[논문리뷰] LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures
Paper Review

Introduction
LLM 학습에서 기존의 next-token prediction 접근법을 넘어, Joint Embedding Predictive Architectures (JEPA)를 도입하려는 시도를 다룬다.
reconstruction 방법과 JEPA 방법을 비교하면,
JEPA는 같은 표현을 다른 View로 볼 수 있도록 고정하면스 임베딩이 collapse 되지 않도록 학습할 수 있다고 한다.
CV 분야에서는 JEPA가 이미 표현 학습에서 강력한 성능을 보였지만, NLP에서는 아직 적용된 사례가 없었다. 저자들은 코드 ↔ 자연어 설명, SQL ↔ 질의와 같이 “multi-view”가 존재하는 데이터셋을 활용하면 LLM에도 JEPA 목표를 결합할 수 있다고 주장한다.
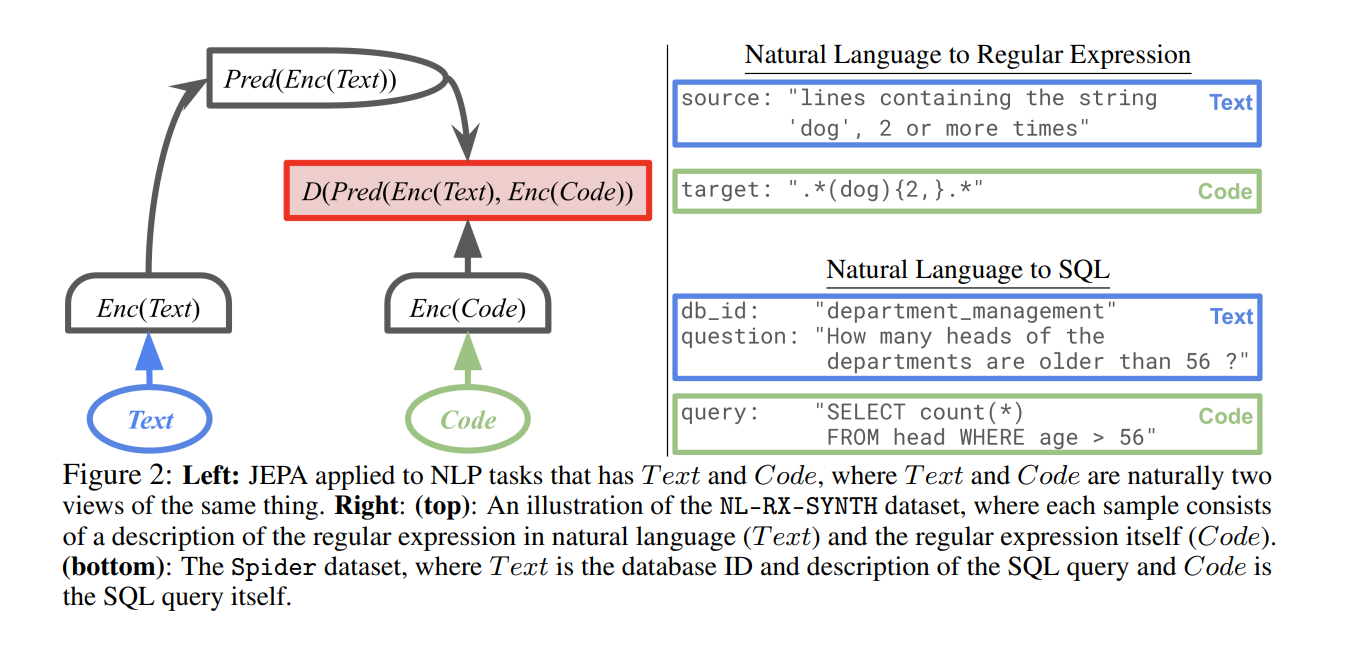
Method
제안된 손실 함수는 기존 LLM 손실과 JEPA 손실을 결합한 형태이다.

- Encoder는 LLM 마지막 레이어의 hidden_state of the last token를 활용한다.
- Predictor는 [PRED] 토큰을 붙여 self-attention을 통해 타깃 임베딩을 예측한다.
- Metric은 코사인 유사도를 사용한다.
추가 하이퍼파라미터로는 λ(JEPA 손실 가중치)와 k(predictor 토큰 수)가 있다,
Results
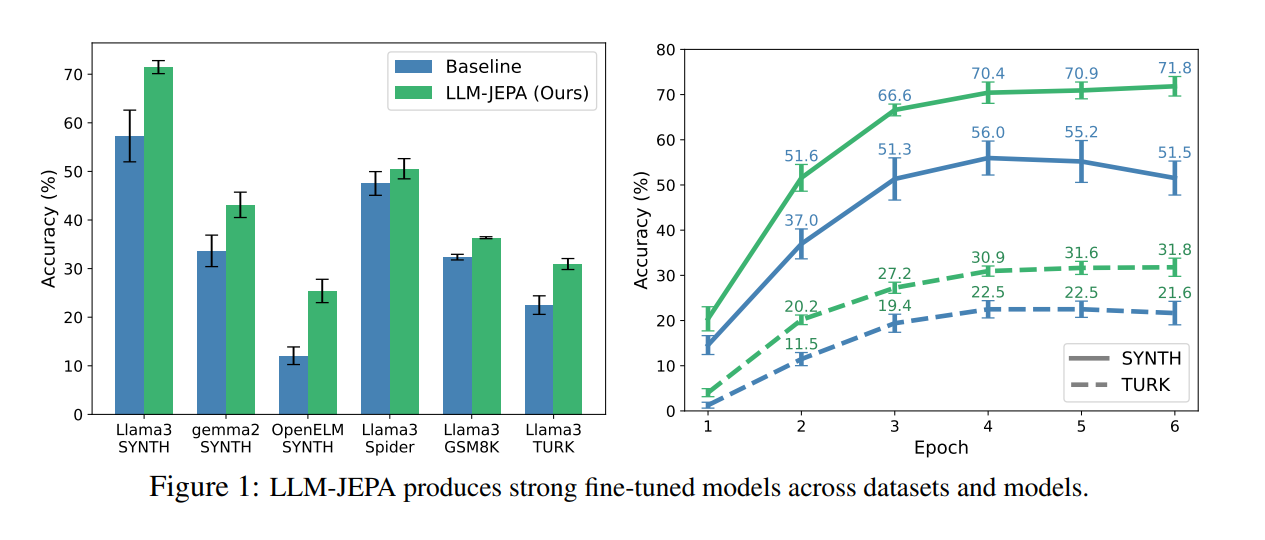

Fine-tuning
다양한 모델과 데이터셋에서 baseline 대비 일관된 성능 향상이 확인되었다.
LLM-JEPA는 모델, 데이터셋, 학습 시간, 모델 크기 전반에서 기존 LLM보다 향상된 성능을 보여주었다.또한 LoRA rank가 달라져도 LLM-JEPA의 성능 개선 효과는 유지되었다.
Pretraining
Llama-3.2-1B-Instruct 모델을 무작위 초기화한 뒤 NL-RX-SYNTH 데이터셋으로 사전학습을 진행했다. 정답 문자열로 시작하면 유효한 예측으로 간주했는데, 이때도 LLM-JEPA는 학습된 표현의 품질을 개선함을 확인했다.
cestwc/paraphrase 데이터셋에서도 실험을 진행했다. 같은 그룹 내 문장들을 JEPA 손실 계산에 활용했고, 4 epoch 동안 사전학습한 후 RottenTomatoes 데이터셋에서 1 epoch 파인튜닝을 진행했다. 그 결과, JEPA 사전학습은 파인튜닝 이후의 다운스트림 성능까지 개선했다. 중요한 점은 파인튜닝 단계에서는 JEPA 손실을 사용하지 않았음에도, 사전학습 단계에서 얻어진 이점이 그대로 전이되었다는 것이다.
Representation Analysis
t-SNE 분석 결과, LLM-JEPA는 Text와 Code 임베딩을 구조적으로 정렬시키는 효과를 보였다.
또한 SVD 분석 결과, Text에서 Code로의 매핑이 선형 변환에 가깝다는 사실이 확인되었다.
Scalability
1B에서 7B 규모 모델까지 일관된 성능 향상이 나타났다.
8B 모델에서도 성능이 개선되었으나 regular expression termination과 같은 문제가 일부 관찰되었다.
Conclusion
본 논문은 JEPA를 LLM 학습에 최초로 도입한 연구로서, 다양한 태스크에서 LLM의 생성 능력을 유지하면서도 추상적 표현 학습 능력을 향상시킨다는 점을 다양한 데이터셋과 모델에서 실험적으로 보였다.
그러나 약 3배의 연산 비용 증가, 다중 뷰 데이터셋에 대한 의존성, λ와 k 하이퍼파라미터 튜닝 비용과 같은 한계가 존재한다.
향후 연구에서는 self-attention masking으로 단일 forward pass에서도 LLM-JEPA 손실을 계산할 수 있는 방법을 찾는다고 한다.
