Naive Bayes
Naive Bayes는 기본적인 지도학습 알고리즘으로 "Bayes" 이론을 기반으로 하는 요소이다.
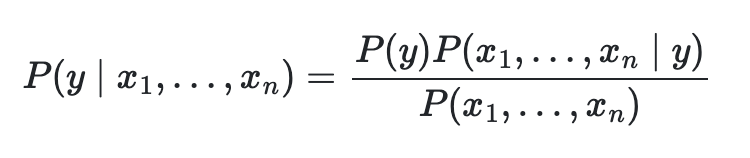
위 식을 보게 되면 통계에서 자주 사용하는 독립적인 요소끼리의 교차집합 확률을 계산하는 식을 볼 수 있다. 여기서 y와 x는 서로 독립적인 관계이다.
Naive 조건적인 독립을 가정하면
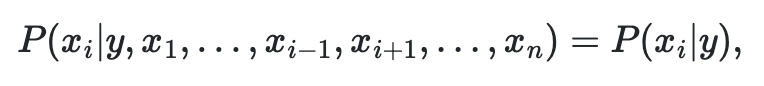
모든 i에 대하여 단순하게 정리를 하면
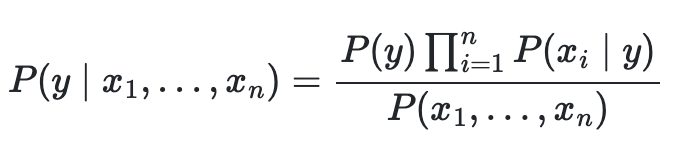
P(x1, ..., xn)을 상수로 가정했을 때 분류식은 다음과 같다.
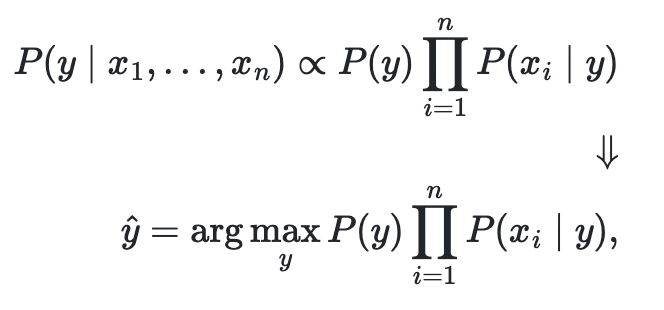
독립적이라는 말은 서로 관련이 없다는 말로 분류도 서로의 카테고리를 나누는 것이므로 관련이 없는 것이라 같은 결 내에서 서로 분류가 되는 것이다.
가우시안 나이브 베이즈(Gaussian Naive Bayes)
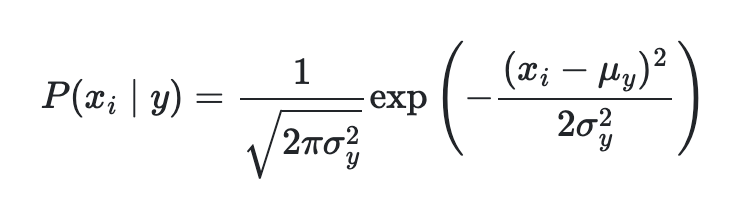
각 개별 요소의 확률을 계산할 때 찾는 방식이고 가장 기본적인 Naive Bayes 함수이다.
기본 함수
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
gnb = GaussianNB()
y_pred = gnb.fit(X_train, y_train).predict(X_test)
print("Number of milabeled points out of a total %d points : %d" % (X_test.shape[0], (y_test != y_pred).sum()))다항 나이브 베이즈(Multinomial Naive Bayes)
기본적으로 다항 분포 데이터를 위한 알고리즘이다. 주로, 텍스트 분류를 하는데 사용된다. 텍스트 각각 고유의 카운트나 특징들이 있는데 이는 각 클래스마다 벡터를 계산해 쎄타로 표현한다. 만약 각 고유의 세타를 알고 싶다면 아래와 같다.
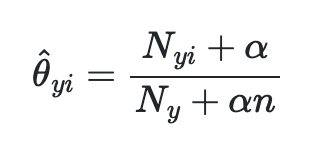
보완적인 나이브 베이즈 (Complement Naive Bayes)
CNB 알고리즘 기반으로 표준 다항 나이브 배이즈를 불균형 데이터에 맞게 수정한 알고리즘이다. SVM에서도 공부했듯이 모든 알고리즘은 불균형 데이터를 균형 데이터로 맞추기 위해 weight를 사용한다.
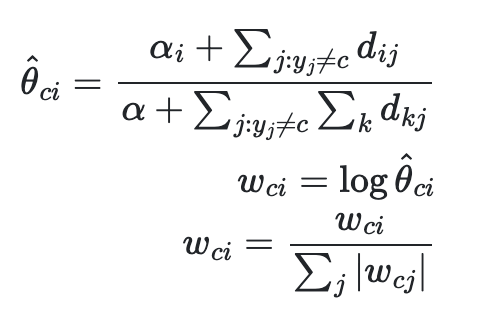
여기서도 기본 쎄타 식에 각 N마다 weight를 집어넣어서 밸런스를 맞추는 것을 알 수 있다.
베르누이 나이브 베이즈 (Bernoulli Naive Bayes)
베르누이 나이브 베이즈는 다변량 베르누이 분포 형식을 따라하는 데이터를 학습하고 분류하기 위한 최적의 알고리즘이다. 주로, 이진값을 가진 것에 대하여 분류를 하고 이러한 요소는 베르누이를 적용하기에 아주 특화되어 있다. 아래의 수학 공식을 보면 2가지 x, 1-x로 나눠줘 있어서 서로 다르게 분류하기가 괜찮다.
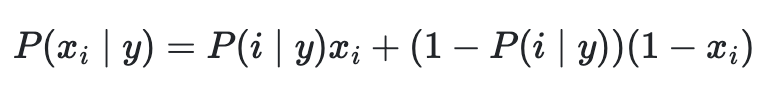
이번 나이브 베이즈(Naive Bayes) 공부하기는 Scikit-Learn Docs를 기반으로 정리하였습니다.
