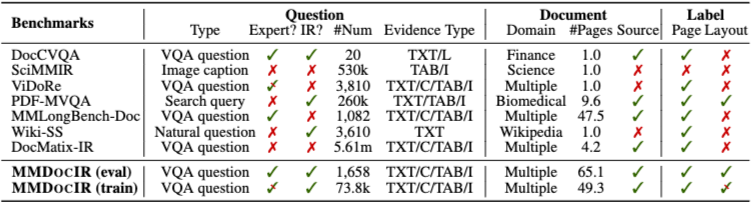
MMDocIR 평가 세트는 기존 DocVQA 계열 데이터셋에 대한 검토를 바탕으로 구축되었다. 저자들은 벤치마크 구축에 적합한 문서 특성과 질문 품질을 고려하여 MMLongBench-Doc과 DocBench 두 데이터셋을 선택한다.
MMLongBench-Doc은 135개의 문서와 1,091개의 질문으로 구성된 장문 멀티모달 벤치마크로, 문서당 평균 47.5페이지를 포함한다. 반면 DocBench는 장문 문서 이해에 초점을 둔 데이터셋으로, 229개의 문서와 1,102개의 질문을 포함하며 문서당 평균 길이는 77.5페이지에 달한다. 두 데이터셋 모두 다양한 도메인을 포괄하고 있으며, 이미지·표·텍스트 등 서로 다른 모달리티의 증거를 요구하는 전문가 주석 질문을 포함하고 있다는 공통점을 가진다.
이 두 데이터셋을 기반으로, 저자들은 후속 주석 작업을 위해 총 364개의 문서와 2,193개의 질문을 1차적으로 수집한다.
Question Filtering and Refinement
수집된 질문이 문서 검색 태스크에 적합하도록 하기 위해, 저자들은 정보 검색(IR)의 목적과 잘 맞지 않는 질문 유형을 정의하고 이를 필터링 및 수정한다. 이 과정을 통해 검색 능력을 제대로 평가할 수 없는 질문을 제거하고, 최종적으로 1,658개의 질문을 MMDocIR 평가 세트에 포함시킨다.
이 단계는 MMDocIR이 단순한 문서 이해나 VQA가 아니라, 실제 검색 문제에 초점을 둔 벤치마크임을 보장하기 위한 핵심 과정이다.
Page-level Annotation
페이지 수준 주석은 각 질문에 대해 정답 증거가 포함된 페이지를 정확히 식별하는 것을 목표로 한다.
MMDocIR의 문서는 평균 65.1페이지로 구성되어 있어, 관련 페이지를 찾아내는 작업은 매우 높은 난이도를 가지며 세심한 문서 이해를 요구한다.
주석 방식은 데이터셋에 따라 다음과 같이 진행되었다.
DocBench: 864개 질문 전체에 대해 문서를 처음부터 끝까지 검토하며 페이지 레이블을 수동으로 주석
MMLongBench-Doc: 기존 답변과 페이지 레이블을 엄격하게 재검토 및 검증하여 오류를 수정
이 과정을 통해 일부 잘못된 답변과 페이지 레이블이 수정되었으며, 최종적으로 1,658개 질문 전체에 대한 페이지 수준 레이블이 확보되었다.
Layout-level Annotation
MMDocIR의 가장 큰 특징 중 하나는 페이지 수준을 넘어 레이아웃 수준 주석을 포함한다는 점이다. 레이아웃 수준 주석은 특정 페이지 내에서 실제로 답변 증거가 위치한 단락, 표, 그림, 차트 등의 요소를 직접 지정한다.
주석 과정은 다음과 같이 진행된다.
레이아웃 탐지
모든 문서를 자동 파싱하여 레이아웃 유형과 경계 박스를 탐지한다.
증거 식별
탐지된 레이아웃 중에서 정답 증거를 포함하는 요소를 선택한다. 자동 탐지가 실패한 경우에는 수동으로 바운딩 박스를 주석하며, 이는 전체 레이아웃 주석의 약 7%를 차지한다.
이러한 과정을 통해 총 2,638개의 레이아웃 수준 레이블이 구축되었다.
Quality Control
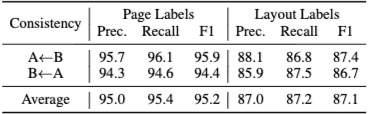
주석 품질을 보장하기 위해, MMDocIR은 3단계 품질 관리 프로세스를 적용한다.
중복 주석 기반 평가: 일부 질문을 두 그룹이 동시에 주석하여 일관성을 점검
상호 평가(Cross-evaluation): 페이지 및 레이아웃 주석에 대해 높은 일치도를 확인하고 불일치를 수정
무작위 재검증: 나머지 주석의 절반을 무작위로 재검토하여 최종 품질을 확보
이를 통해 평가 세트 전반의 신뢰성을 확보한다.
Multimodal Content to Text Conversion
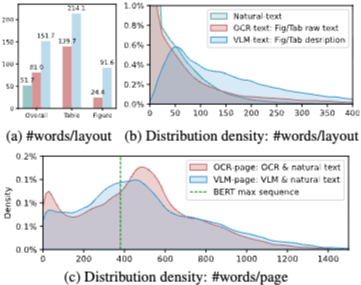
텍스트 기반 검색기를 고려하여, MMDocIR에서는 멀티모달 레이아웃을 텍스트 형태로 변환한 표현도 함께 제공한다.
OCR-text: OCR을 이용해 이미지 내 텍스트를 추출
VLM-text: Vision-Language Model을 활용해 이미지나 표를 자연어로 상세 설명
각 이미지 레이아웃은 원본 이미지, OCR-text, VLM-text의 세 가지 형태로 저장된다.
또한 페이지 단위에서는 자연 텍스트와 OCR/VLM 텍스트를 결합하여 두 가지 페이지 표현(OCR-page, VLM-page)을 구성한다.
Dataset Statistics and Analysis
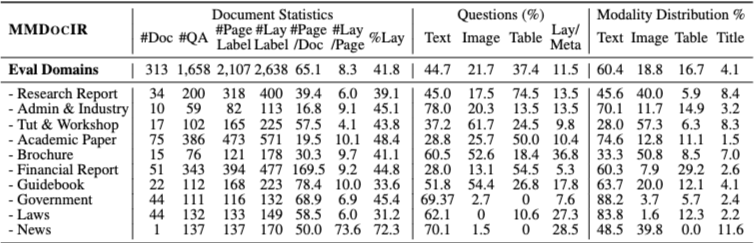
MMDocIR 평가 세트는 313개의 장문 문서로 구성되며, 문서당 평균 65.1페이지를 포함한다. 전체 문서는 10개 도메인으로 분류되며, 도메인에 따라 멀티모달 구성 비율이 뚜렷하게 달라진다. 예를 들어 보고서나 튜토리얼 문서는 이미지 비중이 높고, 금융·산업 문서는 표가 풍부하며, 정부·법률 문서는 텍스트 중심의 구성을 가진다.
질문과 주석 분석 결과, MMDocIR은 단순한 검색을 넘어 다양한 난이도의 문제를 포함한다. 일부 질문은 여러 모달리티를 동시에 이해해야 하며, 다른 질문은 여러 페이지 또는 여러 레이아웃 요소를 종합적으로 추론해야 한다. 이는 MMDocIR이 실제 멀티모달 문서 검색 환경을 현실적으로 반영한 벤치마크임을 보여준다.
MMDOCIR: Training Set
Training Corpus Construction
MMDocIR은 평가 세트뿐 아니라, 멀티모달 문서 검색 모델 학습을 위한 대규모 훈련 세트도 함께 제공한다. 저자들은 여러 DocVQA 계열 데이터셋을 검토한 뒤, MP-DocVQA, SlideVQA, TAT-DQA, SciQAG, DUDE, CUAD 등 총 7개의 데이터셋에서 훈련용 코퍼스를 수집하였다.
이 과정에서 대부분의 데이터셋이 원본 문서를 직접 제공하지 않는다는 문제가 있었기 때문에, 저자들은 문서를 직접 추적하고 복구하는 데 상당한 노력을 기울였다. 결과적으로 훈련 세트는 6,878개의 문서와 73,843개의 질문으로 구성된다.
Label Construction and Statistics
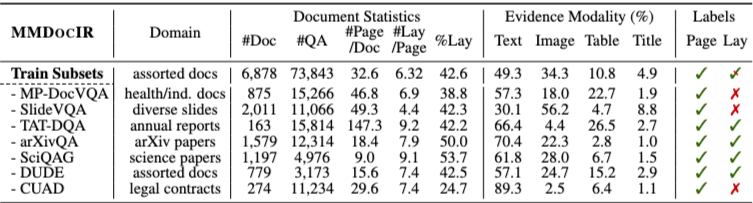
기존 훈련 데이터셋에는 페이지 수준이나 레이아웃 수준 레이블이 없는 경우가 많기 때문에, 저자들은 이를 보완하기 위해 반자동 레이블 구성 파이프라인을 설계하였다. 이 파이프라인을 통해 페이지 수준 레이블과 레이아웃 수준 레이블을 생성하며, 레이아웃 주석은 일부 데이터셋에서만 가능했다.
특히 기존 데이터셋 대부분에는 레이아웃 주석이 포함되어 있지 않았고, 최종적으로 4개의 데이터셋에 대해서만 레이아웃 수준 레이블을 확보할 수 있었다. 훈련 세트의 전체 통계(문서 길이, 도메인 분포, 멀티모달 구성 등)는 논문에서 별도로 정리되어 있다.
Experiments
Evaluation Protocol
모든 실험은 앞서 정의한 이중 작업 검색 설정에 따라
- 페이지 수준 검색
- 레이아웃 수준 검색
을 각각 수행한다.
성능 평가는 Recall@k를 사용하며,
- 페이지 검색은 페이지 인덱스 기준으로
- 레이아웃 검색은 예측된 레이아웃과 실제 레이아웃 간 바운딩 박스 중첩 기반으로 계산한다.
이는 레이아웃 감지 과정에서 경계 박스가 완벽히 일치하지 않는 현실적인 상황을 반영한 평가 방식이다.
Page-level Retrieval Results
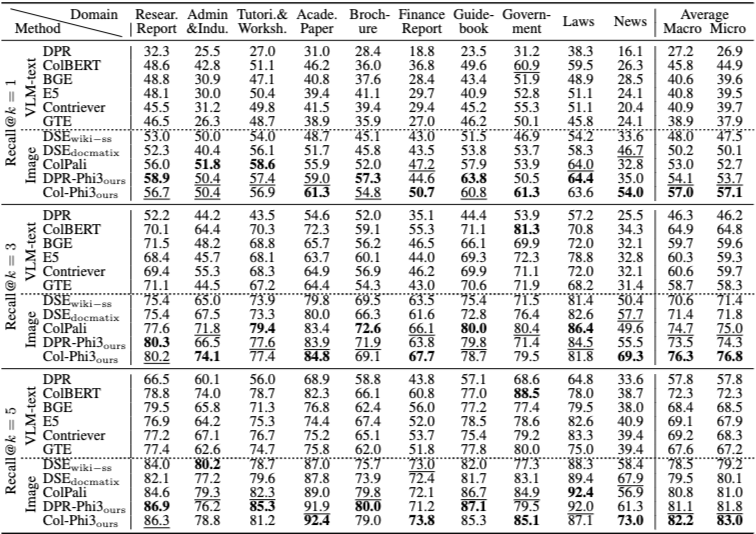
(Table 5 참고)
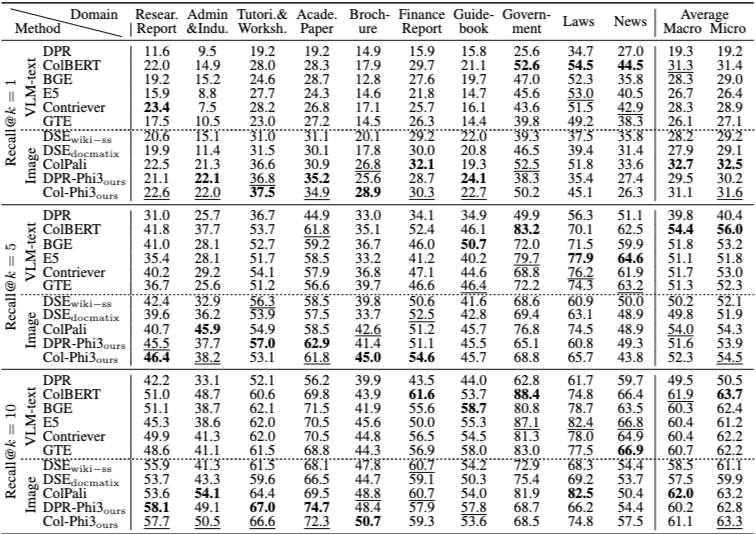
페이지 수준 검색 결과에서 가장 두드러지는 점은 시각 기반 검색기의 전반적인 우수성이다.
텍스트 기반 검색기는 멀티모달 콘텐츠를 OCR 또는 텍스트 설명으로 변환하는 과정에서 시각적 단서를 일부 손실하는 반면, 시각 기반 검색기는 문서 페이지의 스크린샷을 직접 활용하여 이러한 정보를 유지할 수 있다.
또한 MMDocIR 훈련 세트로 학습된 모델들은 전반적으로 더 안정적인 성능을 보이며, 고품질 멀티모달 학습 데이터의 중요성을 보여준다.
텍스트 기반 방법 중에서는 OCR-text보다 VLM-text를 활용한 방식이 일관되게 더 우수한 성능을 기록한다.
한편, 토큰 수준 임베딩을 사용하는 검색기(예: ColBERT 계열)는 상위 결과(Recall@1)에서 강점을 보이지만, 저장 공간과 계산 비용이 크게 증가한다는 점에서 효율성 측면의 트레이드오프가 존재한다.
Layout-level Retrieval Results
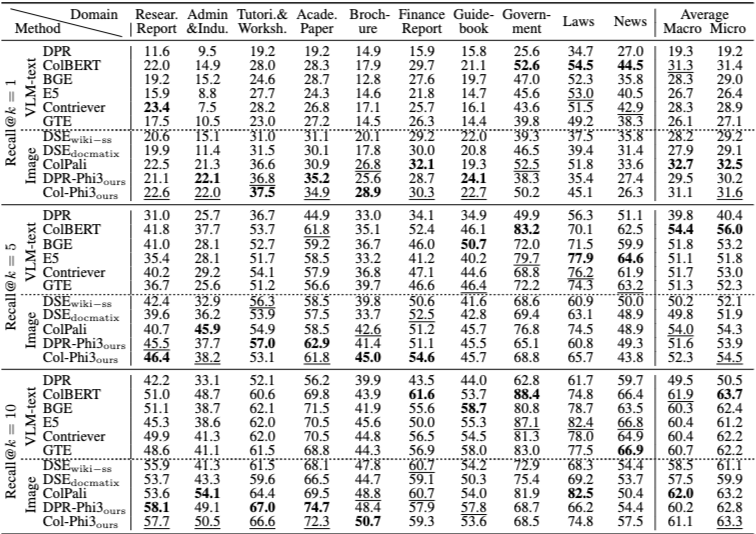
(Table 6 참고)
레이아웃 수준 검색은 페이지 검색보다 훨씬 더 어려운 태스크로 나타난다.
흥미롭게도 이 설정에서는 VLM-text 기반 텍스트 검색기와 시각 기반 검색기의 성능 격차가 크게 줄어든다. 이는 최신 VLM이 이미지나 표의 시각적 정보를 텍스트로 비교적 충실하게 설명할 수 있음을 시사한다.
또한 순수 이미지 입력을 사용하는 시각 검색기가, 이미지–텍스트를 혼합한 하이브리드 입력보다 더 나은 성능을 보이는 경향이 관찰된다. 이는 현재 VLM이 멀티모달 설정에서 텍스트보다 이미지를 모델링하는 데 더 강점을 가질 가능성을 보여준다.
상위 10개의 레이아웃을 검색하더라도 정답을 모두 커버하기 어려운 경우가 많아, 레이아웃 검색 자체의 높은 난이도가 드러난다.
OCR-text vs VLM-text
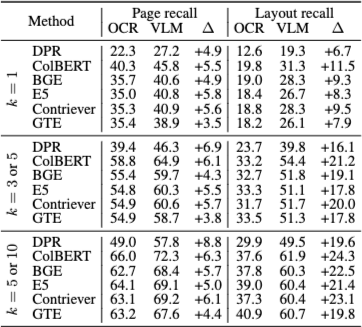
(Table 5, 6 및 Figure 3 참고)
텍스트 기반 검색기 비교에서 가장 명확한 결론은 OCR-text의 한계이다.
OCR-text는 이미지나 표의 구조적·시각적 의미를 충분히 담지 못하는 반면, VLM-text는 훨씬 풍부한 정보를 제공한다.
특히 페이지 수준 검색에서는 입력 길이 제한(512 토큰)으로 인해 많은 페이지에서 정보 손실이 발생한다. 반면 레이아웃 수준 텍스트는 상대적으로 짧기 때문에, 텍스트 검색기가 레이아웃 검색에서 더 경쟁력 있는 성능을 보인다.
Visual Retrieval: Image vs Hybrid Input
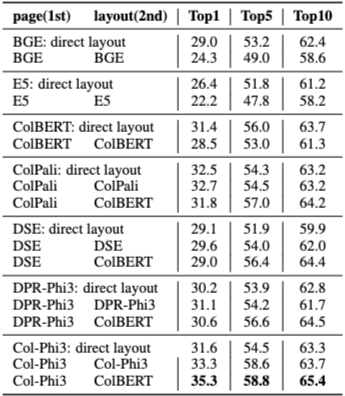
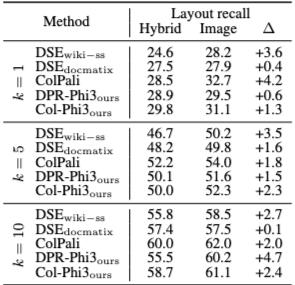
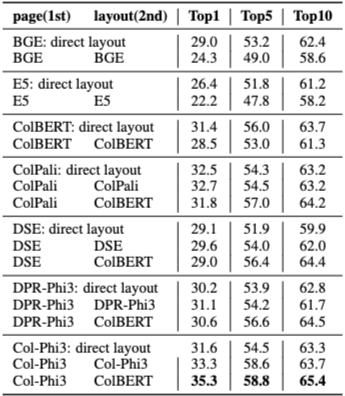
시각 기반 검색기는 텍스트를 네이티브 텍스트 입력으로 처리하는 것보다, 텍스트를 이미지로 인코딩해 처리할 때 더 높은 성능을 보인다. 이는 시각 검색기가 주로 이미지 기반 쿼리–문서 쌍으로 학습되었기 때문으로 해석된다.
다만 이러한 방식은 계산 비용이 크기 때문에, 저자들은 캐스케이드 검색(cascaded retrieval)을 대안으로 제안한다.
즉, 먼저 페이지 검색을 수행한 뒤, 검색된 페이지 내에서 레이아웃 검색을 수행하는 방식이다. 이 설정에서는 페이지 검색 성능이 레이아웃 검색 성능에 직접적인 영향을 미친다.
Efficiency Analysis
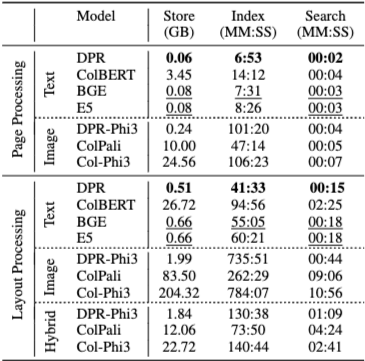
효율성 분석에서는 명확한 트레이드오프가 드러난다.
- 단일 벡터 기반 검색기(DPR 계열)는 토큰 수준 검색기보다 훨씬 효율적이다.
- 시각 입력은 텍스트 입력보다 메모리와 연산 비용이 크다.
- 성능과 효율을 종합적으로 고려할 때, 하이브리드 검색 방식이 현실적인 선택지로 제시된다.
Conclusion and Limitations
본 논문은 멀티모달 문서 검색을 페이지 수준과 레이아웃 수준으로 동시에 평가하는 이중 작업 설정으로 재정의하고, 이를 위한 새로운 벤치마크 MMDocIR을 제안한다. MMDocIR은 전문가 주석 기반 평가 세트와 대규모 훈련 세트를 모두 제공함으로써, 멀티모달 문서 검색 연구를 위한 중요한 기반을 마련한다.
다만 훈련 세트의 일부 데이터셋에는 레이아웃 주석이 부족하며, 현재의 시각 검색기는 텍스트와 시각 정보를 공동으로 학습하지 못한다는 한계도 존재한다. 저자들은 향후 연구로 텍스트–시각 공동 학습과 더 효율적인 하이브리드 검색 모델을 제안한다.
