
1. Embedding Layer
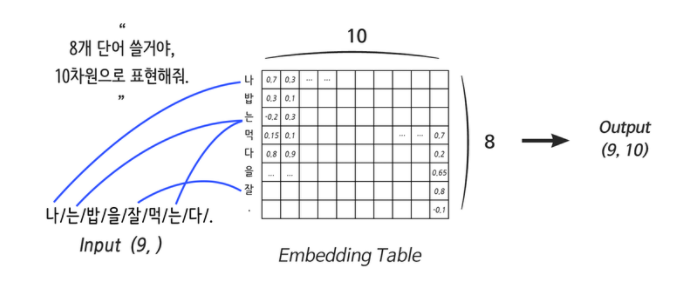
Embedding Layer란 간단하게 말하면 컴퓨터용 단어 사전이다. N개의 단어를 사용자가 지정해주면 컴퓨터가 사전을 만들고 데이터를 거쳐 각 단어의 의미(분산 표현)를 업데이트 한다.
그리고 Embedding size를 정해주면 단어를 더 깊게 표현할 수 있다.
💡Tip 분산표현(Distributed Representation)
- 유사한 맥락이 나타나는 단어들끼리는 두 단어 벡터 사이의 거리를 가깝게 하고 그렇지 않은 단어들끼리는 멀어지도록 조금씩 조정해 주고 이러한 방식으로 얻어지는 단어 벡터를 단어의 분산 표현이라고 한다.
- 분산 표현을 상요하면 희소 표현과는 다르게 단어 간의 유사도를 계산으로 구할 수 있다는 장접이 있다.
Embedding Layer는 입력으로 들어온 단어를 분산 표현으로 연결해 주는 역할을 하는데 그것이 Weight에서 특정 행을 읽어오는 것과 같아 이 Layer를 Lookup Table이라고 부르기도 한다.
💡Tip One-hot Encoding
Lookup Tabel에 매핑이 되는 부분은 어떤 원리로 작동하는지를 알기 위해서는 One-hot Encoding을 먼저 알아야 한다.One-hot Encoding에 Linear Layer를 적용한 코드
import tensorflow as tf vocab = { # 사용할 단어 사전 정의 "i": 0, "need": 1, "some": 2, "more": 3, "coffee": 4, "cake": 5, "cat": 6, "dog": 7 } sentence = "i i i i need some more coffee coffee coffee" # 위 sentence _input = [vocab[w] for w in sentence.split()] # [0, 0, 0, 0, 1, 2, 3, 4, 4, 4] vocab_size = len(vocab) # 8 one_hot = tf.one_hot(_input, vocab_size) print(one_hot.numpy()) # 원-핫 인코딩 벡터를 출력해 봅시다. distribution_size = 2 # 보기 좋게 2차원으로 분산 표현하도록 하죠! linear = tf.keras.layers.Dense(units=distribution_size, use_bias=False) one_hot_linear = linear(one_hot) print("Linear Weight") print(linear.weights[0].numpy()) print("\nOne-Hot Linear Result") print(one_hot_linear.numpy())
📄Output

One-hot Vector에 Linear Lyaer를 적용하니 Linear Layer의 Weight에서 단어 인덱스 배열 [0, 0, 0, 0, 1, 2, 3, 4, 4, 4]에 해당하는 행만 읽어오는 효과가 있다.
2. RNN(Recurrent Layer)
문장이나 영상, 음성등의 데이터는 한 장의 이미지 데이터와는 다른 순차적인(Sequential) 특성을 가진다. 데이터 사이에 연관성이 없다고 해서 순차적인 데이터가 아니라고 할 수 없으며 연관성이 없어보이는 데이터도 요소들 간의 연관성이 없지만 Sequence Data라고 하며 이러한 순차적인 데이터를 처리하기 위해 고안된 것이 Recurrent Neural Network(RNN or Recurrent Layer)이다.
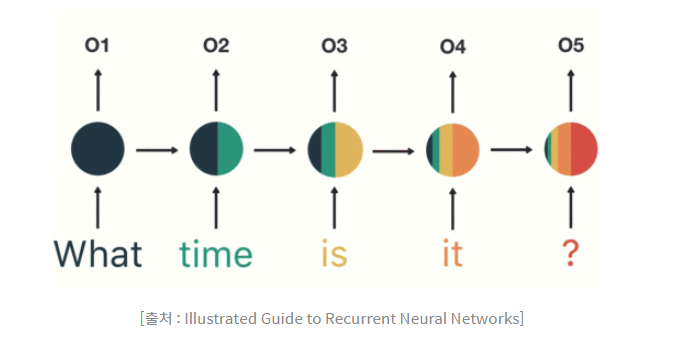
RNN의 입력으로 들어가는 모든 단어만큼 Weight를 만드는게 아니며 (입력 차원, 출력 차원)에 해당하는 단 하나의 Weight를 순차적으로 업데이트 하는 것이 RNN이다.
위의 그림에서 보이듯이 첫 입력인 "What"의 정보가 마지막 입력인 "?"에서는 거의 희석된 모습을 볼 수 있는데 이렇게 갈수록 옅어져 손실이 발생하면 이를 기울기 손실(Vanishing Gradient)문제라고 한다.
sentence = "What time is it ?" dic = { "is": 0, "it": 1, "What": 2, "time": 3, "?": 4 } print("RNN에 입력할 문장:", sentence) sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]]) print("Embedding을 위해 단어 매핑:", sentence_tensor.numpy()) print("입력 문장 데이터 형태:", sentence_tensor.shape) embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100) emb_out = embedding_layer(sentence_tensor) print("\nEmbedding 결과:", emb_out.shape) print("Embedding Layer의 Weight 형태:", embedding_layer.weights[0].shape) rnn_seq_layer = \ tf.keras.layers.SimpleRNN(units=64, return_sequences=True, use_bias=False) rnn_seq_out = rnn_seq_layer(emb_out) print("\nRNN 결과 (모든 Step Output):", rnn_seq_out.shape) print("RNN Layer의 Weight 형태:", rnn_seq_layer.weights[0].shape) rnn_fin_layer = tf.keras.layers.SimpleRNN(units=64, use_bias=False) rnn_fin_out = rnn_fin_layer(emb_out) print("\nRNN 결과 (최종 Step Output):", rnn_fin_out.shape) print("RNN Layer의 Weight 형태:", rnn_fin_layer.weights[0].shape)
📄Output

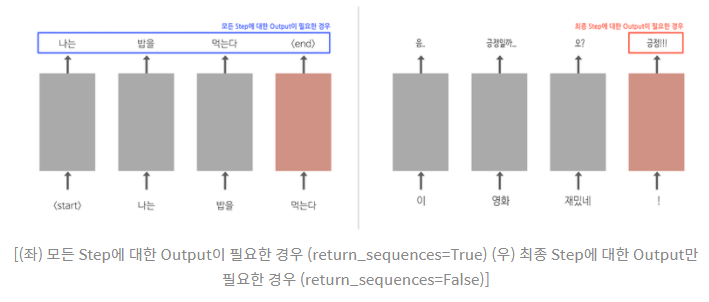
어떤 문장이 긍정인지 부정인ㅇ지 나누기 위해서라면 문장을 모두 읽은 후 최종 단계의 출력만 확인해도 판단이 가능하다. 하지만 문장을 생성하는 경우라면 이전 단어를 입력으로 받아 생성된 모든 다음 단어(단계)에 대한 출력이 필요하다. 그것은 위의 코드에서 tf.keras.layers.SimpleRNN Layer의 return_sequences 인자를 조절함으로써 조절할 수 있다.
💡Tip LSTM : 동작 방식은 RNN과 동일하다.
lstm_seq_layer = tf.keras.layers.LSTM(units=64, return_sequences=True, use_bias=False) lstm_seq_out = lstm_seq_layer(emb_out) print("\nLSTM 결과 (모든 Step Output):", lstm_seq_out.shape) print("LSTM Layer의 Weight 형태:", lstm_seq_layer.weights[0].shape) lstm_fin_layer = tf.keras.layers.LSTM(units=64, use_bias=False) lstm_fin_out = lstm_fin_layer(emb_out) print("\nLSTM 결과 (최종 Step Output):", lstm_fin_out.shape) print("LSTM Layer의 Weight 형태:", lstm_fin_layer.weights[0].shape)
📄Output

3. LSTM(Long Short-Term Memory)
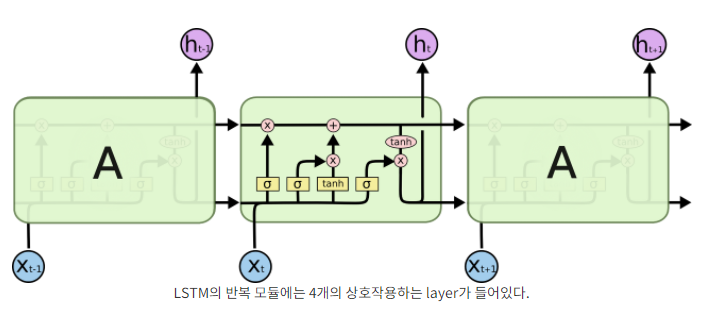
LSTM은 기울기 소실 문제를 해결하기 위해 고안된 RNN Layer이며 기본적으로 바닐라(Simple) RNN보다 4배나 큰 Weight를 가지고 있다.
4배 깊은 RNN이라기보다는 4종류의 서로 다른 RNN이라고 이해하면 좋다. 각 Weight들은 Gate라는 구조에 포함되어 어떤 정보를 기억하고 어떤 정보를 다음 단계로 전달할지 등을 결정한다.
LSTM에는 Cell State라는 새로운 개념이 추가되는데 긴 문장이 들어와도 이 Cell State를 통해 오래된 기억 또한 큰 손실 없이 저장해주고 Gate들이 Cell State에 정보를 추가하거나 빼주는 역할을 한다.
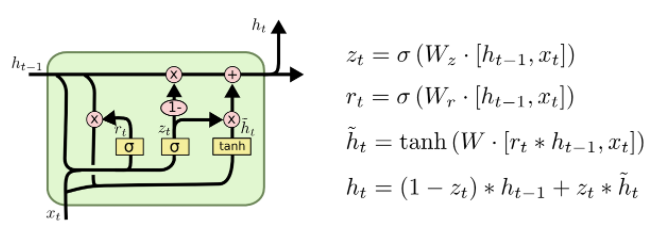
💡Tip LSTM 이해하기
4. 양방향(Bidirectional) RNN
양방향 RNN은 진행 방향에 변화를 준 RNN으로 "날이 너무 [ ]해서 에어컨을 켰다."라는 예문에서 빈칸에 들어갈 말이 "더워서"라고 예측할 수 있는데 이는 뒤에나오는 "에어컨은 켰다"라는 문장에서 유추할 수 있다. 하지만 기존의 순방향 RNN에서는 에어컨이라는 정보가 없는 채로 빈칸을 생성해야 하기 때문에 이상한 문장이 생성되기도 한다.
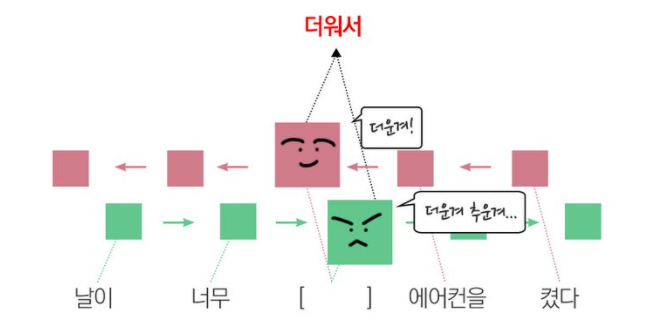
이를 해결하기 위해 제안된것이 양방향 RNN으로 진행방향이 반대인 RNN 2개를 겹쳐놓은 형태이고 Tensorflow에서도 LSTM등 모든 RNN 계열의 레이어에 tf.keras.layers.Bidirectional()로 감싸주기만 하면 적용 가능하다.
양방향 RNN Code
import tensorflow as tf sentence = "What time is it ?" dic = { "is": 0, "it": 1, "What": 2, "time": 3, "?": 4 } sentence_tensor = tf.constant([[dic[word] for word in sentence.split()]]) embedding_layer = tf.keras.layers.Embedding(input_dim=len(dic), output_dim=100) emb_out = embedding_layer(sentence_tensor) print("입력 문장 데이터 형태:", emb_out.shape) bi_rnn = \ tf.keras.layers.Bidirectional( tf.keras.layers.SimpleRNN(units=64, use_bias=False, return_sequences=True) ) bi_out = bi_rnn(emb_out) print("Bidirectional RNN 결과 (최종 Step Output):", bi_out.shape)
📄Output

Bidirectional RNN은 순방향 Weight와 역방향 Weight를 각각 정의하므로 우리가 앞에서 배운 RNN의 2배 크기 Weight가 정의됩니다. units를 64로 정의해 줬고, 입력은 Embedding을 포함하여 (1, 5, 100), 그리고 양방향에 대한 Weight를 거쳐 나올 테니 출력은 (1, 5, 128)
💡Tip 양방향 RNN이 필요한 상황이란?
문장 분석이나 생성보다는 주로 기계번역 같은 테스크에 유리하다. 사람도 대화를 하면서 듣고 이해하는 것은 순차적으로 들으면서 충분히 예측을 동원해서 잘 해낸다. 그러나 문장을 번역하려면 일단은 번역해야 할 문장 전체를 끝까지 분석한 후 번역을 시도하는 것이 훨씬 유리하다. 그래서 자연어처리를 계속하면서 알게 되겠지만, 번역기를 만들 때 양방향 RNN 계열의 네트워크 혹은 동일한 효과를 내넌 Transformer 네트워크를 주로 사용하게 된다.
