Classifier Guidance 논문리뷰: https://velog.io/@guts4/Diffusion-Models-Beat-GANs-on-Image-Synthesis-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Classifier Guidance vs Classifier-Free Guidance
이름만으로 왜 해당 논문이 나온지 알 수 있습니다. 이전에 나온 Classifier Guidance에서는 U-Net모델의 8x8 layer의 output을 이용해서 classifier를 학습했습니다. 하지만 해당 논문에서는 이러한 classifier 없이 class label(y)을 추가할 수 있는 방법을 고안해냈습니다.
Classifier를 왜 제거해야된다고 할까요?
- 추가적인 학습
노이즈 데이터를 기반으로 학습해야 하기때문에 사전학습된 Classifier를 가져오지 못하고 처음부터 모두 학습을 진행해야합니다.
- GAN의 단점
GAN에서는 Discriminator를 속이기만 하면되기 때문에, 다양한 이미지가 생성되지 않거나 우리 눈에는 해당 class가 아닌데 그저 classifier를 속이기 위한 이미지만 생성하는 문제가 있었습니다. 현재 Classifier guidance도 classifier 즉 판별자를 사용하기때문에 동일한 문제가 발생할 수 있습니다.
- 평가지표의 문제
평가지표인 FID와 IS는 모두 Inception Network즉 classifier를 기반으로 결과를 내는데, 모델 자체가 classifier에 특화되게 학습하므로 성능이 좋아서 결과가 좋은지, classifier에 특화되서 성능이 좋은지 정확히 알 수 없습니다.
간단한 Background
- Score function이 데이터의 log likelihood를 최대화하는 방향으로 작동하며, 노이즈를 제거하고 데이터를 복원하는 방식으로 작동하는 것
- Diffusion 모델을 Continous하게 적용해서 λ 값은 연속적인 time step 중 한 순간. λ값이 time step이면서 동시에 데이터와 노이즈의 비율을 조절하는 SNR(signal-to-noise ratio)를 나타냄.
GUIDANCE
BigGAN에서 사용하는 Truncation과 Glow에서 사용한 Low temperature 방식은 diversity를 줄이지만 품질을 높인다는 기술입니다. Truncation trick에 대해서만 간단히 설명해드리자면, 가우시안 분포에서 샘플링을 할 때 평균에서 크게 벗어나지 않도록 제한된 범위 안에서만 함으로써 더 높은 품질의 이미지를 생성하도록 합니다.
하지만 위와 같은 기술들을 diffusion 모델에 적용한 결과는 효과적이지 않았습니다. Model score를 scaling한다거나 아니면 reverse process과정에서 분산을 줄이는 과정들은 모두 결과가 blurry해지거나, 더 낮은 품질을 제공하게 됩니다.
CLASSIFIER GUIDANCE
Diffusion 모델에서 truncation trick과 같은 효과를 얻기 위해서 처음 제시된 논문이 classifier guidance(위의 논문 요약 참조)입니다.
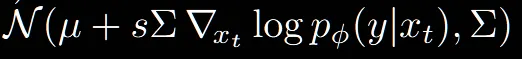
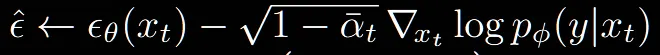
위의 2개의 식은 이전 Classifier Guidance에서 정의한 방법입니다. 단순히 평균이나 노이즈를 예측할 때 classifier의 gradient의 값도 더해주거나 빼주는 것을 확인할 수 있습니다.
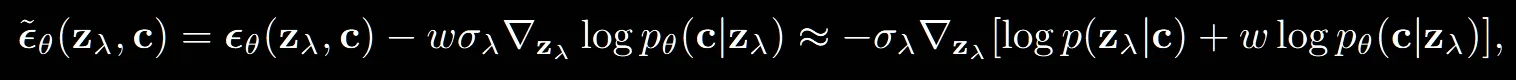
Classifier-Free guidance에서는 해당 부분에 약간의 수정을 가했습니다. 이전에 부분을 으로 condition정보가 들어가게 수정한 것입니다. 이전 수식들에서는 scaling값 s가 0이면 unconditional 모델이 되었지만, 수정한 식에서는 w가 0이어도 conditional 모델이됩니다.
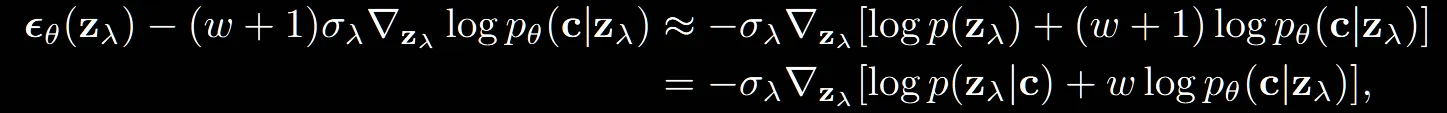
이러한 변환은 unconditional model에 w대신 w+1을 할경우 동일한 결과가 나온다고 합니다. 즉 기존 논문에서 w를 w+1로 변경할경우 변경한 수식이 나옵니다.
그렇지만 w+1이아닌, conditional 모델에 classifier guidance를 추가한 것처럼 변경한 이유는 conditional 모델에 classifier guidance를 추가한 경우가 unconditional 모델에 추가한 경우보다 성능이 더 좋았기 때문입니다. 이에 대한 근거로 conditional 모델은 이미 condition을 받을 준비가 되어있는 모델로 설계되었다고 말했습니다.

위의 그림은 의 수식을 수학적으로 푸는 과정을 보여줍니다.
3가지 class에 대해서 맨왼쪽은 guide가 없는 그림이고 오른쪽으로 갈수록 guidance strength를 증가한 그림입니다. guidance의 값이 증가할수록 각 class의 데이터 분포들은 서로 떨어지게 되고 더 작은 영역을 갖게됩니다. 이그림이 guidance 값이 증가할 경우 IS값은 증가하고, diversity가 떨어지는 이유에 대해서 적절하게 설명해준다고 합니다.
CLASSIFIER-FREE GUIDANCE
위에서 classifier guidance를 conditional model에 적용하도록 수정했지만, 아직 논문에서 언급한 classifier가 없어진 형태는 아닙니다. 해당 부분에서 어떻게 classifier 없이 학습이 가능한지 설명해드리도록 하겠습니다.
우선 핵심 내용은 기존 classifier guidnace에서는 diffusion model에 classifier guidance를 추가한 형태입니다. 하지만 classifier-free guidance는 conditional + unconditional 모델을 합친 형태로 변경했습니다.
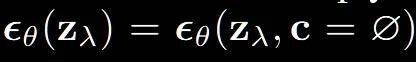
Unconditional 모델은 conditional 모델의 condition 값은 NULL 값 처리한 모델로 학습하게 됩니다.
또한 2개의 모델을 각각 훈련해도 되고, 한번에 훈련해도 되지만 논문에서는 단일 모델이 2가지 모델을 동시에 훈련하기때문에 파라미터가 증가하지 않아서 한번에 훈련하도록 설계했다고 했습니다.
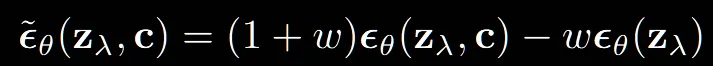
왼쪽 부분이 conditional 부분이고 오른쪽 부분이 unconditional 부분으로 설계된 것입니다. 수식을 보면 알 수 있듯이 gradient와 관련된 classifier 부분이 없어진 것을 알 수 있습니다.
참고: https://www.youtube.com/watch?v=XDMnHMeX-kQ
아래에 설명하는 수식은 위의 유튜브 영상을 참조해서 만들었으며, 해당 과정의 Classifier-Free Guidance의 수식설명이 매우 잘되어있어서 참고하면 좋을거같습니다.
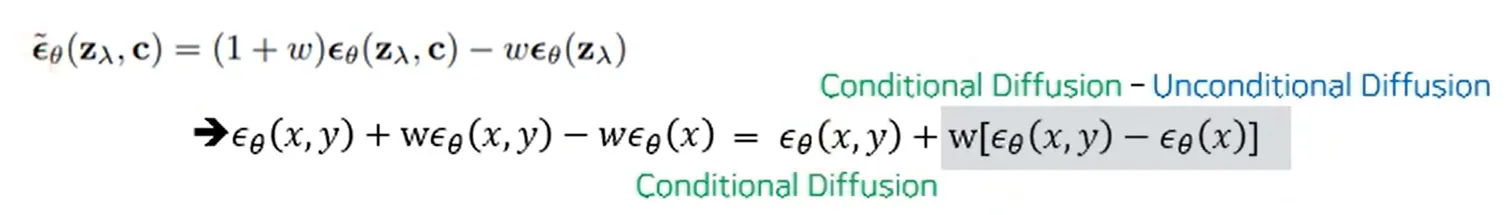
방금 설명한 수식에 대해서 w에 관한 수식으로 묶으면 명백하게 Conditional 부분과 Unconditional 부분에 대해서 알 수 있습니다.
위의 수식 전개과정은 Classifier Guidance를 베이즈 룰로인해서 정리한 수식입니다. 3번째 수식이 y에 대한 수식은 상수이기때문에 생략하면 나머지 전개과정은 쉽게 따라오실 수 있을 것입니다.
결론적으로 마지막 부분과 위 사진에서 회색부분의 결과가 동일합니다. 논문에서는 베이즈 정리를 통해 생성 모델을 역으로 사용해 분류기를 만든 경우 분류기의 품질이 항상 유용하지 않았다는 이전의 사례를 통해 문제점을 제시했습니다. 하지만 실험적으로 괜찮다는 것을 보여주며 유용한 식이기때문에 사용해도 괜찮다고 결론지었습니다.

훈련하는 과정은 간단합니다. 우선 값을 통해서 condition 값을 NULL로 할 건지 정합니다. NULL로 지정할 경우 이전에 설명한것처럼 unconditional 모델을 학습하는 것이 됩니다.

Sampling 과정에서는 guidance strength(w), condition(c), 그리고 time step(t)값이 들어가게 될 것입니다. 논문에서는 안나왔지만 condition에 NULL 값을 넣으면 그냥 unconditional 모델처럼 작동할 것으로 예상됩니다.
EXPERIMENTS
이전 Classifier Guidance 논문에서는 Classifier로 인해 평가지표에 특화되게 학습할 수 있고, 이로 인해서 정확하지 않은 결과가 나왔습니다. 예시로 BigGAN에서 제시한 IS-FID의 trade off 현상이 나타나지 않았습니다. 하지만 Classifier-Free Guidance는 이 trade off를 나타낼 수 있다고합니다.

왼쪽사진이 non-guided 오른쪽 사진이 classifier-free guided의 결과입니다. classifier-free guidance를 적용할 때 w의 값을 3으로 설정했고 오른쪽 사진이 왼쪽 사진에 비해서 해당 class를 더 잘 나타내고, 색깔이 진하게 나타냅니다.
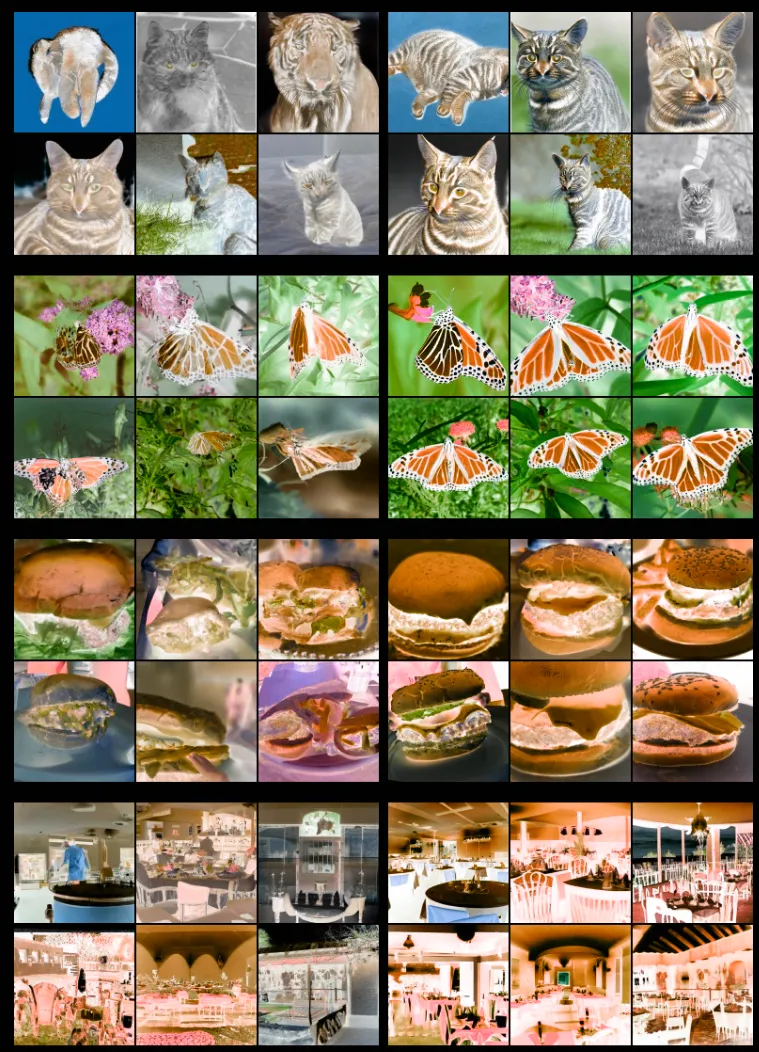
추가설명으로 동일하게 왼쪽이 non-guided 오른쪽이 classifier-free guided 결과인데, class를 잘 나태는건 알겠지만 색상이 더 찐해지는건 나비를 제외하고는 명확하게 느껴지지는 않았습니다.
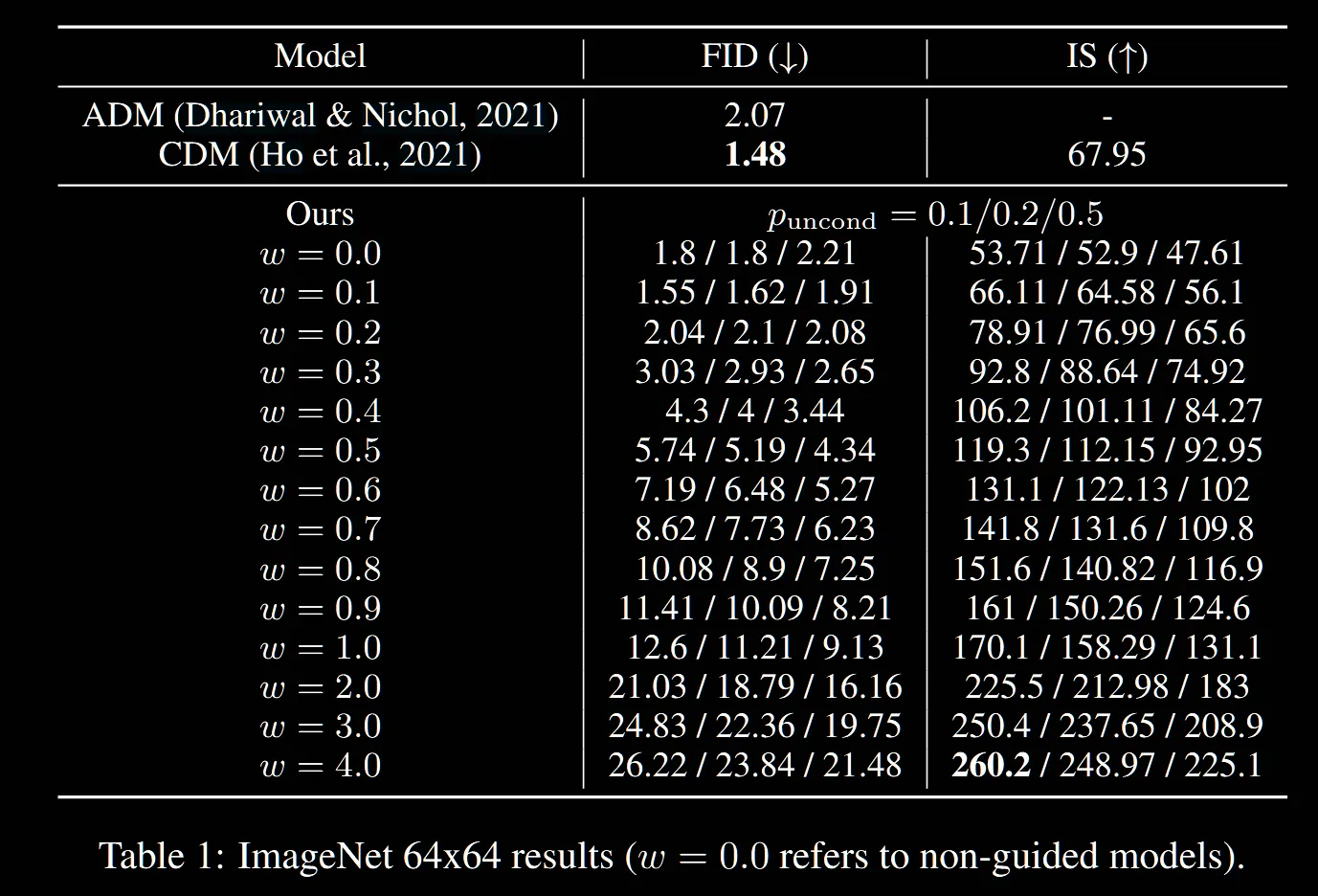
다시 돌아와서 해당 논문은 FID와 IS의 trade off를 보여줄 수 있다고 했습니다. 실제로 guidance strenght의 값이 커질수록 FID값과 IS값이 모두 높아지는 것을 볼 수 있습니다. 즉 다양성은 줄지만, 품질은 좋아지는 trade off가 성립하는 것을 볼 수 있습니다.
또 w값이 커질수록 FID에서는 의 값이 클수록 좋고, IS에서는 작을수록 좋은 것을 확인할 수 있습니다.
참고로 위의 과정은 400 thousand(continous) training steps를 이용했습니다.
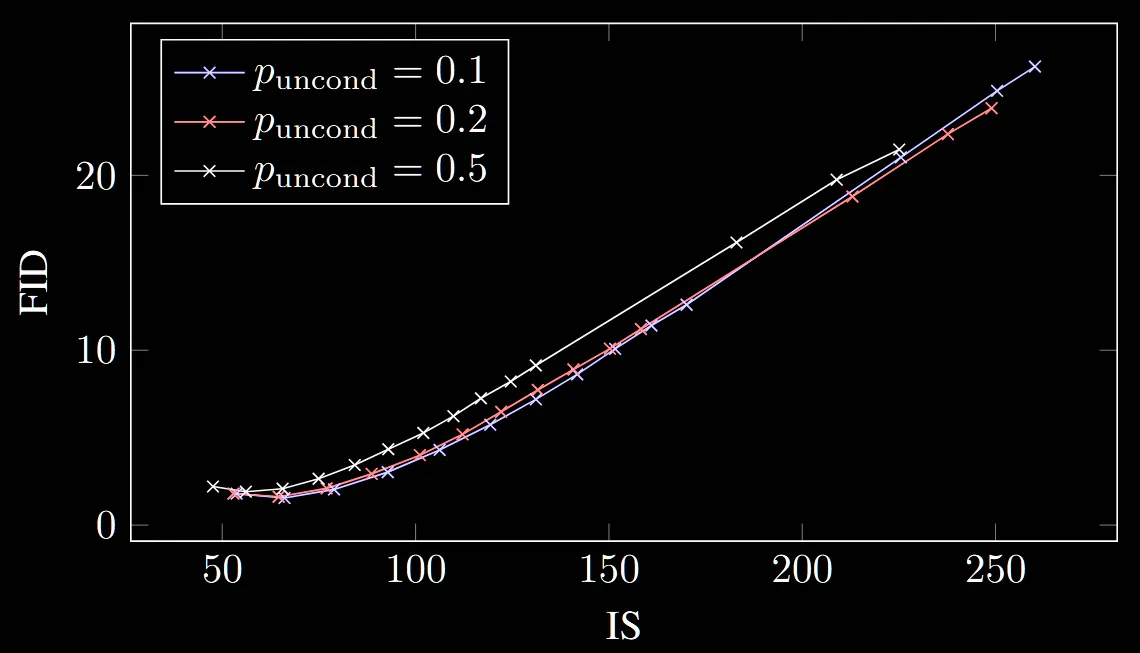
위의 그림을 통해서 FID와 IS의 trade-off를 시각적으로 다시한번 확인할 수 있습니다.
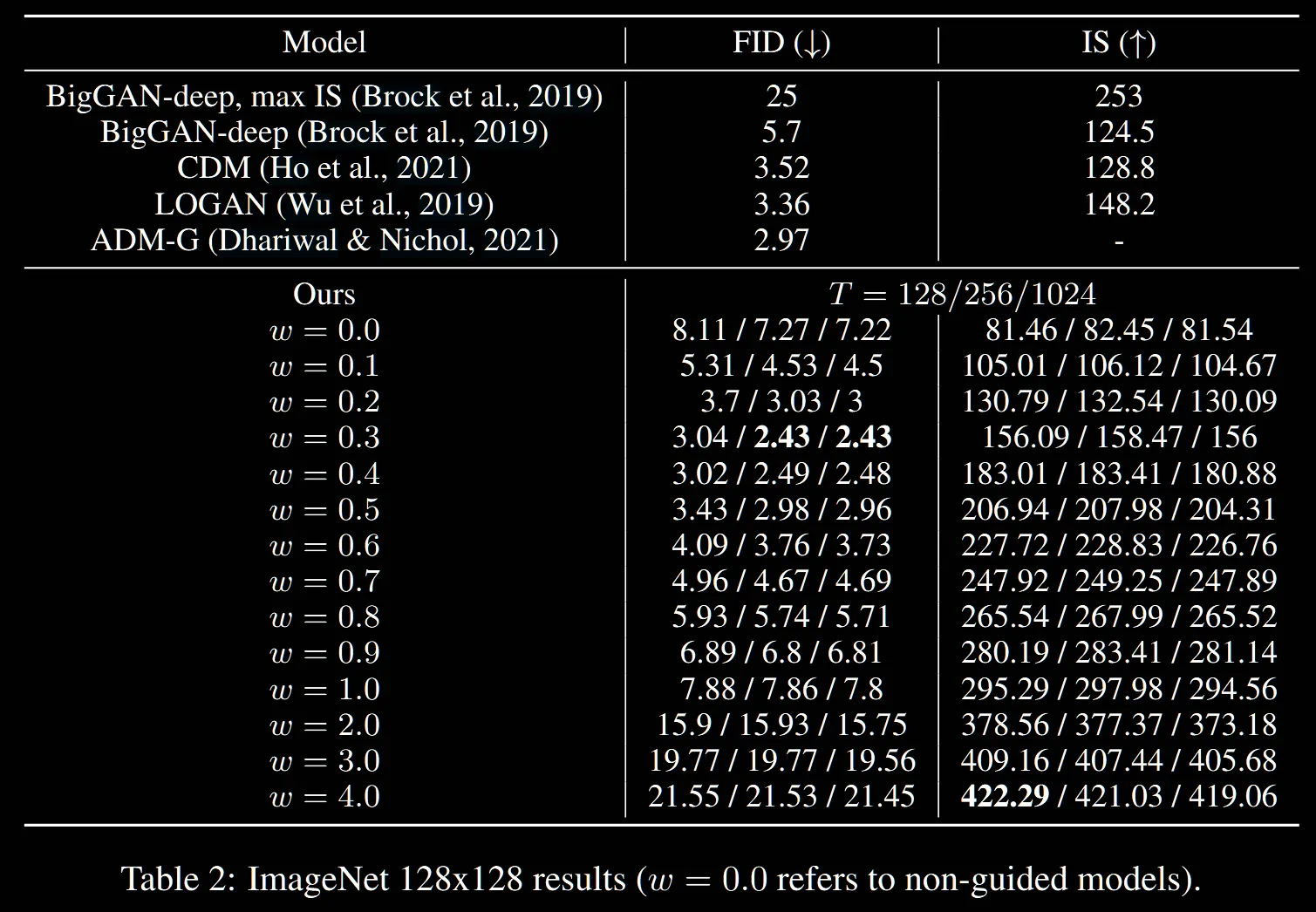
해당 Table은 time step(T)의 값에 따른 결과 비교를 진행한 것입니다. 이전 Table1과 다른점은 비교가 아닌 time step의 비교라는 점, ImageNet의 크기가 64x64가아닌 128x128이라는 점이 있습니다.
ADM-G가 기존 Classifier Guidance논문인데, 해당 논문에서는 256 step의 결과를 2.97이라고 제시했습니다. w=0.3일 때 T=256의 값이 2.43으로 Classifier-Free guidance의 논문의 FID값이 더 좋다고 볼 수 있습니다. 하지만 해당 논문에서는 conditional과 unconditonal 2번의 평가를 진행했기 때문에 T=128일 때와 비교하는게 좋지 않을까? 라는 논문의 의견도 있었지만, 개인적으로 해당 부분은 256으로 비교해도 괜찮다고 봤습니다.
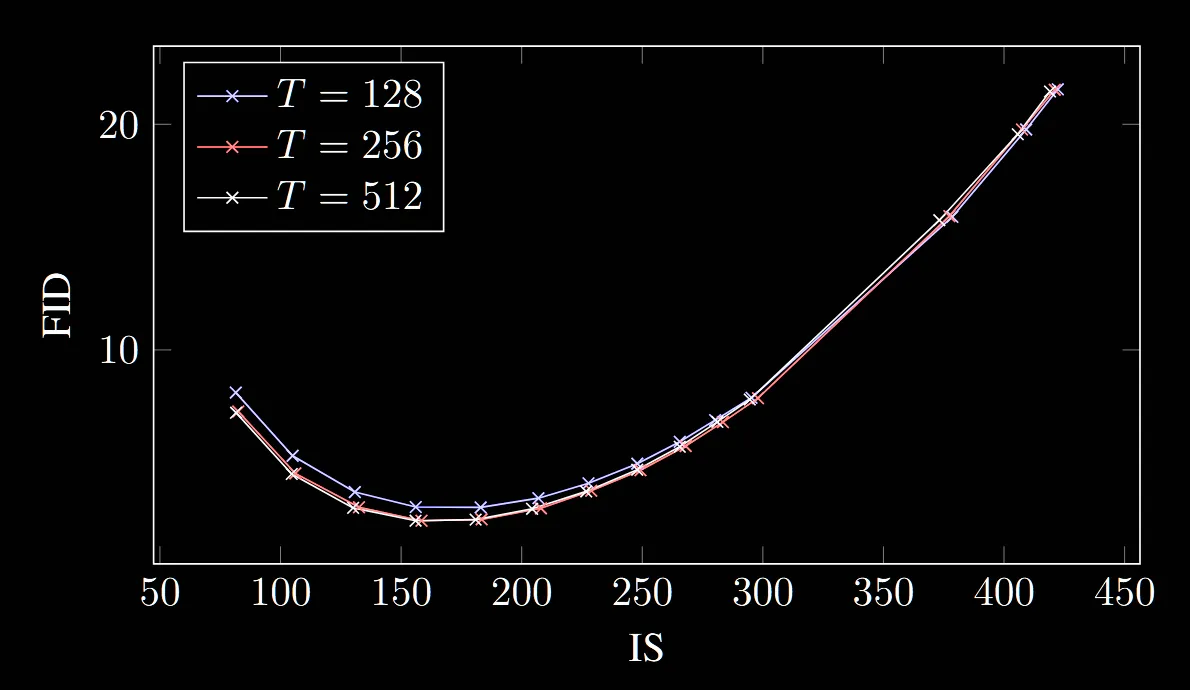
T의 값에 따라서 IS와 FID의 Trade off를 다시한번 시각화한 그림입니다.
Summary
Classifier를 사용해서 발생한 GAN의 단점들이나, 다시 많은 시간을 학습해야되는 점들의 단점을 Classifier를 제거함으로써 극복할 수 있었습니다.
추가적으로 Discussion 부분에 조건의 분포가 잘 알려져있고, class의 개수가 적은 경우 베이즈 정리 로 인해서 unconditional 정보를 학습 없이 구할 수 있다고 설명했습니다. 하지만 당연히 class 개수가 만커나 고차원 같은 데이터에는 적용할 수 없다고 했습니다.
