How Good are LLM-based Rerankers? An Empirical Analysis of State-of-the-Art Reranking Models
Paper Review
Abstract
본 연구는 IR 태스크에서 사용되는 reranking 기법들을 대상으로, 대규모 언어 모델(LLM) 기반 방법, 경량(contextual) 모델, 그리고 zero-shot 접근법을 포함한 체계적이고 포괄적인 실험적 비교를 수행한다. 총 22개의 reranking 방법과, 사용된 LLM에 따라 파생된 40개의 변형을 평가 대상으로 삼았으며, TREC DL19, DL20, BEIR과 같은 기존 벤치마크뿐 아니라 사전학습 데이터에 포함되지 않은 질의를 평가하기 위해 새롭게 설계된 데이터셋을 함께 사용한다.
본 논문의 주요 목적은 통제된 공정 비교를 통해 LLM 기반 reranker와 경량 reranker 간의 성능 격차가 실제로 존재하는지, 특히 신규(novel) 질의에 대해 어떤 차이를 보이는지를 분석하는 데 있다. 이를 위해 학습 데이터 중복 여부, 모델 구조, 계산 효율성 등의 요인이 reranking 성능에 미치는 영향을 분리하여 살펴본다. 실험 결과, LLM 기반 reranker는 이미 익숙한 질의에 대해서는 우수한 성능을 보이나, 신규 질의에 대한 일반화 성능은 방법에 따라 큰 편차를 보이는 것으로 나타났다. 반면, 경량 모델들은 계산 효율성 측면에서 경쟁력 있는 대안을 제시한다. 또한 질의의 참신성(novelty)이 reranking 성능에 중대한 영향을 미친다는 점을 확인함으로써, 기존 평가 방식의 한계를 드러낸다.
1 Introduction
Text reranking은 초기 검색 결과를 사용자 질의에 더 적합하도록 재정렬하는 과정으로, 웹 검색, 오픈 도메인 질의응답, 그리고 RAG 파이프라인을 포함한 다양한 정보 검색 시스템에서 핵심적인 역할을 수행한다. 최근 Transformer 기반 모델과 LLM의 발전으로, 문맥 이해 능력과 zero-shot 추론 능력을 활용한 고성능 reranking 기법들이 등장하였다.
그러나 이러한 모델들은 대규모 사전학습 데이터에 크게 의존하며, 이로 인해 학습 과정에서 보지 못한 신규 질의에 대해 충분히 일반화할 수 있는지에 대한 우려가 지속적으로 제기되고 있다. 특히 기존 벤치마크 데이터셋의 질의들이 수년 전에 수집되었다는 점은, 최신 LLM이 이미 해당 질의에 대한 지식을 내재하고 있을 가능성을 높이며, reranker 성능 평가의 신뢰성을 저하시킨다.
이러한 문제의식 하에, 본 논문은 기존 reranking 모델들이 질의의 신규성에 따라 성능이 어떻게 달라지는지를 분석하고, 이를 보다 공정하게 평가하기 위한 새로운 데이터셋을 제안한다. 또한 pointwise, pairwise, listwise 접근법뿐 아니라, 최근 제안된 setwise 및 tournament 기반 reranking 기법들을 포함하여 다양한 방법론을 비교 분석한다. 이를 통해 모델 구조, 학습 데이터 중복, 계산 비용 간의 상호작용을 체계적으로 탐구하고, reranking 성능에 영향을 미치는 주요 요인을 규명하는 것을 목표로 한다.
Contributions
본 논문의 주요 기여는 다음과 같이 요약할 수 있다.
- LLM 사전학습 데이터에 포함되지 않은 질의들로 구성된 새로운 평가 데이터셋을 제안하여, reranking 기법에 대한 편향 없는 평가 환경을 제공한다.
- LLM 기반, 경량 모델, zero-shot reranker를 포함한 다양한 최신 reranking 접근법을 기존 벤치마크와 신규 데이터셋에서 체계적으로 비교한다.
- 신규 질의에 대한 일반화 성능, 계산 효율성, 모델 아키텍처가 reranking 성능에 미치는 영향을 분석한다.
- reranking 방법의 확장성과 실용성 측면에서 향후 IR 시스템 설계를 위한 시사점을 제시한다.
3 Reranking Approaches
본 절에서는 정보 검색에서 사용되는 주요 reranking 접근법을 pointwise, pairwise, listwise의 세 가지 범주로 나누어 설명한다. 이들 방법은 문서 간 관계를 어떻게 고려하는지, 그리고 효율성과 성능 간의 균형을 어떻게 맞추는지에서 차이를 보인다.
3.1 Pointwise Reranking
Pointwise reranking은 각 질의–문서 쌍을 독립적으로 평가하여 관련성 점수를 부여하고, 이를 기준으로 문서를 정렬하는 방식이다. 계산 복잡도가 O(n)으로 효율적이지만, 문서 간 상대적 중요도를 직접적으로 모델링하지 못한다는 한계를 가진다.
최근에는 Transformer 기반 모델이 pointwise reranking 성능을 크게 향상시켰다. BERT 계열 모델을 활용한 이진 분류 방식, T5 기반 생성 모델을 활용한 relevance 판단, 그리고 대형 모델을 소형 모델로 증류하여 효율성을 높이는 접근법 등이 제안되었다. 또한 별도의 학습 없이 사전학습 모델의 확률 분포를 활용하는 unsupervised 및 zero-shot 방식도 등장하여, 도메인 확장성 측면에서 주목받고 있다.
3.2 Pairwise Reranking
Pairwise reranking은 두 문서를 비교하여 상대적 관련성을 판단하고, 이러한 비교 결과를 누적하여 최종 순위를 산출하는 방식이다. 문서 간 미세한 차이를 효과적으로 구분할 수 있으나, 기본적으로 O(n²)의 계산 복잡도를 가지기 때문에 효율성 문제가 발생한다.
이를 완화하기 위해 정렬 알고리즘이나 슬라이딩 윈도우 전략을 활용한 다양한 최적화 기법이 제안되었으며, LLM을 활용한 프롬프트 기반 비교 방식도 활발히 연구되고 있다. 최근 연구들은 비용이 높은 LLM과 경량 모델을 조합한 다단계 파이프라인을 통해, 성능과 계산 비용 간의 균형을 맞추는 방향으로 발전하고 있다.
3.3 Listwise Reranking
Listwise reranking은 질의와 여러 문서를 동시에 입력으로 받아, 문서 전체의 순서를 한 번에 예측하는 방식이다. 문서 간 상호작용을 직접적으로 모델링할 수 있어 높은 정확도를 기대할 수 있으나, 입력 길이 제한과 위치 편향 문제로 인해 적용이 쉽지 않다.
이를 해결하기 위해 슬라이딩 윈도우를 활용한 재정렬 전략, 효율적인 디코딩 방식, 그리고 지연 시간(latency)을 줄이기 위한 경량화 기법들이 제안되었다. 일부 연구는 LLM의 내부 어텐션이나 토큰 확률을 활용하여 계산 복잡도를 획기적으로 줄이는 접근법을 제시하며, 기존 listwise 방법 대비 경쟁력 있는 성능을 보인다.
4 Challenges in Reranking with LLMs
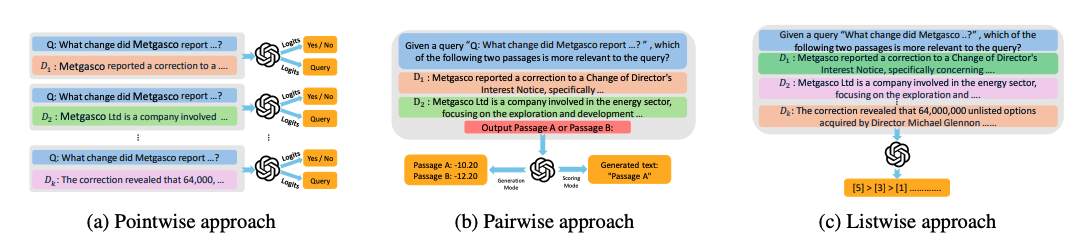
Reranking은 정보 검색(IR)에서 초기 검색 결과를 질의에 더 잘 부합하도록 정제하는 과정이다. LLM은 zero-shot reranking을 가능하게 하지만, 범용 목적의 모델 설계로 인해 미세 조정된 전통적 reranker 대비 여러 한계를 가진다. 주요 문제로는 높은 계산 비용, 외부 API 의존성, 그리고 pointwise·pairwise·listwise 방식 전반에 걸친 예측 불안정성이 존재한다.
Pointwise Reranking의 한계
Pointwise 방식은 질의–문서 쌍을 독립적으로 평가하여 관련성 점수를 산출하며, O(n)의 계산 복잡도를 가진다. 일반적으로 프롬프트를 통해 “Yes/No” 형태의 판단을 생성하고, 출력 토큰의 확률을 점수로 변환한다. 그러나 이 방식은 프롬프트에 따라 점수 분포가 일관되지 않게 보정되는 문제가 있으며, 이는 순위 결정에 반드시 필요하지 않은 과정이라는 점이 지적된다. 또한 확률 점수에 접근할 수 있는 scoring API에 의존하기 때문에, GPT-4와 같은 생성 전용 LLM에서는 적용이 제한된다.
Pairwise Reranking의 한계
Pairwise 방식은 문서 쌍을 비교하여 상대적 관련성을 판단하고, 이를 누적하여 순위를 결정한다. 문서 간 미세한 차이를 구분하는 데 강점이 있으나, 기본적으로 O(n²)의 계산 복잡도를 가지며, 최적화된 변형을 사용하더라도 대규모 문서 집합에서는 확장성이 제한된다. 또한 문서 간 차이가 미묘한 경우 판단이 일관되지 않게 나타나는 문제가 있으며, 초기 검색 품질에 민감하게 반응한다는 한계도 존재한다.
Listwise Reranking의 한계

Listwise 방식은 질의와 여러 문서를 동시에 입력으로 받아 전체 순서를 생성한다. 이 방식은 문서 간 상호작용을 직접 모델링할 수 있으나, 입력 길이가 LLM의 컨텍스트 한계를 초과하는 경우가 잦아 슬라이딩 윈도우나 토너먼트 정렬과 같은 추가 전략이 필요하다. 또한 입력 순서에 따라 결과가 달라지거나 일부 문서가 누락되는 예측 실패 사례가 발생할 수 있으며, 생성 기반 API에 대한 의존성으로 인해 안정성이 저하될 수 있다.
5 Results and Discussion
본 절에서는 pointwise, pairwise, listwise reranking 방법을 다양한 IR 벤치마크와 오픈 도메인 QA 데이터셋에서 평가하며, 성능, 강건성, 그리고 신규 질의에 대한 일반화 능력을 분석한다. 분석은 실험 설정, 데이터셋 구성, 그리고 성능 분석의 세 부분으로 구성된다.
5.1 Experimental Setup
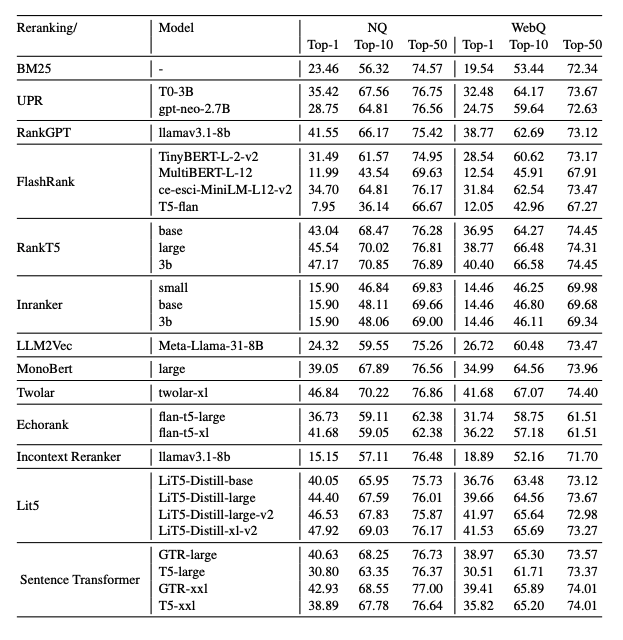
실험에서는 pointwise(MonoT5, RankT5, InRanker, FlashRank), pairwise(PRP, EcoRank), listwise(ListT5, RankGPT, RankVicuna) reranking 방법을 비교하였다. 초기 검색 단계에서는 BM25를 사용하여 질의당 상위 100개 문서를 검색한 후, reranker를 통해 재정렬하였다. 평가는 TREC DL19, DL20, BEIR 데이터셋에 대해 nDCG@10을, Natural Questions와 WebQuestions에 대해서는 Top-1, Top-10, Top-50 정확도를 사용하였다. 모든 실험은 NVIDIA A100 GPU 클러스터에서 수행되었으며, 세 개의 랜덤 시드에 대해 평균을 산출하였다.
5.2 Datasets
TREC DL19 및 DL20은 웹 검색 환경을 모사한 소규모 질의 집합을 제공하며, BEIR은 다양한 도메인에 대한 zero-shot 일반화를 평가하기 위한 8개 데이터셋으로 구성된다. Natural Questions와 WebQuestions는 오픈 도메인 QA 환경에서의 사실 검색 능력을 평가한다. 또한 본 논문은 사전학습 데이터에 포함되지 않은 질의로 구성된 FutureQueryEval을 도입하여, 신규 질의 일반화 성능을 평가한다.
5.3 Performance Analysis
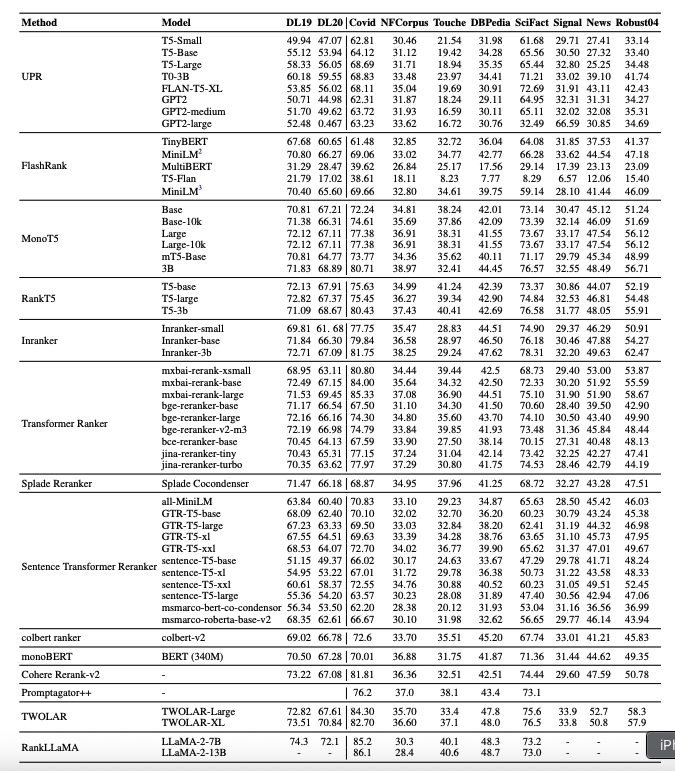
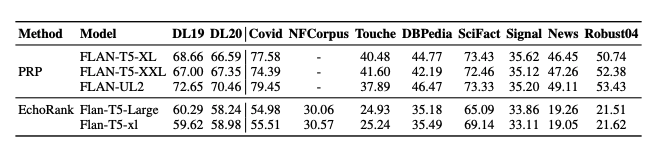
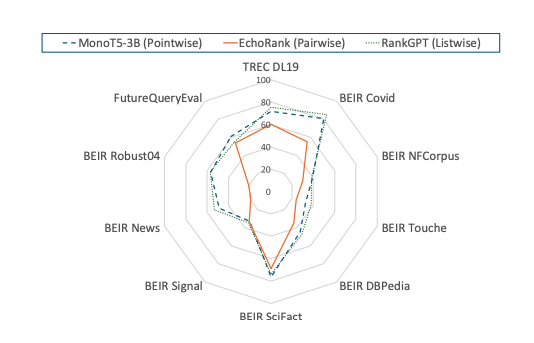
Pointwise 방식에서는 InRanker-3B가 여러 데이터셋에서 가장 안정적인 성능을 보였으며, MonoT5-3B와 Twolar-XL 역시 높은 성능을 기록하였다. 경량 모델들은 효율성과 성능 간의 균형 측면에서 경쟁력을 보였으나, zero-shot 방식은 전반적으로 성능이 낮았다.
Listwise 방식에서는 RankGPT 계열과 Zephyr-7B, ListT5 계열 모델들이 문서 간 상호작용을 효과적으로 활용하여 높은 성능을 보였다. 그러나 입력 길이 제약으로 인해 일부 모델은 성능 저하를 보였다.
Pairwise 방식에서는 PRP 계열이 정밀한 판단에서 강점을 보였으나, 계산 비용과 확장성 측면에서 한계를 드러냈다. 특히 주관적 판단이 요구되는 질의에서는 전반적인 성능 저하가 관찰되었다.
오픈 도메인 QA 실험에서는 pointwise와 listwise 방식이 pairwise 방식보다 전반적으로 우수한 성능을 보였다.
5.4 Discussion and Implications
분석 결과, 기존 벤치마크 대비 FutureQueryEval에서는 모든 방법에서 5–15% 수준의 성능 저하가 관찰되었으며, 이는 reranking 모델이 시간적 변화에 민감함을 시사한다. Listwise 방식은 신규 질의에서 상대적으로 가장 작은 성능 감소를 보였으며, 모델 규모가 커질수록 기존 벤치마크에서는 유리하지만 신규 질의에서는 그 이점이 감소하는 경향이 나타났다. 또한 특정 도메인(논증형, 비정형 텍스트)에서는 모든 방식이 일관되게 어려움을 겪었다.
6 FutureQueryEval
FutureQueryEval은 2025년 4월 이후에 수집된 질의와 문서로 구성된 데이터셋으로, LLM 사전학습 데이터와의 중복 가능성을 제거하는 것을 목표로 한다. 총 148개의 질의가 7개 주제 영역으로 구성되며, 문서 관련성은 3단계 척도로 수동 주석되었다. 질의의 신규성은 GPT-4를 활용하여 검증되었으며, 상세한 구성 과정은 부록에 제공된다.
7 Results on FutureQueryEval
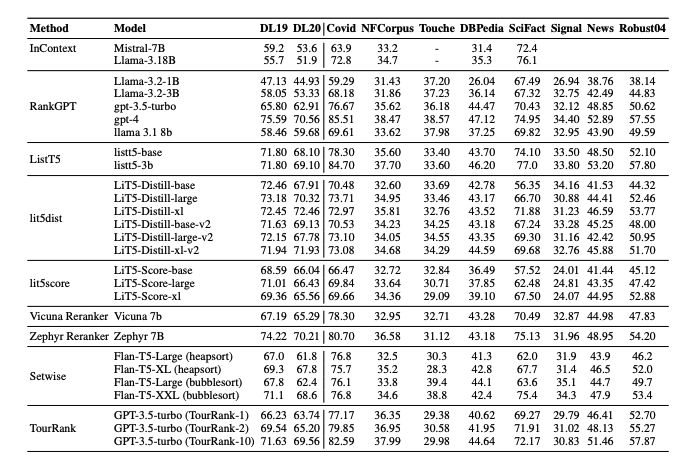
FutureQueryEval 실험 결과, pointwise 방식에서는 MonoT5-3B와 Twolar-XL이 가장 높은 성능을 기록하였다. Listwise 방식에서는 Zephyr-7B와 Vicuna-7B가 문서 간 관계를 효과적으로 모델링하며 우수한 성능을 보였다. Pairwise 방식은 정밀한 신호를 제공하였으나 계산 비용으로 인해 확장성에 제약이 있었다.
7.1 Overall Findings and Implications
전반적으로 listwise 방식이 신규 질의에서 가장 강건한 성능을 보였으며, pointwise 방식은 효율성과 일반화 측면에서 실용적인 대안으로 나타났다. 최신 LLM 기반 방법들은 zero-shot 환경에서도 비교적 우수한 일반화 능력을 보여주었으며, 향후 reranking 시스템은 여러 접근법을 혼합한 하이브리드 전략이 필요함을 시사한다.
7.2 Efficiency–Effectiveness Trade-off
효율성 분석 결과, 경량 모델은 매우 빠른 처리 속도를 보였으며, FlashRank와 Transformer Ranker 계열은 속도와 정확도 간의 균형이 우수했다. 반면 RankGPT 및 일부 listwise 모델은 높은 계산 비용 대비 성능 이점이 제한적이었다.
8 Conclusion
본 논문은 총 22개의 reranking 방법과 40개의 변형을 대상으로, 표준 벤치마크와 신규 데이터셋을 활용한 대규모 실험적 평가를 수행하였다. 결과적으로 LLM 기반 reranker는 기존 질의에서는 강점을 보이나, 신규 질의에 대한 일반화 성능은 일관되지 않았다. 경량 pointwise 모델은 효율성과 성능 측면에서 실용적인 대안을 제공하며, listwise 방식은 가장 높은 정확도를 달성하지만 계산 비용이 크다는 한계를 가진다.
9 Limitations
본 연구는 LLM 기반 reranking의 계산 비용, 할루시네이션 가능성, 도메인 일반화 한계, 그리고 상용 API 의존성이라는 한계를 가진다. 특히 실시간 시스템이나 고신뢰성이 요구되는 환경에서는 이러한 제약이 실제 적용을 어렵게 만들 수 있다.
