Random Forest는 여러 개의 Decision Tree를 Ensemble한 것이다.
그러면 앙상블에 대해 알아보자!
Ensemble
앙상블이란?
한 개의 모델이 단독적으로 예측값을 내는 것이 아니라 서로 다른 방식으로 훈련된 여러 개의 Model이 종합적으로 예측값을 내는 것이다.
아래의 그림을 살펴보자. 총 4개의 Model이 있다. 이 중 3개의 Model은 1을 예측하였고 1개만 2을 예측하였다.
그러면 앙상블 모델은 다수결에 따라 1번으로 분류를 한다.
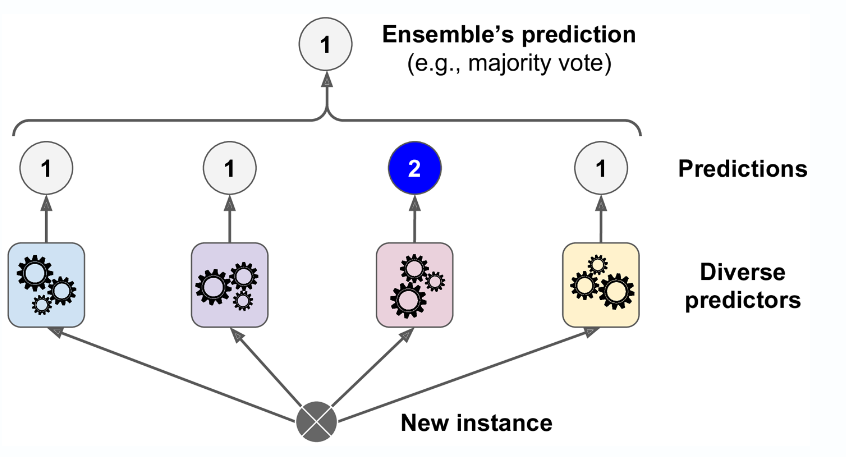
근데 위와같은 방식은 승자만 고려한다. (직접투표 방식)
이 방식이 문제가 될 수 있는 예시로 class 1인 비율이 0.6이고 class 2인 비율이 0.4라 하자. 그러면 class 2인 것도 확률이 낮지않기때문에 고려를 안한다면 옳지않은 분류기가 탄생할 수 도 있다.
따라서, 승자독식으로 분류를 하는 것이 아니라 간접투표방식을 도입해 다른 class의 확률도 같이 고려해서 값을 산출한다.
이때, 간접투표는 값을 산출할때, 해당 class의 값을 모두 더해 평균을 취한 후 가장 높은 것으로 예측하는 것이다. (간접투표 방식)
앙상블 방법의 큰 틀을 보았는데 그러면 좀 더 자세히 현재 인기있는 앙상블 방법 3가지 배깅, 부스팅, 스태킹에 대해 살펴보겠습니다.
배깅(Bootstrap Aggreagting)
Bootstrap: 통계학에서 사용되는 용어로 random sampling을 적용하는 방법이다. Ex) 전체 10000개 중에 임의로 (Random)100개를 뽑아 사용하는 것
Aggreagting: 위에서 Random하게 뽑은 데이터를 집계한다.
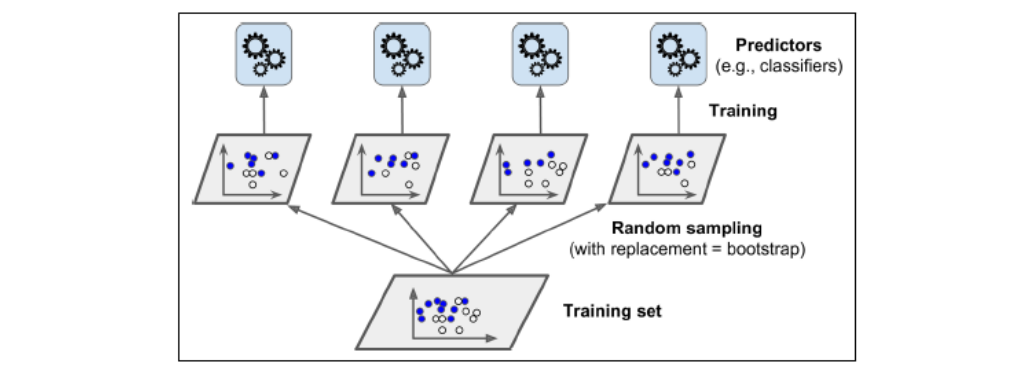
위의 투표기반의 예시는 Model 자체를 여러 개 사용했다. 하지만, 배깅 앙상블은 Model은 한 가지의 Algorithm을 사용하는데 훈련데이터를 다르게 해서 다른 Model이 되게 하는 방식이다. (이 방식이 바로 Random Forest방식이다. Algorithm은 동일한데 여러 개의 모델을 만들려면 데이터를 Random하게 주면서 Model을 만드는 것이다.)
아래의 사진을 보면 먼저, Training Set에서 무작위로 데이터들을 분류기 수만큼 Random하게 나눈다. (이때, 데이터들은 중복으로 뽑히는 것이 가능하다. 만약, 중복이 불가능하다고 설정하면 그것이 페이스팅이 된다.)
이후, 해당 sampling된 데이터를 이용해 모델을 학습 시켜 4개의 다른 Model을 만든다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)Accuracy : 0.904
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(accuracy_score(y_test, y_pred_tree))Accuracy : 0.856
성능차이가 크게 나는 것을 확인 할 수 있다. 그림으로 살펴보면 왜 그런 것인지 더 잘 확인 할 수 있다.
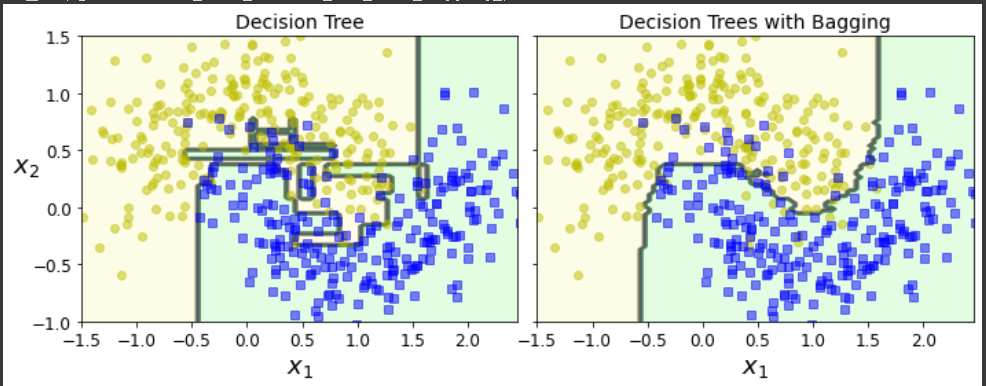
이전 포스팅에서 Decision Tree의 문제점인 결정경계가 수직적이라 데이터에 과대적합이 되는 경우가 많다. 배깅을 사용하면 결정경계가 수직이 아니라서 유하게 잘 분류하는 것을 확인할 수 있습니다. 즉, 데이터에 과대편향이 줄어들었다.
- 배깅의 하이퍼 파라미터
- n_estimator: 분류기를 몇 개 할지 (즉, Model을 몇개 만들지)
- max_sample: 샘플링을 진행할 때 몇개를 뽑을지
- bootstrap: 배깅으로 할지 페이스팅으로 할지
- n_jobs: 코어수를 몇개로 해서 돌릴지
- oob_score: 안쓴 데이터가 몇 프로인지 알려줄지 말지
(oob = out of bag)
Random Forest
Random Forest는 배깅을 사용한 방식이다. 이때, 배깅방식 중 특성을 샘플링하는 방식으로 동작하는데 이 Algorithm은 모든 특성을 고려한 것이 아니라 랜덤하게 선택된 특성들 중 가운데 최적의 특성을 찾는 식이다. 즉, 무작위성을 추가한 것이라 볼 수 있다.
# Random forest 모듈을 이용
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=42)# BaggingClassifier이용한 Random forest
bag_clf = BaggingClassifier(
DecisionTreeClassifier(max_features="sqrt", max_leaf_nodes=16),
n_estimators=500, random_state=42)랜덤 패치와 랜덤 스페이스
랜덤 패치: 특성과 데이터를 동시에 샘플링하는 것
랜덤 스페이스: 샘플을 고려하지않고 특성만 고려해 샘플링 하는 것

부스팅
2가지 부스팅 Algorithm을 소개하겠다.
Adaboosting
여러 개의 Weak Model을 모두 더해 결과로 Strong Model을 만든다. 동작방식으로는 데이터를 샘플링을 할 때 전 모델의 오분류된 sample을 파악하고 그것의 가중치를 높여 훈련시키는 방법이다. (보통, adaboost의 Weak Model은 stump(노드 하나와 leaf node 2개로 이루어진 것)을 말한다.)
위의 배깅 방식과 차이점은 샘플링을 할 때 Random하게 뽑았고 훈련 자체도 병렬적으로 이루어졌다.
하지만, Adaboost은 전 Model의 오분류 sㅉample을 파악한 후 가중치를 높여 다음 샘플링에 잘 뽑히게 한 후 다음 Model의 훈련을 진행한다.
Adaboosting의 Algorithm
Suppose) 이진분류라고 가정하고 class는 -1, 1이다. T는 ensemble할 Model 수이다.
class는 0,1이라고 해도 상관없지만 알고리즘 구조상 -1,1이 알맞아서 set했다.
는 첫번째 데이터셋의 i 데이터 분포이다.
는 t번째 데이터셋을 이용한 Model이다.

즉, 우리는 오분류된 데이터가 다음 데이터셋으로 뽑힐때 가중치가 어떻게 달라지는지 확인하고 싶다.
먼저, initial 데이터셋의 데이터 가중치들은 1/N로 나눠준다. (uniform distribution)
그리고 여기서,가 등장하는데 이는 예측값과 실제값이 다른 sample들의 확률이다. (즉, 낮으면 좋은 Model이다.)
이제 if문이 등장하는데 이는 Model이 weak model에 속하는지 안속하는지 판단하는 것이다. 모델이 우리가 찍는 것보다 예측을 잘하지못한다면 쓸 이유가 없다.
이제는 weak model인지 파악이 되었고 데이터의 가중치를 바꿔보자.
는 t번째 데이터셋에서 모델이 얼마나 좋은지를 나타낸다. == 1이면 값이 0이 된다. (즉, 쓸모가 없어진 모델이다.) == 0 값이 매우 커져 해당 Model이 정확하다 할 수 있다.
= ( exp (- h()) ) /
이때, 아래의 두 가지를 이해하면 다 이해한 것이다.
-
-
값이 높으면 좋은 Model이라고 했다. -
h())
만약, 예측과 실제label이 동일하면(즉, == h()) 1이 나온다. (이때문에 class 분류를 -1과 1로 했다.)
만약, 예측과 실제label이 다르면 -1이 나온다.
(- h())의 값은 좋은 모델이고 예측과 실제값이 동일하다면 해당 i번째 데이터는 다음 데이터셋 t+1에 들어갈 확률이 줄어든다.
하지만, 좋은 모델에서 예측과 실제값이 다르다면 해당 i번째 데이터는 다음 데이터셋 t+1에 들어갈 확률이 커진다.
즉, 아래의 사진을 참고하여 이해해보자.

결론적으로 이전 모델이 잘 분류하지 못한 데이터셋을 더 많이 넣으면서 학습을 보완하는 것이라 생각하면 된다.
ex) T가 3이다.
Step1)
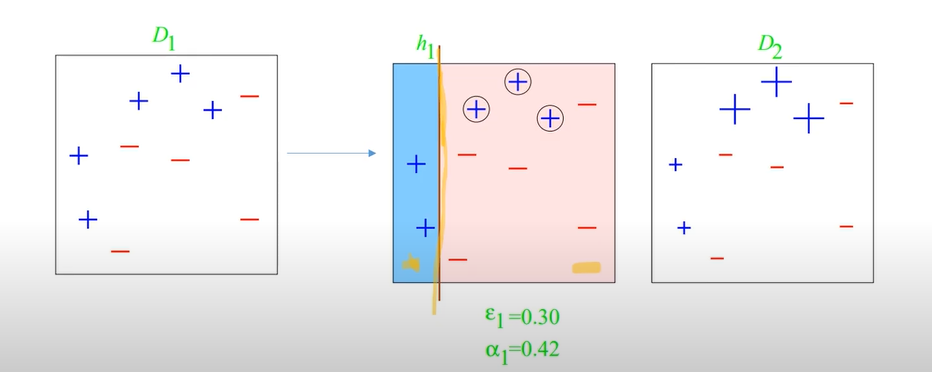
여기서는 와 값을 구할 수 있다.
= 3/10
= 1/2 ln(7/3) 약, 0.42라하자.
Step2)
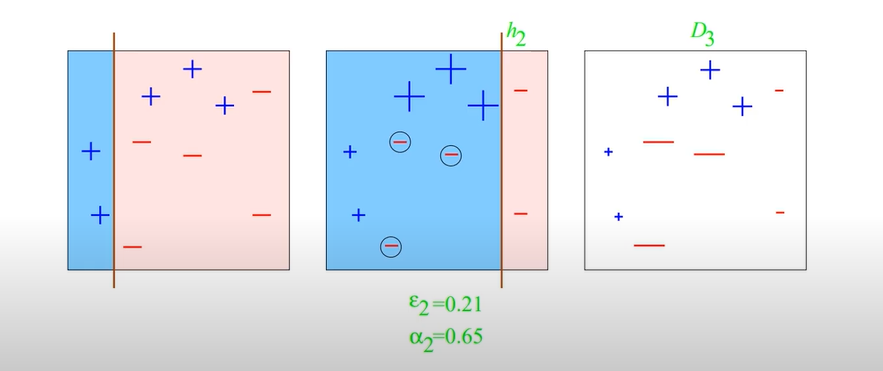
여기서부터는 데이터들이 가중치가 들어갔기 때문에 정확하게 와 값을 구할 수 없다.
Step3)
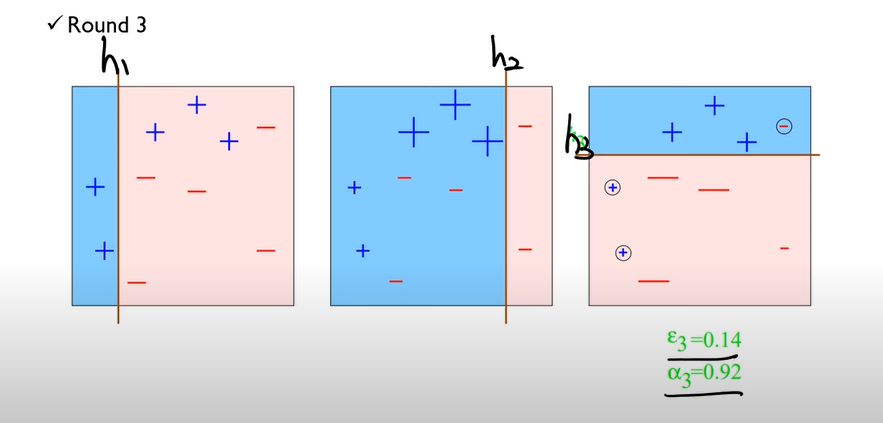
Final)
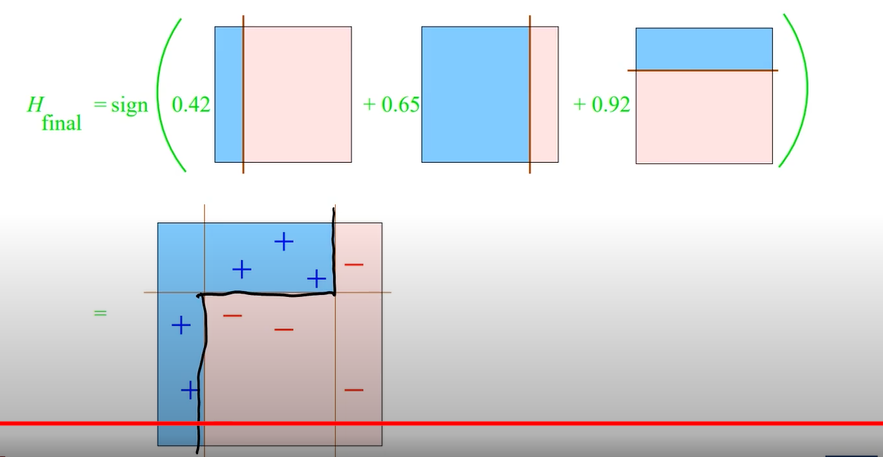
Gradient boosting
adaboosting은 다음 모델을 학습할 때 각 샘플의 가중치를 다르게 설정해 학습을 시켰다면 Gradient boosting은 다음 학습을 할 때 잔차(residual error)를 사용해 학습을 진행한다.
코드와 함께 Gradient boosting을 설명하겠습니다.
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)초기 훈련을 진행한다.
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)두번째 model 훈련은 실제값 - 첫번째 모델의 예측값을 기준으로 훈련한다.
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)세번째 model 훈련은 실제값 - 첫번째 모델의 예측값 - 두 번째 모델의 예측값을 기준으로 훈련한다.
이렇게 y값을 바꿔가면서 예측하고 마지막에 아래와 같이 다 더해준다.
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))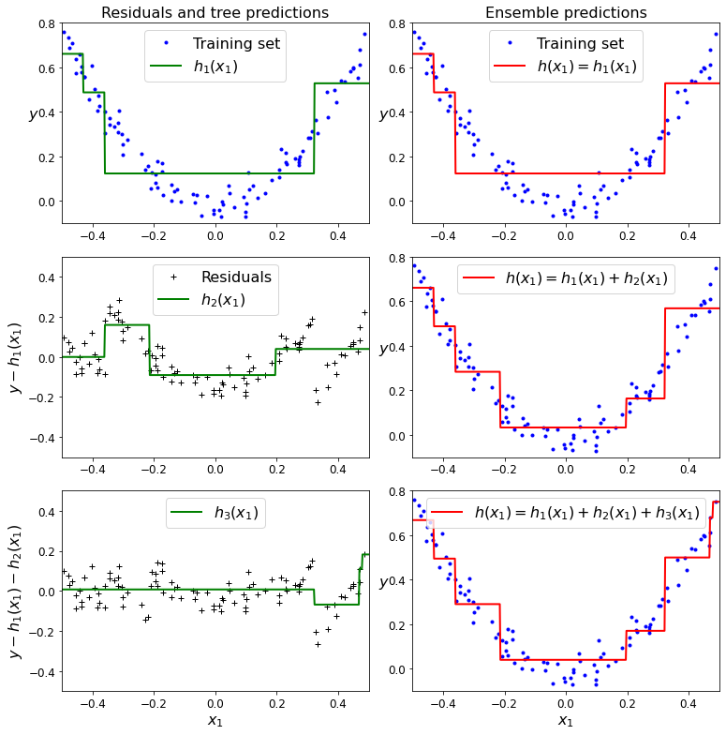
이렇게 이전에 잔차값을 가지고 훈련하는데 좋은 성능을 가지는 것은 무엇때문일까?
바로 이름에도 나와있듯이 gradient descent 때문이다.
Loss function이 아래와 같이 정의되어있다하자.
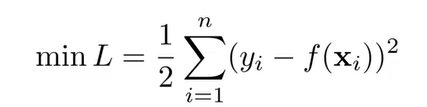
이를 f()에 대해 편미분을 취하자.
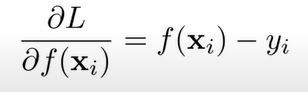
이후, 양변에 -를 곱해주면 잔차가 제일 Loss funtion이 최소로 가는 방향이다. 이에 대해 Model을 학습시킨다는 것을 Loss가 작아지는(즉, 잔차가 작아지는)학습을 한다는 것과 동일한 훈련이 된다.
이때, 주의할 점은 잔차를 그대로 다 더해주면 데이터에 대해 오버피팅이 난다. 따라서, 학습률을 곱해서 줄어드는 방향은 같지만 크기를 다르게 해서 천천히 학습을 시킨다. 그러면 전체 훈련과정은 늘어날지 몰라도 일반화 성능은 더 좋아진다.
