서론
기존 Retrieval-Augmented Generation 시스템은 어휘적 또는 의미적 유사성에 주로 의존하여 논리적 관련성을 놓치는 경우가 많다. 이로 인해 검색 결과가 불완전해지고(예: 간접적으로만 관련된 구절을 검색하거나 필요한 구절을 놓침) LLM의 응답이 부정확하거나 불완전해질 수 있다. 특히 multi-hop 또는 다중 문서 QA 작업에서 이러한 한계가 두드러진다.
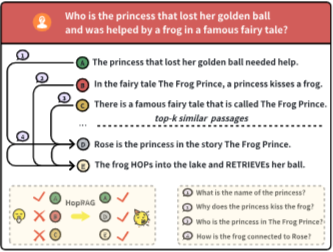
이 논문은 LLM의 추론 능력을 검색 모듈에 도입할 수 있는지에 대한 질문에 답하기 위해 HopRAG를 제안한다. HopRAG는 "Six Degrees of Separation" 이론에서 영감을 받아, 표면적으로는 간접적으로 관련되어 보이는 구절도 진정으로 관련 있는 구절에 도달하기 위한 디딤돌이 될 수 있다는 아이디어를 기반으로 한다.
HopRAG는 그래프 구조의 지식 탐색을 통해 검색에 논리적 추론을 추가하는 새로운 RAG 프레임워크이다. 인덱싱 단계에서 HopRAG는 텍스트 청크를 정점(vertex)으로, LLM이 생성한 의사 질의pseudo-query를 논리적 연결을 나타내는 edge로 사용하여 구절 그래프를 구축한다. 검색 단계에서는 "retrieve-reason-prune" 메커니즘을 사용한다. 이는 어휘적으로 또는 의미적으로 유사한 구절에서 시작하여 의사 질의와 LLM 추론의 안내를 받아 다중 홉 이웃을 탐색하며, 이를 통해 진정으로 관련 있는 구절을 식별한다.
주요 기여는 다음과 같다.
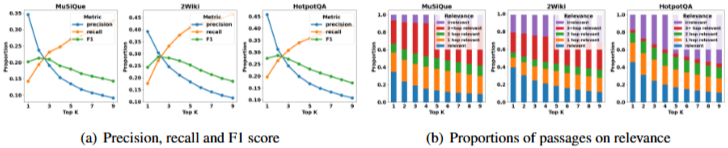
- 다중 홉 QA 작업에서 불완전한 검색 현상을 정량화하고, 검색된 구절의 60% 이상이 간접적으로 관련 있거나 관련이 없음을 밝히고, 이러한 간접적으로 관련 있는 구절을 디딤돌로 활용하는 방법을 제시한다.
- 논리 인식 검색 메커니즘을 갖춘 HopRAG를 제안한다. HopRAG는 의사 질의를 통해 raiser passage과 solver passage을 연결하고, 검색 과정에서 추론하고 가지치기하며, 유연한 논리 모델링, 교차 문서 구성, 효율적인 구축 및 업데이트를 특징으로 한다.
- 광범위한 실험을 통해 HopRAG가 기존 정보 검색 방식보다 36.25% 더 높은 응답 지표와 20.97% 더 높은 검색 F1 점수를 달성함을 입증한다.
관련 연구
HopRAG는 기존 RAG 시스템의 한계를 극복하고자 한다. 초기 RAG는 TF-IDF 및 BM25와 같은 희소 검색기에서 신경망 기반의 dense retriever로 발전했으며, Self-RAG 및 FLARE와 같은 고급 방법은 검색의 필요성과 시점을 결정한다. 그러나 이들은 여전히 지식 인덱스가 논리적으로 비구조화되어 있다는 한계가 있다.
트리 및 그래프 구조 RAG는 논리적 관계 모델링에 효과적인 방법으로 제시되었다. RAPTOR, MemWalker, SiReRAG와 같은 트리 구조 RAG는 단일 문서 내의 계층적 논리에 중점을 두지만, 문서 간 관계나 다른 유형의 관련성을 포착하지 못한다. PG-RAG, GNN-RAG, GraphRAG와 같은 그래프 구조 RAG는 엔티티를 정점으로, 관계를 에지로 하는 지식 그래프(Knowledge Graph, KG)를 사용한다. 하지만 사전 정의된 스키마에 의존하고, 구축 및 업데이트가 어렵고, 삼중항(triplet) 형식으로 인해 LLM 이해를 위해 추가적인 텍스트화나 미세 조정이 필요하다는 단점이 있다.
대조적으로 HopRAG는 추가적인 요약 노드나 삼중항 형식을 사용하지 않아 더 가볍고, 유연한 논리 모델링, 교차 문서 조직화, 효율적인 구축 및 업데이트가 가능하며, 다운스트림 작업에 더 친화적이다.
방법론
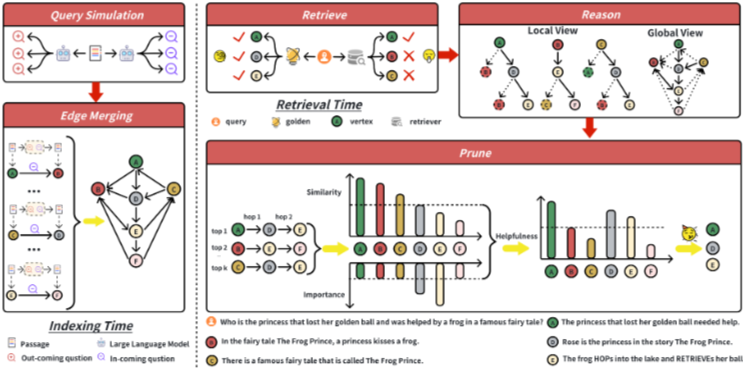

HopRAG는 주어진 구절 말뭉치 와 질의 에 대해, (1) 구절을 저장하고 유사성 및 논리적 관계를 모델링하는 그래프 구조 RAG 지식 베이스를 구축하며, (2) 간접적으로 관련 있는 구절에서 진정으로 관련 있는 구절로 도약할 수 있는 검색 전략을 구현한다. LLM은 질의 와 검색된 문맥 를 기반으로 응답 를 생성한다.
그래프 구조 인덱스 ()
정점 집합 는 모든 구절을 저장하며, 방향성 에지 집합 는 다중 홉 추론을 위한 구절 간의 논리적 관계를 기반으로 구축된다.
-
질의 시뮬레이션(Query Simulation):
각 구절 에 대해 LLM은 다음 두 그룹의 의사 질의를 생성한다.- 발신 질의(): 해당 구절 자체로는 답변할 수 없지만, 이 구절에서 시작되는 질문들이다.
- 수신 질의(): 해당 구절 내에 답변이 있는 질문들이다.
명명 개체 인식(NER)을 사용하여 각 질의에서 키워드를 추출하고(예: ), 임베딩 모델(EMB)을 사용하여 의미 벡터를 생성한다(예: ). 이를 통해 발신 삼중항 과 수신 삼중항 이 구성된다. 각 정점 는 해당 구절 와 함께 를 저장한다.
-
에지 병합(Edge Merging):
발신 및 수신 삼중항이 주어지면, 하이브리드 검색을 통해 쌍을 이루는 삼중항을 매칭하여 해당 구절 사이에 방향성 에지를 설정한다. 소스 정점 의 각 발신 삼중항 에 대해, 가장 일치하는 수신 삼중항 는 다음 유사도 함수를 통해 결정된다.
이후 형태의 방향성 에지를 구축하며, 에지 는 통합된 특징 을 갖는다.
Reasoning-Augmented Graph Traversal
이 검색 전략은 LLM의 추론 능력을 활용하여 그래프 내의 논리적 관계를 기반으로 간접적으로 관련 있는 구절의 이웃을 탐색하고 관련 구절로 도약함으로써 더 정확하고 완전한 응답을 가능하게 한다.
-
Retrieval Phase:
질의 의 키워드 와 벡터 를 얻은 후, 식 (1)을 사용하여 상위 개의 유사한 에지 를 찾는다. 이 에지들로부터 얻은 각 정점 로 너비 우선 지역 검색(breadth-first local search)을 위한 문맥 큐()를 초기화한다. -
Reasoning Phase:
그래프의 논리적 관계를 활용하고 간접적으로 관련 있는 정점에서 관련 정점으로 도약하기 위해 너비 우선 지역 검색을 수행한다. 각 순회 라운드에서 내의 각 정점 에 대해 LLM은 의 발신 에지들 중에서 질의 에 답변하는 데 가장 도움이 되는 질문을 포함하는 에지 를 선택한다. 선택된 에지의 대상 정점 를 에 추가하고, 방문 횟수를 추적하는 카운터 를 사용하여 해당 정점의 중요도를 측정한다. 이 과정을 라운드 동안 반복하여 문맥 길이를 최대 까지 확장한다. -
Pruning Phase:
순회 중 너무 많은 중간 정점을 포함하는 것을 방지하기 위해, 유사성과 논리를 통합한 새로운 지표인 '유용성(Helpfulness)' 를 도입하여 를 재순위화하고 가지치기한다. 각 정점 에 대한 는 다음과 같이 계산된다.
여기서 는 정점 의 구절과 질의 사이의 하이브리드 텍스트 유사성이며(식 1에 따름), 는 순회 중 의 정규화된 방문 횟수이다.
최종 문맥 에는 가장 높은 값을 가진 상위 개의 정점이 유지된다.
실험 및 결과
실험 설정
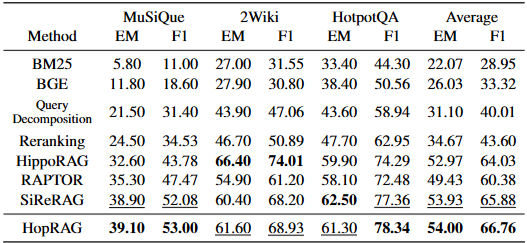
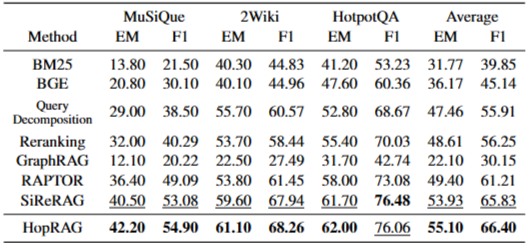
실험은 HotpotQA, 2WikiMultiHopQA, MuSiQue 데이터셋의 검증 세트에서 각각 1000개의 질문을 사용하여 수행되었다. 기준선으로는 BM25, BGE(일반, 질의 분해, 재순위화 포함), RAPTOR, SiReRAG, GraphRAG, HippoRAG 등 다양한 비구조화, 트리 구조, 그래프 구조 RAG 방법이 포함되었다. 평가 지표로는 응답 품질을 측정하는 EM(Exact Match) 및 F1 점수와, 검색 성능을 측정하는 검색 F1 점수가 사용되었다. BGE 임베딩 모델과 데이터셋의 지원 사실에 맞춰 청크가 분할되었으며, GPT-4o-mini가 의사 질의 생성 및 순회 추론 모델로 사용되었고, GPT-4o 및 GPT-3.5-turbo가 최종 응답 생성을 위한 리더 모델로 사용되었다. 검색 후보는 20개, 홉 수()는 4로 설정되었다.
주요 결과
HopRAG는 거의 모든 실험 설정에서 최상의 성능을 보였다. 특히, GPT-3.5-turbo 및 GPT-4o를 사용한 실험에서 HopRAG는 기존의 밀집 검색기(BGE)보다 약 76.78%, 질의 분해 방식보다 48.62%, 재순위화 방식보다 36.25% 더 높은 성능을 달성했다. 또한 RAPTOR, HippoRAG, SiReRAG와 같은 최신 RAG 시스템보다도 우수한 성능을 보였다. 이는 HopRAG가 텍스트 유사성과 논리적 관계를 모두 효과적으로 포착하여 다중 홉 QA 작업에 강점을 가짐을 시사한다. BM25 및 BGE와 같은 기존의 유사성 기반 검색기는 논리적 관련성을 포착하지 못해 낮은 성능을 보였다. GraphRAG 및 RAPTOR는 질의 중심 요약에는 적합하지만 다중 홉 QA 작업에서는 HopRAG보다 낮은 성능을 보였다. HopRAG는 HippoRAG보다 소폭 우수한 성능을 보였는데, HopRAG가 유사성과 논리적 관계를 통합하여 에지를 구축하기 때문이다.
논의 및 추가 분석
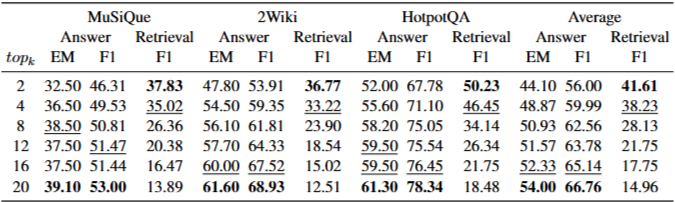
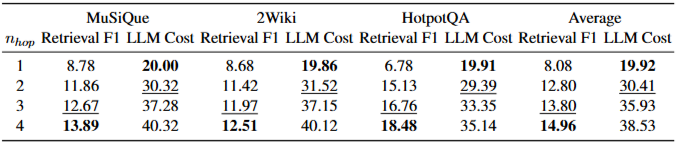
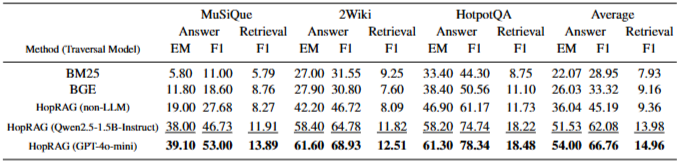
topk의 영향:topk값이 작을 때(예: 12개 후보)도 HopRAG의 QA 성능은 20개 후보를 사용하는 다른 시스템과 비견될 만하다. 이는 HopRAG의 그래프 순회 설계가 제한된 문맥 길이 내에서 정보를 효율적으로 검색하는 데 효과적임을 나타낸다.topk가 증가함에 따라 검색 F1 점수는 불필요한 정보의 포함으로 인해 감소하는 경향이 있지만, LLM의 처리 능력 덕분에 응답 품질은 일반적으로 향상된다.nhop의 영향:nhop이 증가함에 따라 검색 성능은 향상되지만, LLM 호출 비용도 증가하여 성능과 비용 사이에 상충 관계가 존재한다. 평균적으로 4번째 홉에서 큐 길이는 2.60, 5번째 홉에서 1.23으로 급격히 감소하며, 이는 4번의 홉으로도 그래프 구조 내의 지역 영역을 충분히 탐색할 수 있음을 나타낸다.- 순회 모델에 대한 절제 연구: LLM의 추론 능력 없이 유사성 일치로 추론 단계를 대체한 HopRAG (non-LLM) 버전도 BM25보다 45.84%, BGE보다 25.43% 높은 성능을 보였다. 이는 HopRAG가 텍스트 유사성과 논리적 관계를 포착하는 데 효과적임을 증명한다. GPT-4o-mini와 같은 LLM을 순회 모델로 도입하면 non-LLM 버전에 비해 평균 45.78% 더 높은 점수를 달성하며, Qwen2.5-1.5B-Instruct는 더 낮은 비용으로 비슷한 결과를 제공한다. Retrieval 효율성 분석에 따르면 LLM 추론으로 인한 추가 지연 시간은 최적화 기술을 통해 크게 줄일 수 있다.
결론
HopRAG는 논리 인식 검색 메커니즘을 갖춘 새로운 RAG 시스템이다. 이 시스템은 의사 질의를 통해 관련 구절을 연결하며, 간접적으로 관련 있는 구절의 다중 홉 이웃 내에서 진정으로 관련 있는 구절을 식별하여 검색의 정밀도와 재현율을 크게 향상시킨다. 다중 홉 QA 벤치마크에 대한 광범위한 실험을 통해 HopRAG는 기존 RAG 시스템 및 최신 기준선보다 우수한 성능을 입증했다. 이는 검색 모듈에 논리적 추론을 통합하는 것의 효과를 강조한다. HopRAG는 추론 기반 지식 검색의 길을 열었으며, 향후 연구는 QA 작업 외의 더 넓은 도메인으로의 확장과 더 낮은 계산 비용으로 복잡한 시나리오를 위한 인덱싱 및 순회 전략 최적화를 포함한다.
한계
현재 평가는 다중 홉 또는 다중 문서 QA 작업에 중점을 둔다. 따라서 다른 데이터셋에 HopRAG를 적용할 때 성능 변동의 위험을 완화하기 위해 더 넓은 범위의 도메인에서 일반화 능력을 탐색해야 한다. 또한, 더 정교한 질의 시뮬레이션 및 에지 병합 전략은 추가적인 성능 개선으로 이어질 수 있다. 마지막으로, "육단계 분리" 및 "작은 세상" 네트워크 이론에서 영감을 받았지만, 구절 그래프 정점의 차수 분포가 멱법칙 특성을 보이지는 않는다. 이러한 이론은 동기 부여 및 직관적인 유추 역할을 하며, 더 적절한 차수 분포 전략을 탐색하는 것 또한 시도해볼만 하다.
