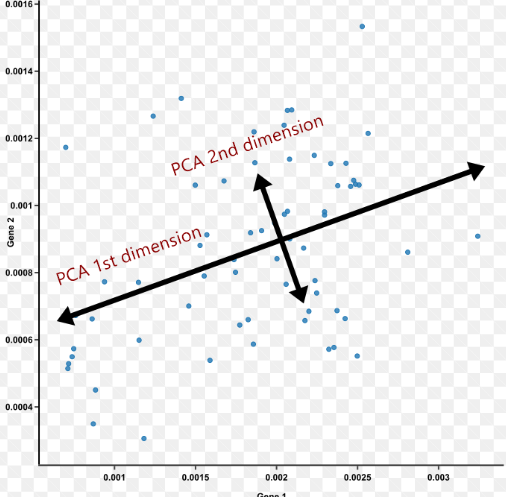
PCA
다차원 데이터의 분포를 최대한 유지하며 저차원의 데이터로 표현하는 것이다. 이때, 첫번째 축을 잡을 때 데이터를 정사영했을때 분산이 가장 큰 축으로 잡아야한다.
Covariance Matrix의 Eigenvalue가 최대 variance인 이유
최대 Variance가 데이터의 분포를 가장 잘 표현하는 이유
아래의 그림에서 파란색 표시는 i번째 Sample을 벡터 u에 정사영 시켰을 때 오차를 말한다. 모든 sample이 벡터 u에 정사영했을때 error를 최소가 되는 벡터 u를 찾는 것이 목적이다.
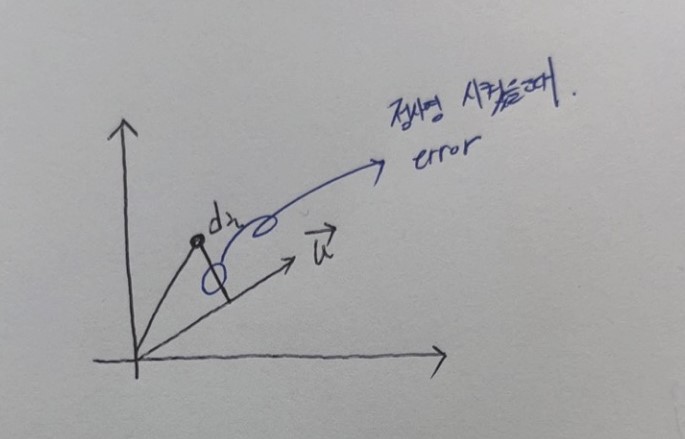
Let, u는 unit vector이다. 따라서, u의크기=sqrt(uTu)=uTu=1
원점으로 데이터 sample을 이동시켜주는 작업을 한다.
Suppose that dμ = sample들의 평균, di− = 실제 값, di = di− - dμ = 평균을 0으로 이동한 값
Min n1 ∑i=1n(di−(diTu)u)T(di−(diTu)u) 되는 u를 찾는 것이 목적이다.
전개하면 n1 ∑i=1ndiTdi−diT(diTu)u−(diTu)uTdi+(diTu)uT(diTu)u
이때, (diTu)uT(diTu)u = (diTu)(diTu)uTu = (diTu)(diTu) = (diTu)2 이다.
( 왜냐하면, 가정에 의해 uTu=1 이다. )
그리고, diT(diTu)u = (diTu)diTu ( d_i^Tu는 scalar이다.) = (diTu)2 따라서, 위에 두개는 제거된다.
그리고, 우리가 찾고싶은 것은 u의 최적화이기 때문에 식에 필요없는 diTdi 제거하고 생각해도 최적화된 u는 동일하다.
제거를 하고 난 뒤 남는 것은 min n1 ∑i=1n−(diTu)uTdi 이다. 그리고, (diTu),uTdi는 scalar라서 자리를 바꿔도 동일하다.
min n1 ∑i=1n−uTdidiTu = min n1 ∑i=1n−uT(di− - dμ)(di− - dμ)Tu
이때, n1∑i=1n(di− - dμ)(di− - dμ)T를 자세히 보면 이는 Covariance matrix가 된다.(원래는 n−11∑i=1n(di− - dμ)(di− - dμ)T인데 최적화 문제에서는 1/n이나 1/(n-1)나 최적의 벡터 u는 동일하다.)
즉, 분산이 등장했다. 지금까지 처음 error(거리)에서 분산까지 차근차근 도출해왔다.
이제, n1∑i=1n(di− - dμ)(di− - dμ)T = Rd = 공분산 행렬
Min −uTRdu = -Min uTRdu = Max uTRdu s.t. uTu=1
여기서, 등장하는 것이 최적해를 찾는 라그랑주 승수법이다. (라그랑주 승수법은 따로 포스팅 할 예정이다.)
L(u,λ) = uTRdu + λ(1-u^Tu) ( δuδL=0이 되어야 Max하는 벡터 u이다. )
dLu = duTRdu + uTRddu - λduTu - λuTdu
이때, (λduTu)T = λuTdu, (duTRdu)T = uTRddu이다. 왜냐하면, scalar라서 transpose를 해도 동일하다.
따라서, dLu = 2 uTRddu - 2 λuTdu = (2uTRd - 2 λuT) du
(2uTRd - 2 λuT) = δuδL 이므로 (이 역시 따로 라그랑주 승수법과 같이 포스팅 하겠다. )
(2uTRd - 2 λuT) = 0이고 정리하면 uTRd = λuT transpose를 취해주면 Rdu = λu가 되고 이는 우리가 많이 보았던 Eigendecomposition이 된다. 즉, 공분산 행렬의 고유값분해인 것이다. (Rd는 Symmetic Matrix라서 Eigendecomposition이 가능하다. )
그러면, Rdu = (λ1 q1 q1T + λ2 q2 q2T + ... + λn qn qnT)이된다. ( λi는 i번째 eigenvalue이고 qi는 i번째 eigenvector이다. )
이제 식을 다시 쓰면 Max uT Rd u = Max uT (λ1 q1 q1T + λ2 q2 q2T + ... + λn) u 이 되고 이 값이 최대가 되는 값은 λ1이 다른 λi보다 다 크니깐 u vector는 q1이 되어야한다. (즉, 이것이 variance가 가장 큰 축을 잡는 것이다.) 그리고 다음은 자동적으로 q2이다.
이때, q1과q2는 서로 수직이다. 이것이 최적의 초평면을 잡고나서 다음 축을 잡을때 수직이 되는 축을 찾는 이유이다.
따라서, 분산이 최대가 되는 것이 왜 데이터의 분포를 잘 보존하는지 알아보았고 첫번째 축을 잡은 후 두번째 축이 왜 수직이 되어야하는지까지 알아보았다.
Pros
- 적은 데이터로 원본을 표현할 수 있다.
- 저차원으로 차원변경 후 시각화
Cons
- 항상 좋은 성능을 기대할 수 없다.
- 데이터의 손실이 발생한다.