
아래에는 프로젝트 진행 중 작성 코드 링크입니다!! ( 설명도 주석으로 달려있어요~)
Jupyter Notebook으로 작성 된 코드 링크입니다!
개요
구독 상품 해지를 최소화하는 새로운 프로젝트를 시작하겠습니다.
이전 프로젝트와 비슷하고 대부분 이런 회사들은 구독해지를 최소화 하려고 합니다.
구독 해지를 피하기 위해서는 해지로 이어지는 유저의 패턴을 알아야합니다 !
이번 모델의 target은 회사의 구독 상품을 구독하고 있는 모든 고객입니다.
제가 작업하는 이 모델의 진가를 아직 회사가 알지 못할 수 있지만 큰 가치를 창출할 수 있다고 생각하는 모델입니다.
자 이번 프로젝트의 최종 목표는
👍 해지할 가능성이 높은 유저를 예측해 이들이 재구독하는 데에 집중하는 것이라 할 수 있습니다.이는 상품이 고객에게 주는 이점을 상기시키거나, 사용자가 흥미있어 할 만한 상품을 추가하는 것일 수 있습니다.
데이터 살펴보기
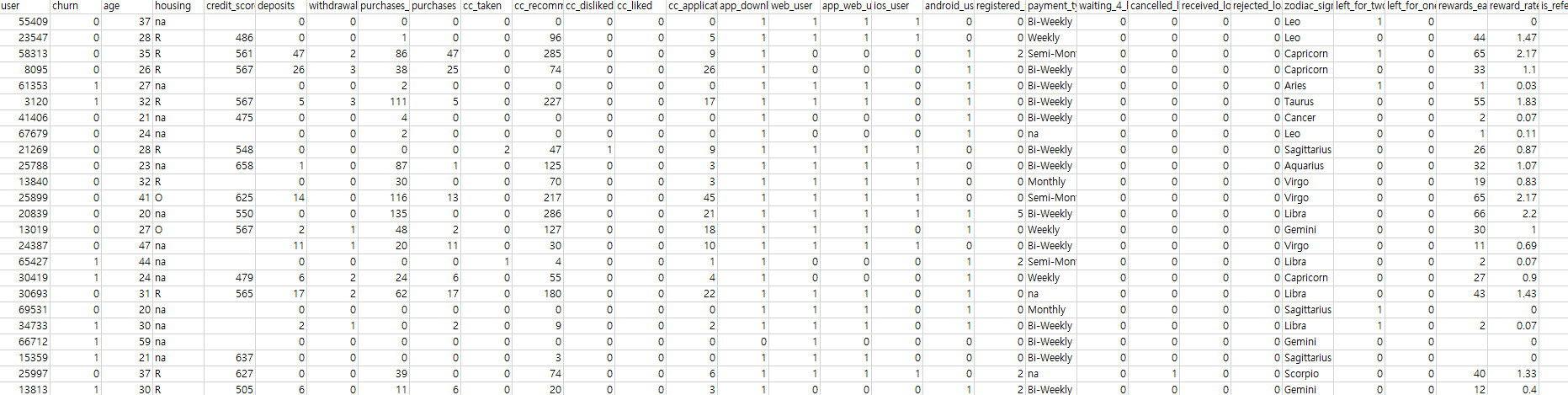
데이터를 살펴보고 어떤 feature가 중요한지 생각해 보는 시간을 가지겠습니다.
- user : 유저 식별자
- churn : 이탈 즉 반응 변수 입니다. 이 사람이 상품 구독을 취소했는지 아직 구독중인지.. 이는 최신 상태입니다.
- age : 유저의 나이
- housing : 범주형 변수로 na, R, o 세가지 수준이 있습니다. 거주상태의 변수입니다.
R : 주택을 임대한 상태
o : 주택을 소유한 상태
na : 거주 상태에 대한 데이터가 없음 - credit_score : 신용점수가 있는 사람의 점수
- deposits : 유저가 돈을 자기 계좌에 입금한 횟수
- withdrawal : 유저가 돈을 출금한 횟수
- purchases : 유저가 계좌에서 소비한 횟수 (회사는 다양한 제휴 상점과 계약해 유저들에게 할인을 제공)
제휴 상점
외의 가게에서 구입한 횟수 - purchases_partners : 유저가 계좌에서 소비한 횟수 (회사는 다양한 제휴 상점과 계약해 유저들에게 할인을 제공)
제휴 상점의 가게에서 구입한 횟수
- cc_taken : 이 feature를 비롯해 cc가 붙는 열은 신용카드 상품과 관련이 있습니다.
이 회사는 유저들이게 자신의 금융 습관에 따라 신용카드를 사용하도록 권하는 경우가 있는데 유저가 그 권고를 받아들였는지의 여부를 알려줍니다.cc_taken은 유저가 가진 신용카드 수입니다.
- cc_recommended : 신용카드를 추천받은 횟수입니다.
추천은 이 상품의 많은 스크린에서와 기능에서 일어납니다. 예를들어 개인정보를 입력하거나 특별 할인페이지로 이동 시 금융습관에 따라 신용카드를 권장하는 스크린이 뜨기 시작
- cc_disliked : 유저가 신용카드를 거부한 횟수입니다.
- cc_liked : 유저가 신용카드를 발급한 횟수입니다.
- cc_application_begin : 신용카드 신청을 시작한 횟수입니다. 신청이 완료됐는지는 알 수 없습니다.
- app_downloaded : 앱 다운로드 여부입니다. ( 이진 변수 )
- web_user : 우리의 웹사이트를 경험했는지 여부입니다. ( 이진 변수 )
- app_web_user : 앱과 웹 둘다 사용했는지 여부입니다. ( 이진 변수 )
- ios_user : ios 유저인지 여부입니다. ( 이진 변수 )
- android_user : 안드로이드 유저인지 여부입니다. ( 이진 변수 )
- registered_phones : 유저가 몇개의 휴대폰을 등록했는지 나타냅니다.
- payment_type : 유저가 돈을 받는 빈도 입니다.
bi-weekly : 격주
weekly : 매주
semi-monthly : 월 2회
monthly : 월 1회
na : 없음 - waiting_4_loan : 대출 상태가 대출 대기 중이라는 의미입니다.
유작 대출을 신청했고 승인을 기다리는 중이라면 이 상태에 해당합니다.
- cancelled_loan : 과거 어느 시점에서든 유저가 대출을 취소한 적이 있는지 나타냅니다.
취소한 적이 없다면 0 입니다. - received_loan : 대출을 받은 적이 있다 1 , 없으면 0
- rejected_loan : 유저가 대출을 거부한 적이 있다 1, 없으면 0
거부한 대출이란 법적으로 대출은 승인 되었지만 유저가 대출제의를 거절한 경우
- zodiac_sign : 별자리
- left_for_two_month_plus : 유저가 2개월 이상 제품을 사용하지 않다가 다시 돌아온 경우 1, 아니면 0
- left_for_ont_month : 유저가 1개월 이상 제품을 사용하지 않다가 다시 돌아온 경우 1, 아니면 0
- rewards_earned : 유저가 획득한 포인트를 나타냅니다.
상품마다 좋은 금융 습관에 대한 다양한 보상 옵션이 있습니다. 그 행동에 따라 포인트를 얻습니다.
- is_referred : 유저가 다른 사람에게 추천받은 적이 있는지 여부입니다.
친구나 가족에게 특정 추천코드로 추천받게 되면 이 항목에 표시가 됩니다.
프로젝트 과정
-
1. EDA 및 전처리
Removing NAN
Histogram
Pie chart of binary feature
Correlation -
2. 모델 구축
One-hot encoding
Balancing the training set
Feature Scailing
K-Fold Cross Validation
Analyzing Coefficients
Feature Selection
3. 모델 완성
user, y_test, y_pred를 정렬하여 matching 하며 마무리
마무리 하며
여러개의 모델을 구축하며 모델 구축 과정이 전체적으로 유사하는 점을 알게됬었지만 항상 EDA는 바뀌었던 것 같습니다. 데이터가 구조화된 방식이 바뀌어서 그런 것 같습니다.
balancing the training set 부분도 처음 확인 하는 개념으로 새로웠으며 다른 프로젝트에도 적용해봐야 겠다는 생각이 들었습니다.
또한 마지막 feature selection을 통해 40개의 feature 중 20개 즉 절반으로 줄여도 그 결과 값은 비슷했으며 대부분의 가중치, 예측력이 있는 변수이름을 matching 해봤습니다. 이 과정에서 Analyzing Coefficients를 진행하며 중요한 coef를 추출하면서 확인하는 정보들도 도움이 됬습니다.
62%의 정확도를 가졌습니다. 어떻게 보면 영향력이 적은 모델이라 생각할 수 있지만 정제되지 않은실무 데이터를 사용해 불필요한 feature들을 제외시키고 unbalance한 반응변수들을 완벽히 예측하는 것은 힘들 수 있습니다.
62%의 정확도를 가진 모델이 나쁘다 할 수 없습니다. 하지만 더욱 성능을 끌어올릴 수 있는 방법은 계속해서 찾아봐야합니다! 아마 반응변수에 시간적 제약을 도입한다면 더욱 정확도를 끌어올릴 수 있을 것입니다.
이번 프로젝트에서 유저가 언제 해지할지는 예측하지 않았습니다.
하루, 한달 혹은 일 년 후일지는 모르는채 남겨두었습니다. 그렇다면 이것은 실제 예측이 맞았는지 검증하는 것은 거의 불가능합니다.
이번 프로젝트의 목적은 어떤 필드가 유저의 해지를 유도하는지 탐색하기 위함입니다.
여전히 이 모델을 잘 활용할 수 있습니다. 제품을 해지할 가능성이 조금이라도 있는 사람을 식별할 수 있기 때문입니다. 그러면 흥미를 잃어 가는 유저에게 새로운 기능을 제공할 수 있습니다.
새로운 제품이나 제품 기능이 나온다면 이 프로젝트의 모델이 해지 가능성이 적은 유저를 예측합니다.
