[AI DEEP DIVE] 딥러닝, 그것이 알고 싶다.
본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
강의 링크 : https://bit.ly/3GV73FN
MLP (Multi-layer Perceptron)
MLP는 Input layer와 Output layer사이에 Hidden layer가 1개 이상 존재하고 모두 FC(Fully-connected)이다.
용어에서 P가 perceptron인데 이는 activation function이 step function이 고정인데 MLP에서는 Activation function을 다양한 비선형함수로 사용하는 것으로 생각하면 된다.
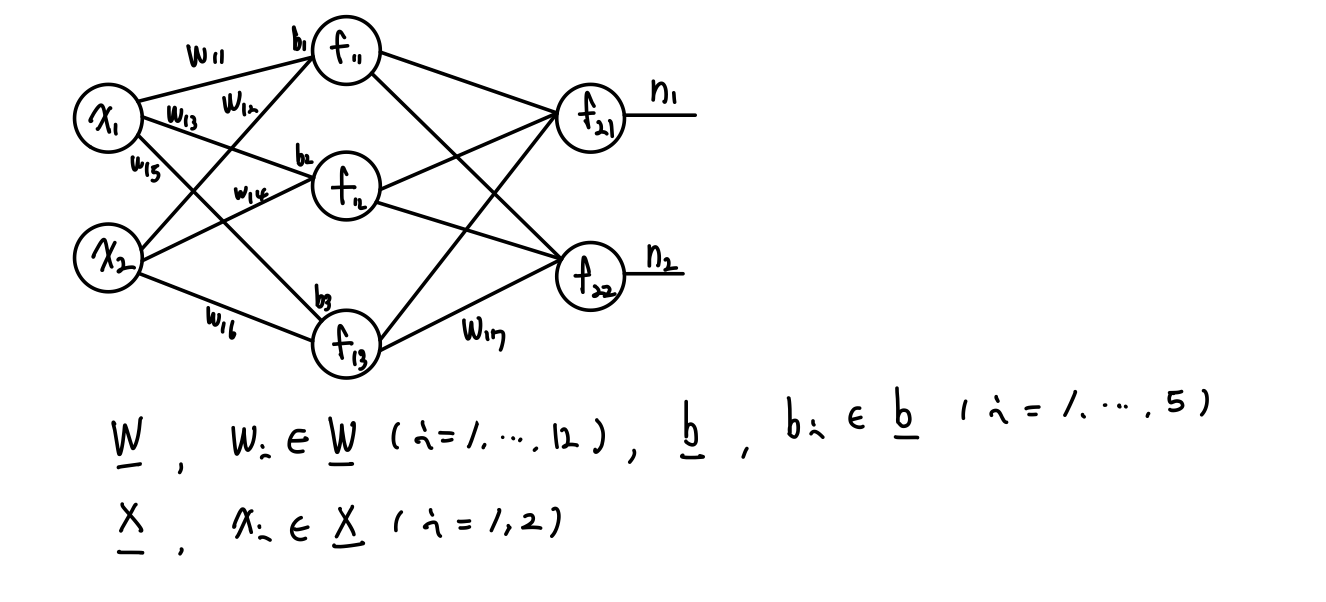
MLP Matrix와 Vector로 표현
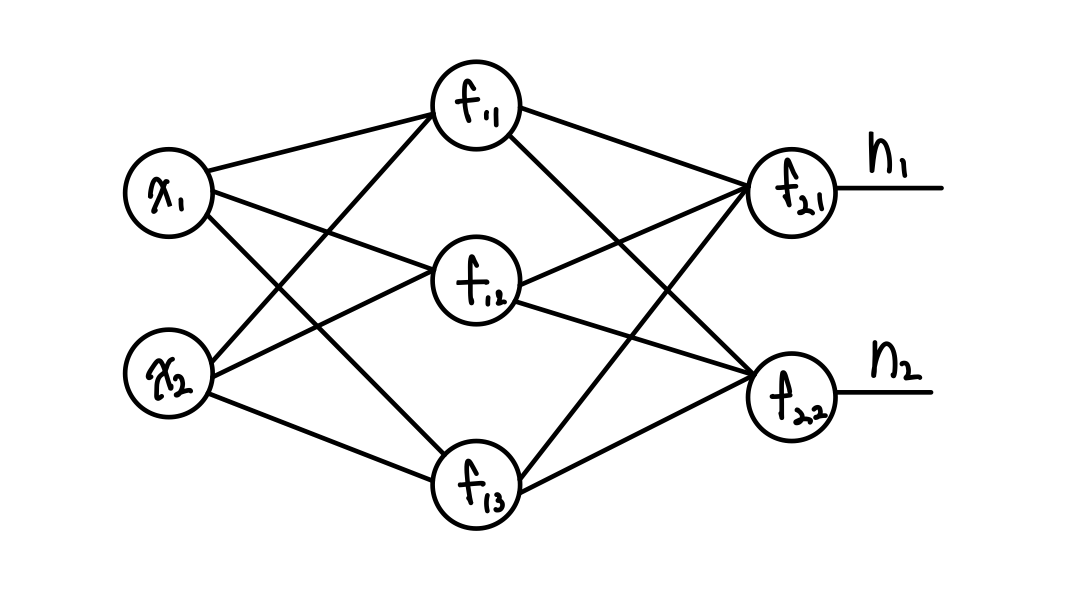
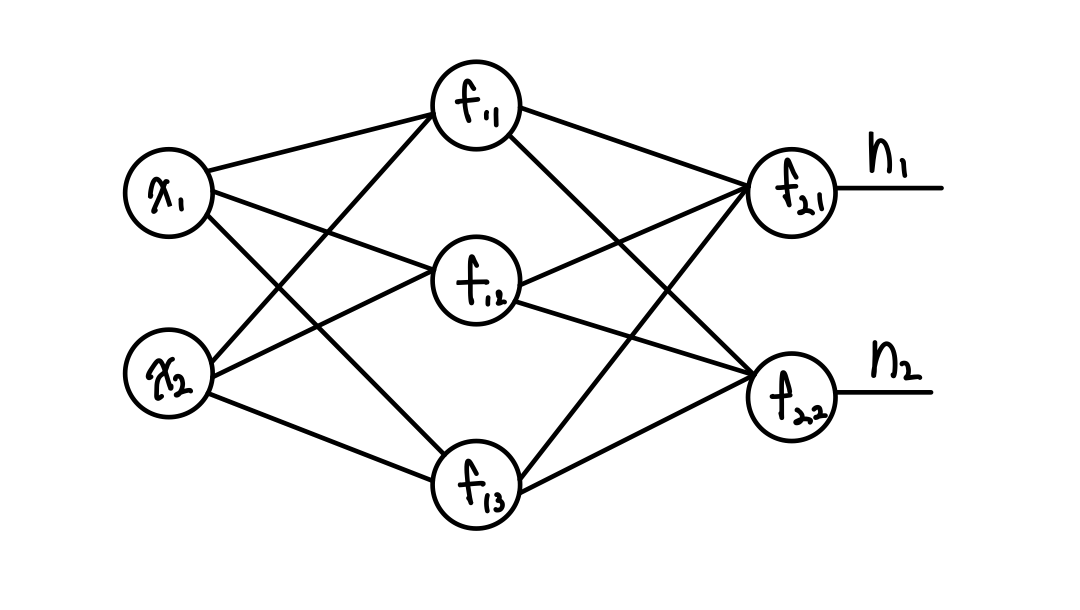
Hidden layer가 1개인 MLP
총 12개의 weight와 5개의 bias 그리고 2개의 Input 값이 있는 그림이다.
( 만약, 개수를 구하는 방법이 바로 떠오르지 않는다면 앞에 포스팅을 참고하기 바란다! )
이제 이를 을 통과하는 3개의 출력을 식으로 표현하면 아래의 그림처럼 표현된다!
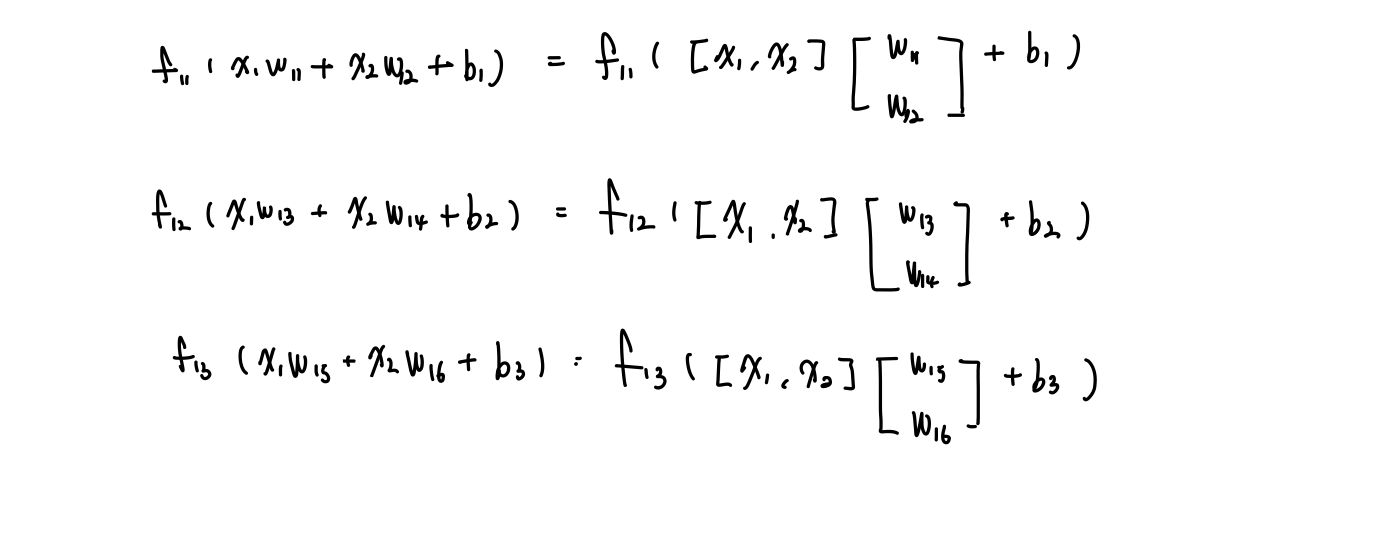
하지만, Naive하게 아래처럼 표현하지 않고 아래의 그림과 같이 Matrix와 Vector를 사용해 layer 1개를 간단하게 표현해보자.
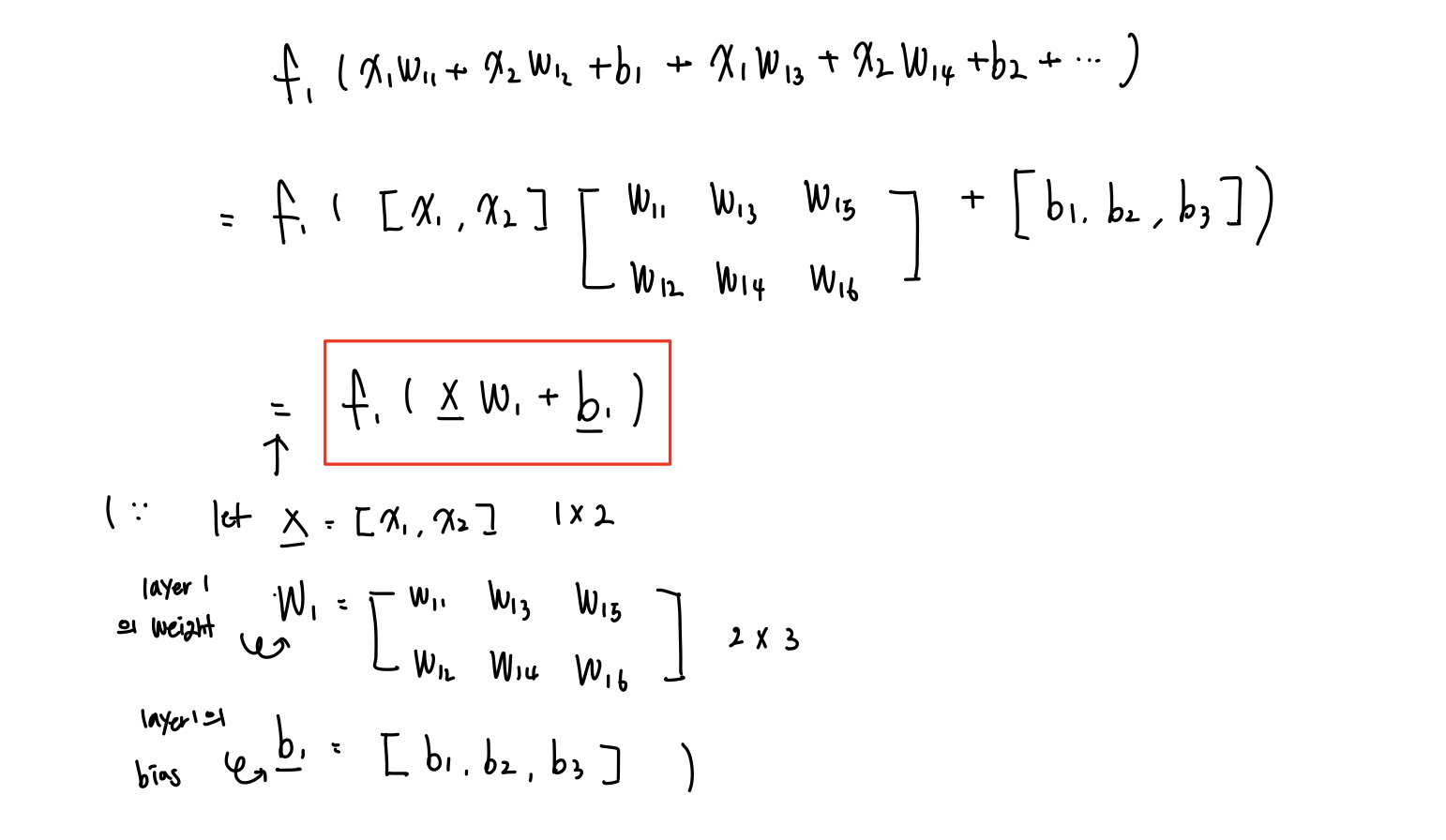
이를 확장시켜 MLP 전체를 Matrix와 Vector로 표현하면 아래와 같이 표현된다.
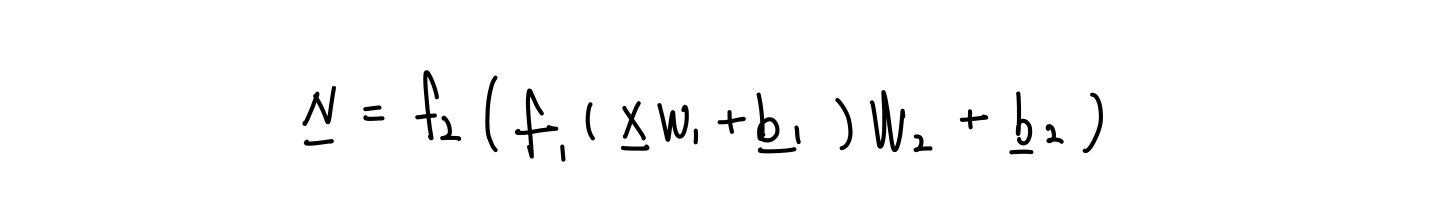
이제, Hidden이 100개가 있어도 위와같이 표현을 할 수 있게 되었다. 한 줄로 말하자면 MLP는 " 'Matrix'곱하고 'Vector'더하고 'Activation' "의 반복이다.
MLP에서 Activation Function으로 선형함수를 쓰지 않는 이유
Let, = x, = x인 선형함수라 하자. 그러면, 아래와 같이 식이 풀어진다.
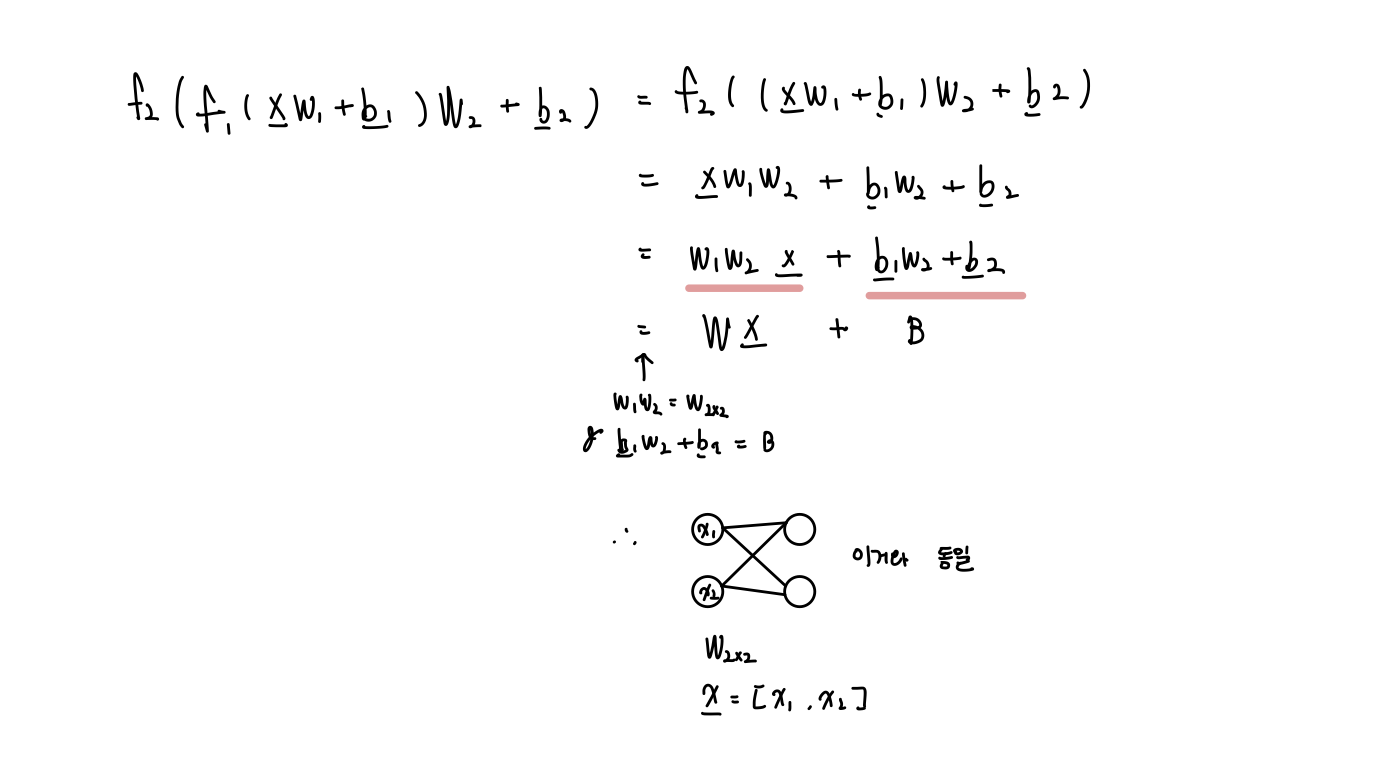
이러면, 은닉층이 사라져버리는 효과가 발생한다. 따라서, Hidden layer를 100개 1000개 10000개 쌓아도 다 사라져버려 의미가 없어진다.
Ex) 그렇다면, 선형과 비선형을 번갈아 쓰면 어떻게 될까?
역시 Activation이 선형인 것은 위와 같이 의미가 없어져버려 도움이 되지않는다.
#패스트캠퍼스혁펜하임 #혁펜하임 #혁펜하임AI #패스트캠퍼스 #혁펜하임강의 #AIDEEPDIVE #ai강의 #혁펜하임강의후기
