서론
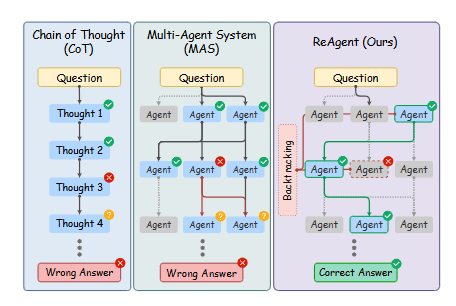
Multi-hop QA의 어려운 점은 오류 전파로, 초기 실수가 최종 결과에 영향을 미치는 점이다. 기존 LLM 기반 CoT(Chain-of-Thought)나 RAG(Retrieval-Augmented Generation) 방식은 순방향 추론(forward-only workflow)에 의존하여, 일단 생성된 오류가 시스템 전체에 지속되고 나중에 발견된 모순이 체계적인 재평가를 유발하지 못한다. Multi-agent collaboration 역시 체계적인 오류 복구 메커니즘이 부족하다. 이러한 한계를 해결하고자, ReAgent는 가역적인(reversible) multi-agent 추론 프레임워크를 제안한다. 이는 충돌 발생 시 에이전트가 이전의 유효한 상태로 되돌아가 오류를 고립시키고 수정할 수 있도록 한다. ReAgent는 local 및 global rollback 프로토콜과 모듈식 역할 특수화를 결합하여 유연하고 오류 허용적인 파이프라인을 제공한다. 이 연구의 주요 기여는 (1) local 및 global backtracking을 지원하는 multi-agent QA 프레임워크, (2) textual 및 graph-based evidence를 통합하는 hybrid retrieval 메커니즘, (3) ReAgent의 효과를 실증적으로 입증하여 forward-only 방법 대비 약 6%의 정확도 향상과 견고성 및 투명성 증대이다.
방법론
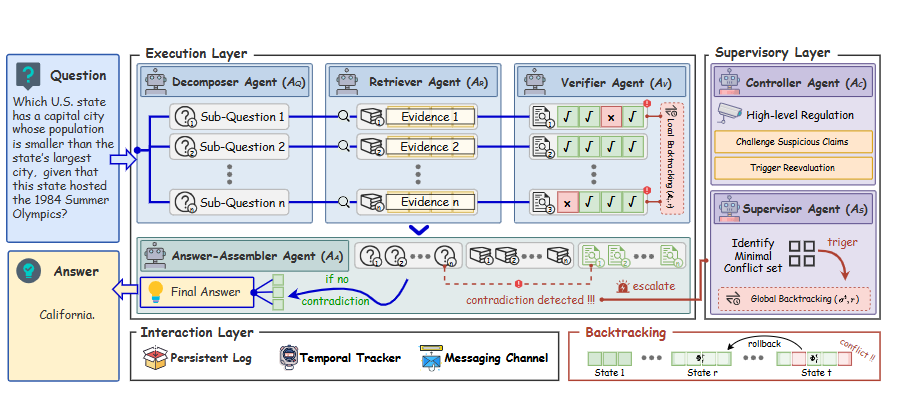
ReAgent는 크게 세 계층으로 구성된다: Execution Layer, Supervisor Layer, Interaction Layer. 각 계층은 고유한 에이전트와 메커니즘을 포함한다.
-
Execution Layer
질문 분해, 증거 검색, 중간 결과 검증, 최종 답변 생성을 담당한다.- Question-Decomposer Agent (AQ): 복잡한 질문 를 개의 하위 질문 으로 분해한다.
- Retriever Agent (AR): 각 하위 질문 에 대해 corpus에서 sparse 및 dense query를 발행하고, reciprocal-rank fusion을 통해 상위 M개 passage를 증거 집합 으로 검색한다. backtracking으로 유효성이 제거된 증거는 재검색된다.
- Verifier Agent (AV): 새로운 증거 와 현재 local 지식 간의 일관성을 검증한다. 충돌 감지 시
BacktrackLocal(AV, r)을 호출하여 일관된 이전 상태로 되돌리거나 상위 에이전트에 신호를 보낸다. - Answer-Assembler Agent (AA): AQ, AR, AV로부터의 local 추론 및 검증된 증거를 취합하여 최종 답변 을 합성한다. 은 다음과 같이 정의된다:
여기서 , , 는 각각 AQ, AR, AV의 지식 집합을 나타낸다. 여러 에이전트에 걸친 충돌은 Supervisor Layer로 escalation한다.
-
Supervisor Layer
시스템 전반의 전략을 감독하며, 여러 에이전트에 걸친 충돌 해결 및 global backtracking을 조정한다.- Controller Agent (AC): 고수준 전략을 조절하며, 특정 규칙이 최적이지 않거나 안전하지 않다고 판단될 경우 이를 재정의하거나
challenge($\phi$)를 발행하여 중요 주장을 여러 에이전트의 관점에서 검토한다. - Supervisor Agent (AS): 여러 지식 집합에 걸친 multi-agent 충돌을 조정한다. 시스템 전반의 모순이 발견되면, 최소 충돌 집합 를 식별하여 이면서도 임의의 proper subset 에 대해서는 인 상태를 만든다. 그리고
BacktrackGlobal($\sigma^t$, r)을 트리거하여 시스템을 이전 상태로 되돌린다.
- Controller Agent (AC): 고수준 전략을 조절하며, 특정 규칙이 최적이지 않거나 안전하지 않다고 판단될 경우 이를 재정의하거나
-
Interaction Layer
각 상호작용 라운드에서의 지식 집합을 저장하고, concurrency model 및 통신 프로토콜을 유지한다.- Persistent Log: 모든 상호작용 라운드의 local 지식 집합 와 global 지식 집합 를 저장한다.
- Temporal Tracker: 메시지 및 행동의 시간 순서 기록을 유지하며, (모든 미래 상태에서 가 유지) 및 (미래 어느 시점에 가 참이 될 수 있음)와 같은 temporal operator를 사용하여 백트래킹 조건을 지정한다.
- Messaging Channel:
msg($\phi$)형태의 assert, inform, reject, challenge 이벤트로 에이전트 간 통신을 가능하게 한다.
-
Conflict Management and Backtracking
시스템은 충돌을 감지하고 일관된 상태로 되돌리는 방법을 공식화한다. 시간 에 허용된 모든 주장들의 집합은 이다. 충돌은 가 특정 명제 와 를 동시에 함의할 때 발생한다.
Local Backtracking: 각 에이전트 는 선택된 체크포인트 에서의 상태 를 기록하는 backtracking graph 를 유지한다. AV가 내부 충돌 를 감지하면BacktrackLocal(A_i, r)을 수행하여 를 이전 일관된 노드 로 되돌린다.
Global Backtracking: 충돌이 여러 에이전트에 걸쳐 발생할 때 AS는 수정되어야 할 최소 충돌 주장 집합을 식별한다.BacktrackGlobal($\sigma^t$, r)연산은 모든 에이전트를 시간 에서 로 되돌린다.
실험
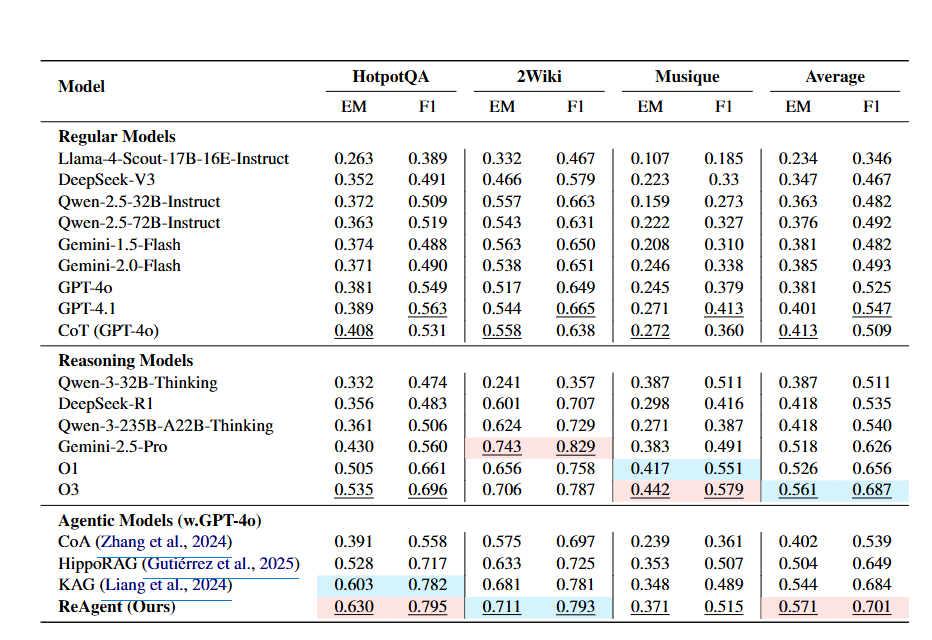
ReAgent는 HotpotQA, 2WikiMultiHopQA, MuSiQue 세 가지 multi-hop QA 벤치마크에서 평가되었다. 다음 세 그룹의 baseline 모델과 비교되었다: (1) Standard LLM (Llama-4, Qwen-2.5, DeepSeek-V3, Gemini-1.5/2.0, GPT-4o, GPT-4.1, CoT(GPT-4o)), (2) Dedicated Reasoning Models (Qwen-3-Thinking, DeepSeek-R1, Gemini-2.5-Pro, O1, O3), (3) Agentic Models (CoA, HippoRAG, KAG). ReAgent의 backbone 모델은 GPT-4o를 사용하며, Question-Decomposer Agent의 temperature는 0.8, 다른 에이전트들은 0.6으로 설정되었다. 평가는 Exact Match (EM) 및 F1 score로 측정되었다.
결과
ReAgent는 모든 데이터셋에서 baseline 모델들을 지속적으로 능가하는 성능을 보였다. 평균 EM 0.571, 평균 F1 0.701을 달성하여, 가장 강력한 agentic baseline인 KAG를 EM에서 2.7%, F1에서 1.7% 능가한다. 특히 O1, O3와 같은 강력한 추론 모델보다도 우수한 성능을 보여주었다. 이는 ReAgent의 모듈형 실행 및 에이전트 간 협업이 복잡한 multi-hop 환경에서 명확한 이점을 제공함을 시사한다. ReAgent는 HotpotQA에서 가장 높은 F1 점수(0.795)를 달성하며 "manageable context length"에서 강력한 성능을 입증했다.
Ablation Study:
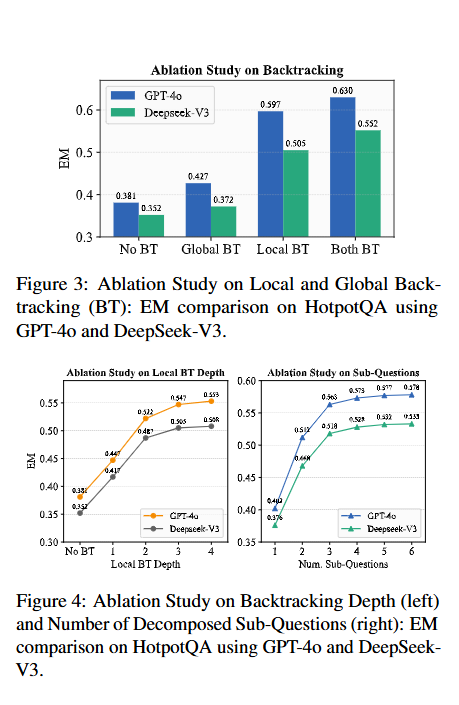
- Backtracking 메커니즘의 효과: backtracking을 비활성화하면 성능이 크게 저하되어, 오류 전파를 완화하는 데 backtracking이 중요함을 보여준다. DeepSeek-V3 backbone에서도 backtracking은 전반적인 개선을 가져왔다.
- Local Backtracking Depth의 영향: local backtracking depth가 증가함에 따라 ReAgent의 성능이 향상되지만, 이점은 점차 포화 상태에 이른다.
- 분해된 하위 질문 수의 영향: 질문을 여러 하위 질문으로 분해하는 것이 성능을 크게 향상시키며, 3개의 하위 질문 사용이 GPT-4o에서 0.161 EM, DeepSeek-V3에서 0.142 EM의 최적 절충점을 제공한다.

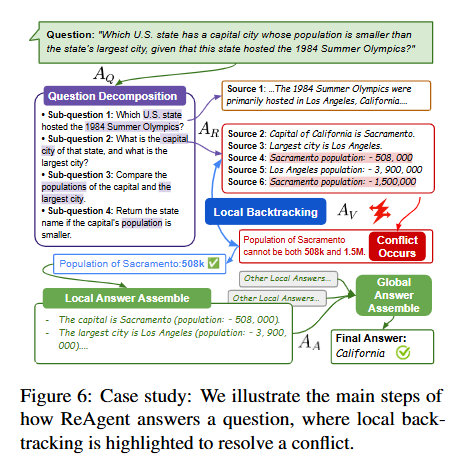
사례 연구
"Which U.S. state has a capital city whose population is smaller than the state’s largest city, given that this state hosted the 1984 Summer Olympics?" 질문에 대한 ReAgent의 답변 과정을 시연한다. AQ는 질문을 하위 질문으로 분해한다. AR은 캘리포니아, 새크라멘토, 로스앤젤레스 관련 정보를 검색한다. 이때 새크라멘토 인구 데이터(508k vs 1.5M)의 불일치가 감지되어 AV가 local backtracking을 트리거하고 신뢰할 수 없는 1.5M 추정치를 폐기한다. 이로써 정확한 정보가 확정되고, AA가 정보를 취합하여 캘리포니아라는 최종 답변을 제시한다.
또한, "What is the name of the fight song of the university whose main campus is in Lawrence, Kansas and whose branch campuses are in the Kansas City metropolitan area?" 질문에서 ReAgent와 O3, CoA 모델을 비교한다. O3와 CoA는 모두 부정확한 "I’m a Jayhawk"를 최종 답변으로 도출하는 반면, ReAgent는 AQ가 6개의 하위 질문으로 분해하고 AR이 "I’m a Jayhawk"와 "Kansas Song" 두 후보를 모두 검색함으로써 명시적인 충돌 상태를 유발한다. AC는 Q4로 되돌아가 증거의 중요도를 재평가하고, "Kansas Song"이 "official"이라는 키워드와 제정 연도(1928)를 포함하는 반면 "I’m a Jayhawk"는 단순한 "rally tune"으로 표기되었음을 식별한다. 이 과정을 통해 ReAgent는 "Kansas Song"이라는 올바른 답변에 성공적으로 도달한다. 이는 ReAgent의 충돌 감지 및 backtracking 메커니즘이 이전 추론을 재검토하고 모순된 증거를 해결하며 정확한 지식 기반 답변으로 수렴함을 보여준다.
결론 및 한계
ReAgent는 multi-hop QA에서 backtracking 메커니즘을 통합하여 오류 전파를 완화한다. 계층적 접근 방식은 추론 과정에서 발생하는 단일 실수가 전체 추론 체인을 무효화하는 오래된 문제를 해결한다. 부분적 또는 전체적 rollback을 허용함으로써 각 에이전트는 충돌하는 증거를 감지하고 수정하여 보다 안정적이고 해석 가능한 솔루션을 제공한다. HotpotQA, 2WikiMultiHopQA, MuSiQue 세 가지 multi-hop QA 벤치마크에 대한 실험은 명시적 backtracking 및 충돌 해결이 forward-only baseline을 넘어선 성능 향상을 가져옴을 입증하며, 복잡한 질문 답변에서 오류 수정의 중요성을 확인한다.
한계점:
ReAgent의 디자인은 추론 시간 증가로 이어져 효율성이 저하될 수 있다. 또한, 복잡한 아키텍처는 제한된 자원이나 노이즈가 많은 입력 시나리오에서 견고성을 감소시킬 수 있다. 향후 연구에서는 에이전트 설계 개선, 특히 협업 전략을 강화하여 오류 전파를 더욱 줄이고 추론 효율성을 높이는 데 중점을 둘 계획이다.
