실제 코드들을 아래 링크에 첨부했습니다!
Jupyer Notebook 코드링크
안녕하세요! 오늘은 신용 거래 실적을 기반으로 대출의 전자사인 가능성 예측하기라는 새로운 프로젝트를 시작할 것입니다.
구축하는 모델에 대한 배경에 대해 먼저 알아보겠습니다.
오늘날 대부 업체는 대출 신청자의 신용거래 실적을 분석해 신청자의 위험성 여부를 판단합니다.
위험하지 않다면 대출을 해주고 대출조건을 결정합니다. 신청자 모집은 회사 웹사이트나 모바일 앱을 통해 고객이 방문하기를 기다리거나 광고 캠페인을 하기도 하지만 어떤때는P2P 대출 마켓플레이스와 제휴하기도 합니다.이 프로젝트에서는 우리 회사가 마켓플레이스로부터 받는 지원자들의 질을 평가합니다.여기서 P2P 마켓플레이스란? 다수의 대출 신청인을 모집해서 이들을 대부업체와 연결해 주는 중개업자로 기능하는 웹사이트, 회사를 말합니다. 현재 시장에 있는 이런 마켓플레이스는 Lending Tree, Upstart 등이 있고 그외에도 다수의 업체가 있습니다.
요약하자면 우리가 다룰 시장은 중간 마켓플레이스를 통해 접근한 모든 대출 지원자들의 집합입니다. 즉, 모든 대출 지원자는 이러한 p2p대출 마켓플레이스를 통해 도달합니다. 상품은 단지 대출입니다. 특별한 대출이 아닌 사람들이 만족해할만한 그런 대출입니다.
하지만 이프로젝트에서는 상품 자체가 관심사가 아닙니다. 우리가 받는 지원자들의 자격에 관심이 있습니다.정확한 목표는 지원자들의 질을 예측하는 모델의 개발입니다.이 경우 양질의 지원자는 대출 지원과정에서 특정 화면에 접속할 수 있는 사람을 말합니다. 따라서 양질의 지원자 대한 우리의 정의는 온보딩 과정의 전자 서명 부분에 도달하는 사람입니다.
우리의 최종 목표를 향해 달려가 보겠습니다.
최종목표는 👍 양질의 지원자들 ( e-sign을 마치는 지원자 )를 예측하는 것!!!
데이터
시작하기 전 데이터 feature들에 대해 알아보겠습니다.
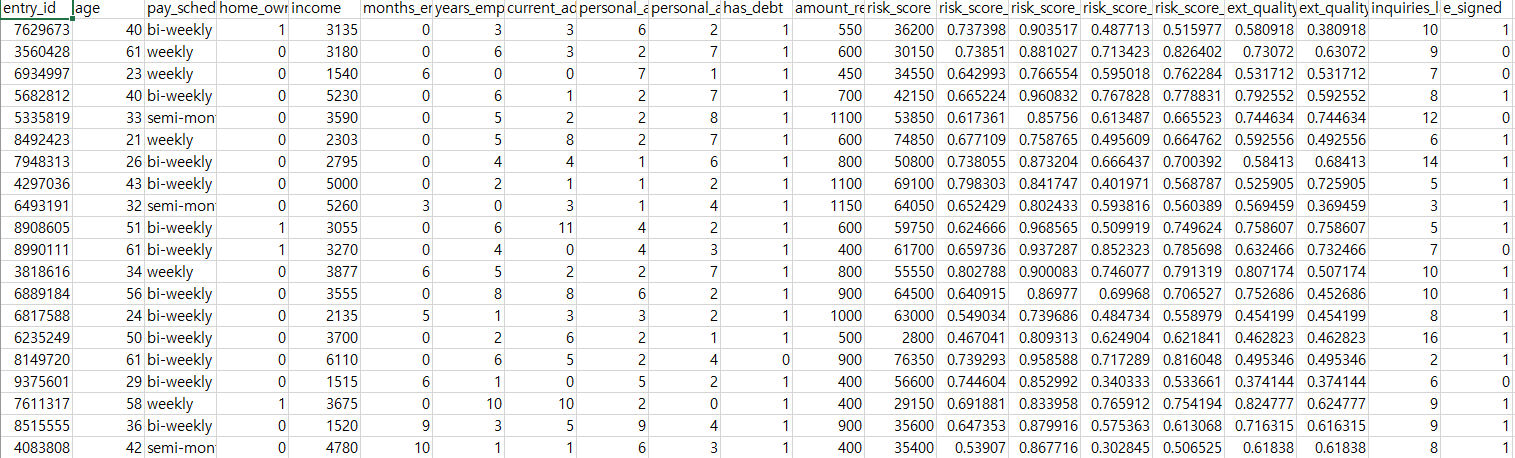
대출 마켓플레이스를 통해 데이터가 오기 때문에 온보딩 과정 시작 전 금융데이터들을 볼 수 있습니다.
-
entry_id : 유저 식별자
-
age : 나이 ( 금융 신청자는 최소 만18세 이상 )
-
pay_schedule : 지원자가 돈을 받는 빈도
weekly : 매주
bi_weekly : 격주
semy-monthly : 한 달에 2회
monthly : 한 달에 1회 -
home_ower : 자택보유 여부 1: 자가소유 집, 0: 주택의 임대 or 기숙사 거주
-
income : 수입으로 지원자들이 특정 달에 받는 모든 급료의 총합
-
years_emplyed : 현 직장에서 일한 년 수
-
current_address_year : 현 집에 거주한 년 수
-
personal_account_m : 개인 계좌를 보유한 개월 수
-
personal_account_y : 개인 계좌를 보유한 년 수
위 두개의 데이터들은 combination 데이터로 2년 6개월 보유했다면 y=2, m=6
-
has_debt : 빚이 있는지 여부
-
amount_requested : 대출지원자가 원하는 대출 금액
-
risk_score_1~5 : 5개의 점수 집합으로 금융데이터 엔지니어링팀이 제공하는 금융점수
지원자가 실제로 대출 지원을 마칠지 예측하는 점수이며 실제로 대출을 받을 수 있는지 여부와는 무관합니다.
-
ext_quality_score_1~2 : 마켈플레이스에서 제공한 2개의 점수
-
inquiries_last_month : 지원자가 지난달에 한 문의 수
-
e_signed : response variable 반응변수로 e-sign을 완료하면 1
2. 모델 구축진행
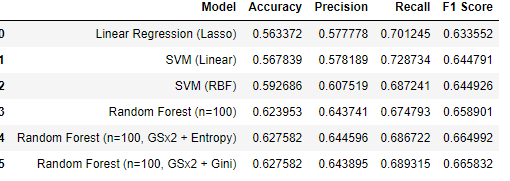
이번에도 물론 EDA, 모델구축, 모델완성 이런 방향으로 진행했습니다. 이번에는 모델구축에서 다양한 모델을 사용해 그 결과를 비교하는 DATAFRAME을 만들어보았고, 모델 중 최고 모델을 뽑아 PARAMETER를 최적화 하기 위해 GRID SEARCH까지 진행해 봤습니다. 컴퓨터가 매우 좋은 CPU를 가지고 있는 것은 아니라 걸리는 시간도 TIME 라이브러리를 활용해 재보니 시간이 꽤 걸리는군요 .... 이래서 기업에는 성능 높은 컴퓨터들이 있는 것임을 깨달았습니다... 물론 제가 걸린 시간은 몇분 밖에 되지않지만 기업에서 돌리는 데이터들을 제 컴퓨터로 돌린다면 아마 터질 것 ... ㅎ ... 무튼! 이렇게 GRID SEARCH까지 진행한 결과를 DATAFRAME으로 만들어보니 가시성도 좋고 비교하기도 좋은 것 같습니다.
분류성능평가지표
추가적으로 모델 평가를 할 때 사용되는 분류성능평가지표에 대해 간단히 설명하겠습니다. 그 전에도 계속 사용했지만 이제와서 생각이나서 다시 한번 정리해보려합니다.
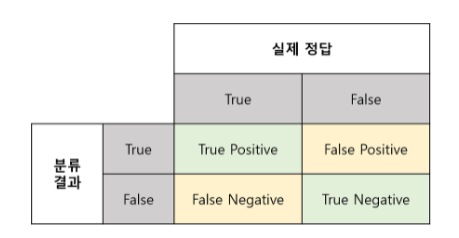
True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
-
- Accuracy ( 정확도 )

가장 직관적으로 모델의 성능을 나타낼 수 있는 평가 지표입니다. 하지만 여기서 고려해야하는 것이 있습니다. 바로 domain의 bias입니다. 만약 우리가 예측하고자 하는 것이 한달 동안의 기후라해봅시다. 하지만 비가오는 날이 하나도 없다면? 이 경우에는 해당 data의 domain이 불균형하게 되므로 '맑다'를 예측하는 성능은 높지만 비오는 것을 예측하는 성능은 낮을 수 밖에 없습니다. 따라서 이를 보완할 평가 지표가 필요합니다.
- Accuracy ( 정확도 )
-
- Precision ( 정밀도 )
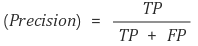
정밀도란 모델이 True라고 분류한 것 중 실제 True인 것의 비율입니다. 날씨 예측 모델이 '맑다'라고 예측했는데, 실제 날씨가 맑았는지를 살펴보는 지표입니다.
- Precision ( 정밀도 )
-
- Recall ( 재현율 )
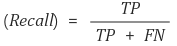
재현율이란 실제 True인 것 중 모델이 True라고 예측한 것의 비율입니다. 통계학에선 Sensitivity라고도 합니다. 실제 날씨가 맑은 날 중 모델이 맑다고 예측한 비율을 나타낸 지표입니다. Precision이나 Recall은 모두 실제 True인 정답을 모델이 True라고 예측한 경우에 관심이 있으나, 바라보고자 하는 관점만 다릅니다. Precision과 Recall은 상호보완적으로 사용할 수 있으며, 두 지표가 모두 높을 수록 좋은 모델입니다.
- Recall ( 재현율 )
-
- F1 score
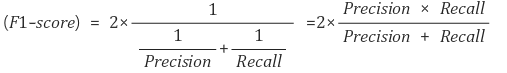
- F1 score
F1 score는 데이터 label이 불균형 구조일 때, 모델의 성능을 정확하게 평가할 수 있으며, precision과 recall의 조화평균으로 성능을 하나의 숫자로 표현할 수 있습니다. 앞에서 배운 정확도의 경우, 데이터 분류 클래스가 균일하지 못하면 머신러닝 성능을 제대로 나타낼 수 없기 때문에 F1 Score를 사용한다.
3. 마치며!
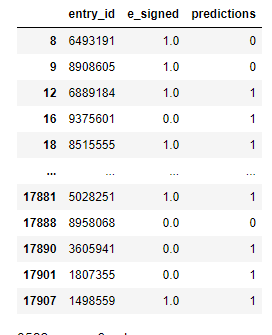
각 유저와 e_signed 또 그에관한 예측을 마무리하며 모델완성을 했습니다. 처음 보이는 2개가 벌써 틀린 예측을 했네요. 하지만 저는 정확도가 약 64%인 것을 알아요 ... 😂
이 모델을 사용해 전자서명까지 가지 못하는 user에 관해서 집중해 온보딩을 할 수 있을 것 같습니다. 온보딩을 설계하여 최대한 많은 사용자가 이 과정을 마치고 전자서명까지 가게 해야겠죠!
이로 인해 숫자를 늘릴 수 있다면 회사의 이익또한 같이 증가할 것입니다.
이러한 사례연구를 통해 회사가 이익을 얻기 위해 복잡한 머신러닝 모델이 필요하지 않다는 것을 알 수 있습니다. 데이터 과학자가 회사에 입사할 때 모두 5~10년 경력을 가지고 있지않습니다. 저같은 경우처럼 말이죠. 그러나 비스니스 맥락을 이해하고 간단모델을 사용한다 해도 회사에 이익을 줄 수 있다는 생각이 듭니다. 앞으로도 화이팅!
