
Intro
jina-code-embeddings는 자연어 질의로부터 코드를 검색하고, technical QA를 수행하며, 프로그래밍 언어 전반에서 의미적으로 유사한 코드 스니펫을 식별하기 위해 설계된 새로운 코드 임베딩 모델이다. 텍스트와 코드로 pre-trained된 autoregressive backbone으로, last-token pooling을 통해 임베딩을 생성한다.
Cursor, Claude Code와 같은 AI 기반 개발 환경의 빠른 도입은 소프트웨어 엔지니어링을 변화시켰으며, 코드 임베딩 모델은 이러한 시스템의 검색과 컨텍스트 엔지니어링을 위한 핵심으로 자리매김하였다.
코드 임베딩 모델은 전용 벤치마크와 리더보드를 갖춘 잘 정립된 하위 분야로 발전해왔다. Codex와 같은 코드 생성 모델은 자연어 프롬프트로부터 직접 코드를 합성할 수 있지만, 실제 코드 생성은 기존 코드베이스, API 사용 패턴, 통합 요구사항에 대한 맥락적 이해를 필요로 한다. 따라서 코드 생성 시스템은 임베딩 모델이 핵심 리트리버로 작동하는 RAG의 한 유형으로 자연스럽게 활용된다.
하지만, 현재의 코드 임베딩 모델은 근본적으로 학습 데이터의 제약을 받는다. 지도 학습은 일반적으로 인라인 주석, 문서 strings, 기술 문서의 교육용 예제와 같은 aligned 데이터에 의존하는데, 이는 복잡한 실제 개발 시나리오를 위한 충분한 의미적 기반을 제공하지 못한다. 반면, LLM 학습에 활용되는 방대한 un-aligned 코드와 자연어 문서는 임베딩 모델 개발에 거의 활용되지 않고 있다.
이를 해결하기 위해 두 가지 고품질 코드 임베딩 모델인 jina-code-embeddings-0.5b 와 1.5b를 본 연구에서 소개한다.
첫째, 사전 학습된 코드 생성 LLM을 임베딩 생성에 특화되도록 재적용하였다.
둘째, 코드 임베딩 응용의 기능 영역 전반에 대한 분석을 통해, 각 사용 사례에 최적화된 맞춤형 학습 전략을 설계하였다.
그 결과, 제안된 모델은 유사한 크기의 기존 모델을 크게 능가하며, 훨씬 큰 규모의 모델과도 경쟁할 수 있는 벤치마크 성능을 달성하였다.
Model Architecture and Task Prefixes
jina-code-embeddings-0.5b와 1.5b는 autoregressive decoder backbone architecture를 사용한다. 모두 SLM인 Qwen2.5-Coder-0.5B 및 Qwen2.5-Coder-1.5B를 기반으로 구축되었다.
LLM의 final hidden layer은 last-token pooling을 통해 임베딩으로 변환된다. 실험 결과, last-token pooling이 mean pooling이나 latent attention pooling보다 더 우수한 성능을 보였음을 확인하였다. CLS Pooling 실험하지 않았으나, 일반적으로 디코더 전용 아키텍처에서는 선호되지 않는다.
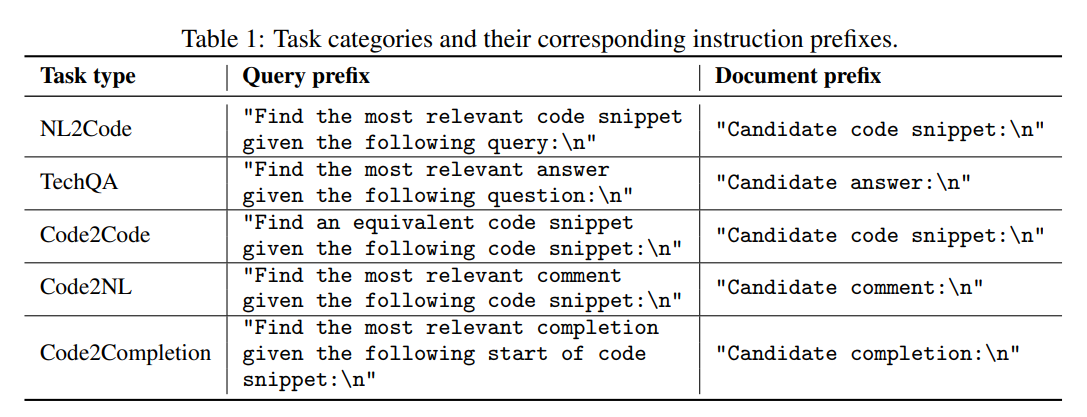
해당 연구는 downstream code embedding tasks를 분석하고 이를 다섯 가지 범주로 나누었다:
- 자연어 → 코드 검색(NL2Code),
- 기술 질의응답(TechQA),
- 코드 → 코드 검색(Code2Code),
- 코드 → 자연어 검색(Code2NL),
- 코드 → 코드 보완 검색(Code2Completion).
각 태스크에 대해, 모델에 전달되는 텍스트 앞에 붙이는 instruction string을 작성하였으며 쿼리와 문서에는 서로 다른 지시문을 사용한다.
Training
모델은 Qwen2.5-Coder-0.5B의 가중치로 초기화한 뒤, I InfoNCE loss function를 활용한 contrastive objective을 적용하였다.
입력 쌍은 related와 unrelated으로 구분되며, 모델은 연관된 항목은 가깝게, 비연관된 항목은 멀리 임베딩하도록 학습한다.
또한, 학습 과정에서 Matryoshka representation learning을 사용하여 truncatable embeddings을 생성하였다. 이를 통해 사용자는 정밀도와 자원 사용량 사이에서 유연하게 균형을 조절할 수 있다.
Training Data
학습 데이터는 다양한 코드 검색 태스크를 위한 query-document pairs 으로 구성되어 있다.
- query: 주로 docstring, 주석(comments), 커밋 메시지(commit messages), 문제 설명(problem statements)
- document: 이에 대응하는 code snippets, diffs, 답변(answers)
또한, 컴퓨터 기술과 관련된 인터넷 포럼의 질문과 답변도 일부 사용하였다.
이러한 쌍들은 여러 출처에서 수집되었으며,
- MTEB 코드 태스크 학습 분할 데이터,
- 비-MTEB 코드 검색 데이터셋 CoSQA+,
- 다른 목적으로 원래 제작된 공개 데이터셋을 재활용 및 변형하여 사용하였다.
더불어, 데이터가 부족할 경우 GPT-4o 를 활용하여 합성 데이터셋을 생성하였으며, 합성된 예시는 샘플을 수작업으로 검토하여 검증하였다.
Procedure
-
각 학습 단계에서, 배치
의 개 query-document 쌍을 샘플링한다.
-
선택된 모든 텍스트에 대해 정규화된 임베딩을 생성한다.
-
모든 쿼리 임베딩 와 문서 임베딩 조합의 코사인 유사도를 계산하여, 유사도 행렬 를 구축한다.
-
동일 쌍 는 유사한 것,
같은 배치 내의 그 외 조합 는 비유사한 것으로 학습한다. -
최종적으로, 유사도 점수 행렬에 대해 contrastive InfoNCE loss function 를 적용한다:
여기서,
- : temperature, training hyperparameter
- : batch size
- 작은 유사도 차이에 더 큰 가중치를 부여하여 손실 계산에 반영되도록 한다
Evaluation
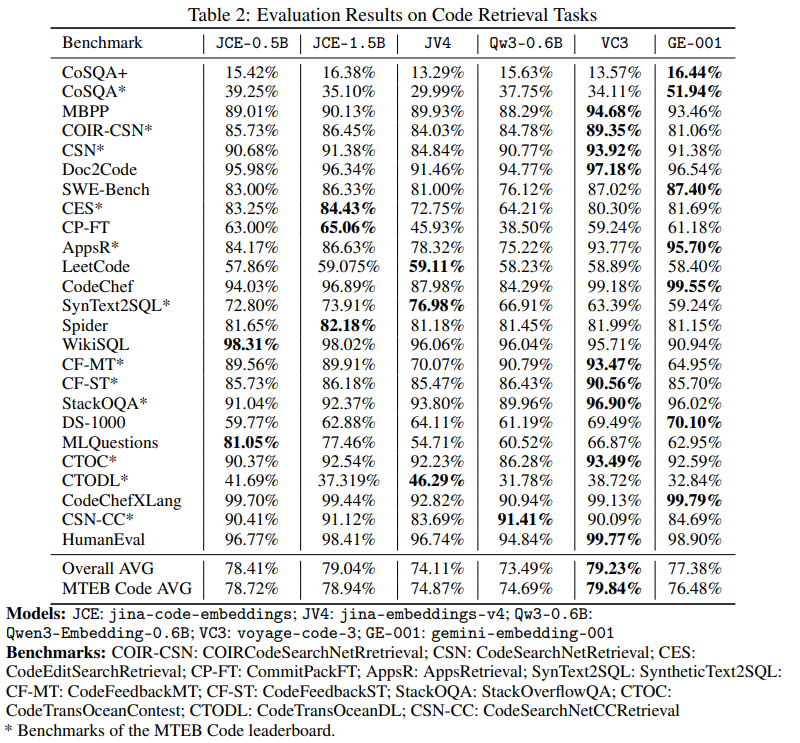
코드 검색 성능을 평가하기 위해, 모델을 MTEB-CoIR에서 실험하였다. 이 벤치마크는 텍스트→코드, 코드→텍스트, 코드→코드, 하이브리드 코드 검색 유형에 걸친 10개 태스크로 구성된다.
또한, 모델을 다음의 코드 관련 MTEB 태스크에서도 평가하였다:
- CodeSearchNetRetrieval
- CodeEditSearchRetrieval
- HumanEval
- MBPP
- DS-1000
- WikiSQL
- MLQuestions
추가로, CosQA+ 및 in-house 벤치마크에서도 성능을 검증하였다.
- jina-code-embeddings-0.5b와 1.5b는 유사한 크기의 범용 임베딩 모델 Qwen3-Embedding-0.6B를 능가하였으며,
- 훨씬 더 큰 모델인 jina-embeddings-v4 및 gemini-embedding-001보다도 우수한 성능을 보였다.
Conclusion
jina-code-embeddings라는 코드 임베딩 모델 0.5B 및 1.5B의 주요 기여점은 다음과 같다:
- autoregressive backbone pre-trained on both text and code
- task-specific instruction prefixes and last-token pooling
이를 통해 모델은 코드 검색과 관련된 다양한 태스크 및 도메인에서 우수한 성능을 달성했다.
