검증 곡선에 대하여
모든 학습 및 검증 과정에서는 장점과 단점이 있고 그것을 보여주는 것이 바로 오류이다. 근데 우리가 어느 한 모델을 검증할 때 오류를 수치적으로 살펴보기보다 그래프로 보는 것이 더 나을 때가 있다. 그 때 검증 곡선을 이용해 직관적으로 모델이 과적합되었는지 확인할 수 있다.
- 편향(Bias) : 다른 훈련 세트에 대하여 평균적인 오류를 나타냄
- 분산(Variance) : 다양한 훈련 세트에 대하여 얼만큼 민감하게 반응하는지 알 수 있는 지표임
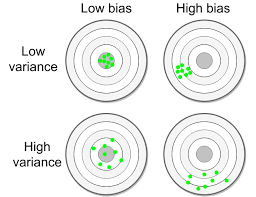
- 편향-분산 표를 이용해 편향이 어떤지 분산이 무엇인지 직관적으로 알 수 있다.
- 중심점과 멀어져 있으면 높은 편향을 가지고 있다는 것이고 높은 분산은 데이터 타겟들이 뭉쳐있기보다 분산 되어 있다는 것을 의미한다.
실제 그래프로 살펴보기
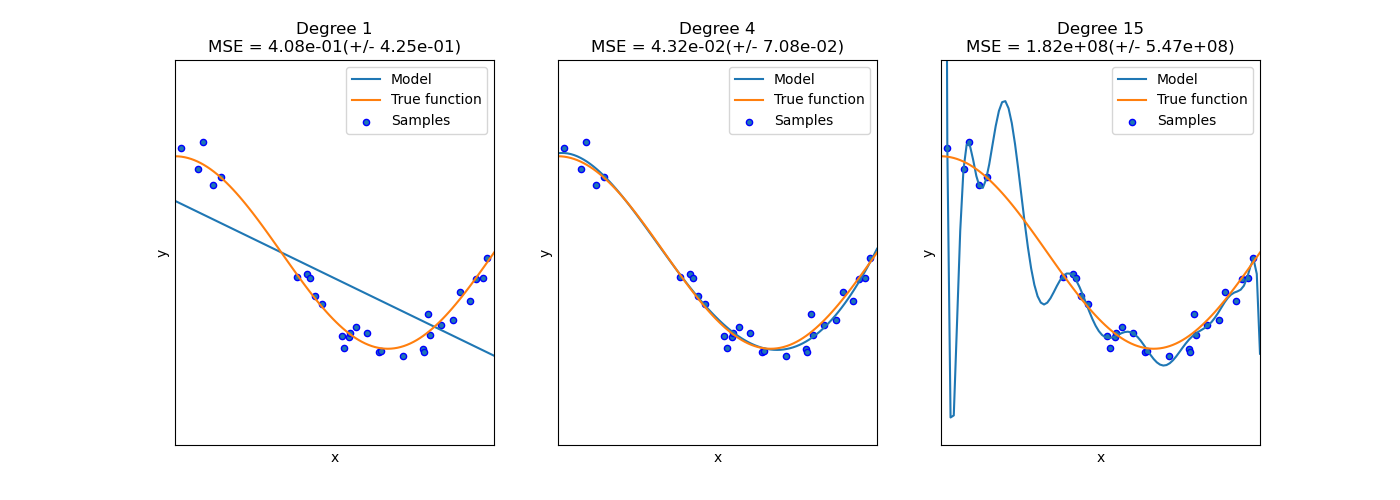
이 그래프를 살펴보게 되면 실제 그래프의 모습과 모델이 그린 그래프의 모습이 다른 것을 알 수 있다.
- 1번의 경우 과소적합(Underfitting) 되어 있는 것을 알 수 있다.
- 2번의 경우 모델의 적합이 잘 된 것을 알 수 있다.
- 3번의 경우 과적합(Overfitting) 되어 있는 것을 알 수 있다.
검증 곡선의 목적은 "분산과 편향을 낮은 상태로 유지하기" 위한 모델, 최적 파라미터를 찾는 것이다.
검증 곡선
검증 곡선을 그리는 과정에는 Scoring, Grid Search와 같은 하이퍼파라미터를 찾는 과정이 선수가되어야 한다.
기본 형식
import numpy as np
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_iris
from sklearn.linear_model import Ridge
np.random.seed(0)
X, y = load_iris(return_X_y=True)
indices = np.arange(y.shape[0])
np.random.shuffle(indices)
X, y = X[indices], y[indices]
train_scores, valid_scores = validation_curve(
Ridge(), X, y, param_name="alpha",
param_range=np.logspace(-7, 3, 3), cv=5
)
print(train_scores, valid_scores)- 여기서
valid_scores = test_scores라고 보면 된다. - 각각의 평균과 표준 편차를 알고 싶으면
np.mean(),np.std()를 활용하면 된다.
학습 곡선
학습 곡선은 다양한 샘플에 대하여 검증 및 훈련 점수를 보여주는데 활용된다. 우리가 어느정도의 훈련 데이터를 넣었을 때 도움이 되는지 찾는 과정이라고 볼 수 있다.
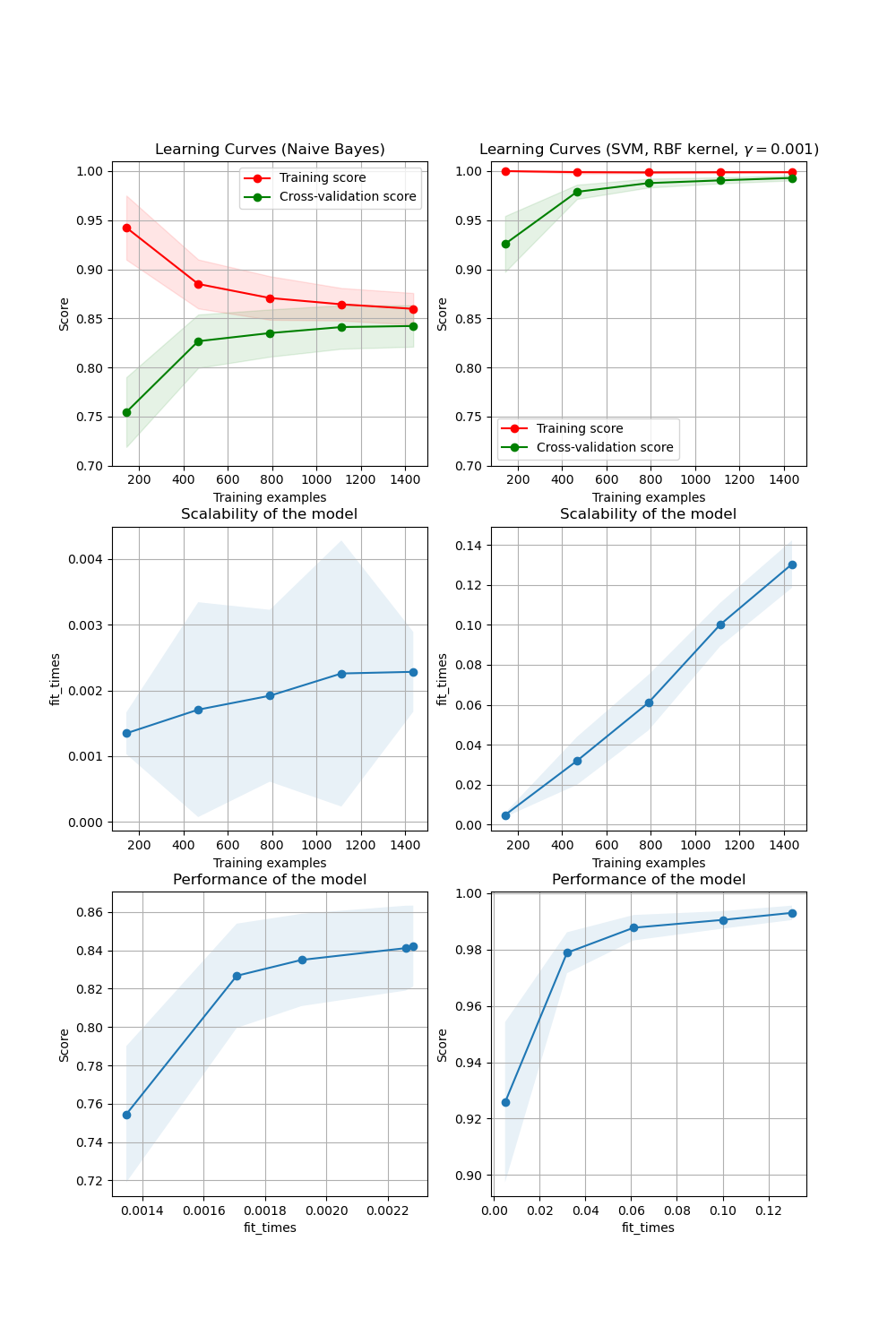
기본 함수
from sklearn.model_selection import learning_curve
from sklearn.svm import SVC
train_sizes, train_scores, valid_scores = learning_curve(
SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5
)
print(train_sizes, train_scores, valid_scores)이 내용은 Scikit-Learn Docs를 기반으로 번역 및 정리하였습니다.

https://medium.com/@jinsung1048 미디엄으로 이전하였습니다.