LATE CHUNKING: CONTEXTUAL CHUNK EMBEDDINGS USING LONG-CONTEXT EMBEDDING MODELS
Paper Review

summary
짧은 텍스트 세그먼트를 임베딩했을 때 의미가 과압축될 가능성은 낮기 때문에, dense vector based 검색 시스템에서는 짧은 텍스트 세그먼트가 더 나은 성능을 발휘하는 경우가 많다. 그럼에도, 청킹은 주변 청크의 맥락 정보를 잃어 최적이 아닌 표현이 될 수 있다.
본 연구에서는 long context 임베딩 모델을 통해 특정 문서의 모든 토큰에 대해서 임베딩하고, mean pooling 을 하기 전에 청킹을 적용하는 late chunking 방법을 소개한다.
해당 방법은 전체 문맥 정보를 담은 청크 임베딩을 만들 수 있으며, 그 결과 다양한 retrieval task에 우수한 결과를 보였다. 또한 late chunking의 효과를 더욱 높이기 위해, 임베딩 모델을 위한 전용 sft 방법을 제안한다.
Introduction
청킹은 검색 성능을 향상시키는 주요 방법 중 하나이다. 그러나 장거리 의미 의존성(한 텍스트 덩어리를 해석하는 관련 정보가 하나 이상의 다른 덩어리에 위치함)은 검색 전략의 효율성을 감소 시킨다. 예를 들면 figure 1과 같이 첫 번째 문장에서만 언급되는 베를린을 참조하는 its와 The city와 같은 문구를 볼 수 있다. 임베딩 모델이 이들을 각 엔터티에 연결하여 고품질 표현을 생성하는 것은 어려운 일이다.

이를 해결하기 위해, 본 연구는 late chunking 기술을 소개한다. 이 방법은 최근 임베딩 모델들의 long text embedding capa를 활용한다.
먼저, 전체 문서의 각 토큰을 임베딩한다. 이는 문서의 모든 문맥을 각 토큰 임베딩 시퀀스에 주입하는 작업이다.
그 다음, 이 시퀀스를 청크로 나누고, 이 청크를 mean pooling을 통해 최종 청크 임베딩을 만든다.
이 방법으로 만든 청크 임베딩은 전체 텍스트에서 해당 위치에서 파생된 관련 의미 정보가 포함된다.
나이브 임베딩과 late chunking 임베딩 간 결과를 비교하기 위해 앞서 언급한 figure 1을 가지고 임베딩 결과에 대한 유사도 검색을 비교한다. jina-embeddings-v2-small을 통해 텍스트를 인코딩한 후, berlin이라는 단어 임베딩과의 유사도를 계산한다. table 1은 나이브 청킹을 통해 berlin이라는 단어를 포함하지 않는 텍스트의 유사성 점수가 낮다는 것을 보여준다. 그러나 late 청킹을 사용하면 유사성 점수가 훨씬 높아진다는 것을 알 수 있다. 이는 청킹 전, 해당 문맥을 보기 때문이다.

METHOD
Late chunking은 최신 임베딩 모델들의 긴 컨텍스트 입력 창과, 대부분의 응용에서 최적의 텍스트 청크 크기가 상대적으로 매우 작다는 점의 차이를 활용하기 위한 전략이다. 예를 들어 jina-embeddings-v2-small은 8192 토큰(표준 텍스트 약 10쪽 분량)을 입력으로 지원하지만, 최적의 청크 크기는 보통 문단 정도로 훨씬 작다. 이는 LLM이 긴 문맥을 처리할 때 비효율적이 되고, 하나의 짧은 임베딩 벡터가 표현할 수 있는 정보량이 제한적이기 때문이다.
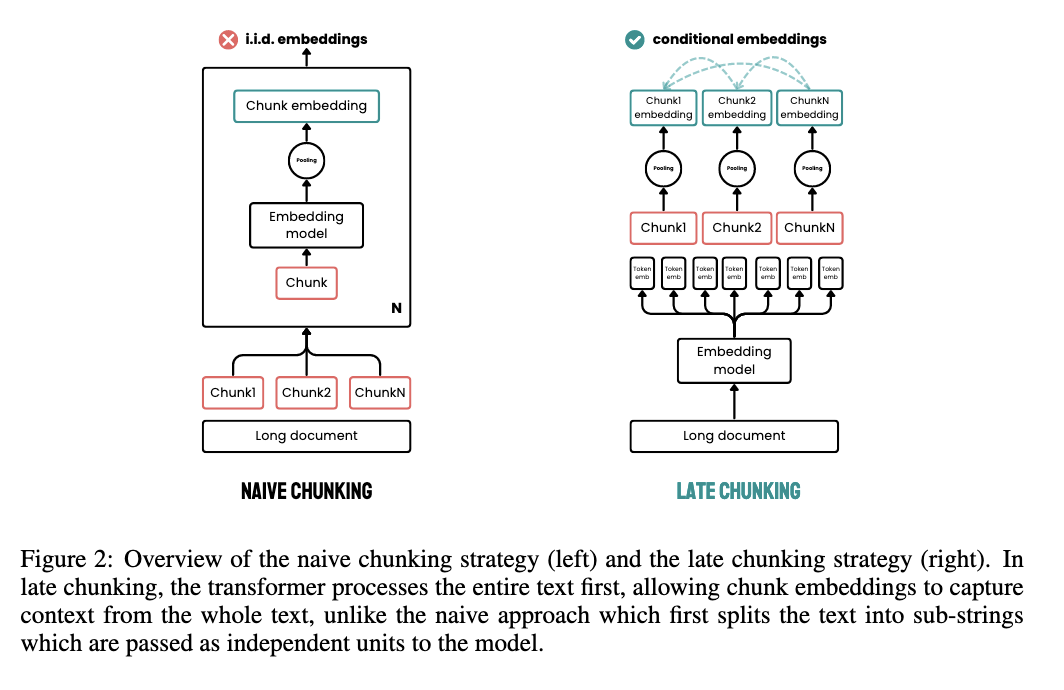
Naive chunking 방식 (figure 2 왼쪽)
기존 방식에서는 텍스트를 먼저 문장이나 문단 단위로 청킹한 뒤, 각 청크를 독립적인 입력으로 임베딩 모델에 넣어 청크 임베딩을 생성한다. 이 방식에서는 각 청크가 전체 문맥을 공유하지 못한 채 분리된 단위로 처리된다.
Late chunking 방식 (figure 2 오른쪽)
Algorithm 1에서 설명한 late chunking은 다음 방식으로 동작한다.
- 텍스트 전체 또는 가능한 가장 긴 부분을 먼저 토크나이즈한다(2행).
- 임베딩 모델의 Transformer를 전체 텍스트에 적용한다(3행).
이렇게 하면 문서 전체 맥락을 반영하는 토큰 수준 벡터 표현 θ₁~θₘ 이 생성된다. - 기존 임베딩 모델은 이 토큰 벡터 전체에 mean pooling을 적용하여 단일 벡터를 만든다.
- Late chunking은 이 절차를 변경하여, 전체 토큰 임베딩을 생성한 후에 작은 구간 단위로 나누어 구간별 mean pooling을 수행한다.
이로써 각 청크 임베딩은 문서 전체의 문맥을 고려한 상태에서 생성된다.
late chunking이라는 이름은 임베딩 모델 처리 이후에 청크 경계가 적용된다는 점에 따른 것이다.
경계 정보(boundary cues)
late chunking에서도 청킹 알고리즘이 제공하는 청크 경계 정보가 필요하나, 이 정보는 토큰 임베딩을 생성한 뒤에만 사용된다.
기존 청킹은 보통 문자 단위로 경계를 설정하지만, late chunking에서는 토큰 단위의 경계가 필요하다.
Algorithm 1의 5–13행은 문단/문자 기반 청크 정의를 토큰 기반 경계 정보로 변환하는 과정이고, 14–16행에서는 해당 경계를 이용하여 각 청크 단위로 mean pooling을 적용한다.
Long Late Chunking
많은 임베딩 모델이 한 번에 상당히 많은 양의 텍스트를 인코딩할 수 있을 만큼 긴 컨텍스트 길이를 제공하지만, 그럼에도 매우 큰 문서 전체를 한 단계로 인코딩하기에는 컨텍스트 길이가 충분하지 않을 수 있다. 또한 토큰 수가 증가할수록 인코딩에 필요한 메모리가 지수적으로 증가하므로, 모든 토큰을 한 번에 인코딩하는 것은 비현실적이 될 수 있다.
이 문제를 해결하기 위해 본 연구에서는 알고리즘 2에서 설명한 long late chunking을 제안한다. 이 방법에서는 텍스트를 여러 개의 큰 매크로 청크(macro chunk)로 나누는데, 각 매크로 청크는 l_max 토큰 크기를 가지며, 이 안에는 여러 개의 더 작은 청크들이 포함된다. 각 매크로 청크는 LateChunking 메서드를 사용하여 독립적으로 처리된다.
문맥 손실을 방지하기 위해, 각 매크로 청크는 다음 매크로 청크와 ω개의 토큰을 겹치게(오버랩) 구성한다. 이 추가 토큰들은 late chunking 수행 시 보조적인 문맥 정보로 활용된다.