지난 Sincnet
- IEEE SLT 2018에 게재된 SincNet 논문(https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8639585)에서 1D convolution의 연산 원리 참고
본 논문
- Interspeech에 2019 나온 논문: https://arxiv.org/pdf/1904.03416.pdf
Abstract
-
머신러닝에서 supervision 없이 좋은 representation을 학습하는 것은 -> speech signal에서 challenge하다
- speech signal이 complex hierarchical structure로 인해 long sequence로 특징화되어서
-
몇 연구들은 -> 유용한 speech representation을 derive하는 것이 가능함을 입증함 (self-supervised encoder-discriminator approach를 이용해서)
-
본 논문
- improved self-supervised method 제시 (single neural encoder가 multiple workers로 작동해서 -> 다양한 self-supervised task를 jointly하게 수행하는)
- 여러 task는 당연히 일치를 위해 encoder에 제약을 가한다 -> general representations를 발견하려고 노력하고, superificial ones를 학습하는 위험을 최소화하는
-
실험
- transferable, robust, problem-agnositc feature를 잘 학습함
Approach:
(1) 앙상블 뉴럴 네트워크 모델을 가지고,
(2) 여러가지 self-supervised downstream task 문제를 해결해서,
good speech representation을 discover하자!
Introduction
Background & Limitation
-
딥러닝이 발전하지만 supervised learning이 가진 한계점 지적 (라벨링있는 데이터 필요) -> 그렇다면 무슨 해결책이 있는가.
-
unsupervised learning으로 라벨링 없는 데이터에서 정보 추출하자 !
- 이미 이 방법을 쓴 좋은 사례들이 이전 연구에서 발견되었다 (autoencoder, boltzmann machines, variational autoencoder, generative adversarial network)
-
cv에서 관련된 분야는 -> self-supervised learning으로 target은 singal 그 자체에서 계산
- -> 이게 실행되는 방법은 input data에 known transforms 나 sampling strategy를 적용해서 resulting outcomes를 target으로 쓰고자 하는 것
- self--supervised learning을 다른 모달리티나 audio representation에만 확장하려는 연구들도 있었음
- 최근에는 neural network encoder를 binary discrimiantor로 쓰자는 방향
-
self-supervised learning을 speech에 적용하는 것에는 여전히 challenge가 있음
- speech -> high dimensional, long, variable-length seqeuce + entail complex hierarchical structure (supervision 없이는 infer가 어려운 형태)
-
그래서 single self-supervised task를 찾는 것이 어려움 !! (latent structure를 포착하는 것이 가능한 general한 것을 찾는 일) -> 하나로 일반화해서 모든걸 처리하는게 어렵다는 뜻인건가?? 그래서 ensemble을 도입시켜서 다 해결해보자 이런 맥락인건가
Solution
-
multiple self-supervised task를 jointly하게 tackle하자
- 어떻게? ensemble of neural networks를 써서
- self-supervised task은 학습된 representation에 different view나 soft constrain가 나타날 수 있음 (모든 self-supervised task가 supervised problem 그 자체에 도움이 되지는 않을 수도 있지만, 도움이 되는 subset이 있을 수도 있음)
- task간의 consensus를 필요로 함 -> learned representation에 several constratints를 필요로 함
-
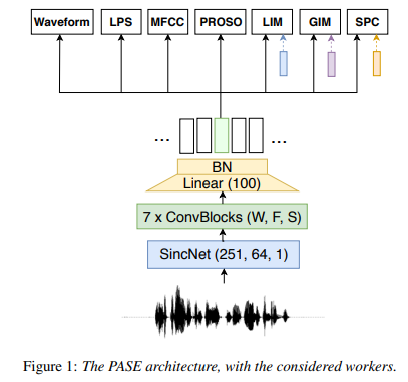
problem-agnostic speech encoder (PASE)
- raw speech waveform을 representation으로 encode 함 (multiple regressor와 discriminator에 주어지는)
- 그 후 multiple regressors and discriminator를 거침
- regressor는 input waveform에서 계산된 standard feature로 작동하며 signal을 여러 방법으로 resembling 함
- discriminator는 pos/neg sample을 따르고 각각으로 훈련되어서 -> binary cross entroy로 최소화 됨 (왜 pos/neg 지??? 이건 task 마다 다른거 아닌가???) -> constrative learning으로 훈련하는 구조임
- worker라고 불리는 이 둘은 -> encoder에 사전지식을 넣는 방법으로 기여하며 -> 이는 의미있는 representation으로 가는 길이 됨
Experiment Result
- hand-crafted features를 여러 분류 task에서 압도함
- 그래서 PASE는 speech feature extractor의 보편적인 방법이 될 수 있을 것이다
발표 내용 정리
논문 전체를 정리한, Study 발표: https://velog.io/@delee12/ASR-Paper-Review-PASE-Learning-Problem-agnostic-Speech-Representations-from-Multiple-Self-supervised-Tasks-PASE
PASE Goal
-
데이터가 부족하니까 unsupervised learning으로 해보자 !
-
자체적으로 라벨 만들어서 알아서 학습한다 !!
-
500ms 최소한 떨어진 애들을 sampling하는 이유?? -> longer time context 정보 학습 하려고 !!
Architecture
-
PASE Features 까지가 encoder고, 그 뒤에 workers를 decoder로 생각해보기?? (feature를 사용해서 다른 task에 써본다? worker는 학습을 위한 도구로 사용한 것)
-
PASE Feature를 효과적으로 뽑는 방법 -> worker를 사용
-
그 feature를 사용해서 -> 다른 task에 사용한 것
-
PASE+는 worker를 더 늘려서 -> 더 다양하게 해보자~~
