발표는 아니어서 논문 전체를 읽지는 않지만, 그래두 공부해보기 !!!!!!! 논문 정리하기 !!!!
Neural Acoustic feature extraction 관련 논문이다
0 Abstract
-
raw audio의 representation을 학습하여 -> unsupervised pre-training을 탐구 (speech recognition)
-
wav2vec은 라벨링 없는 엄청난 양의 오디오 데이터에 훈련됨 -> 그러고나서, resulting representation이 acoustic model training을 높이고자 쓰임
-
본 연구는
- simple multi-layer convolutional neural network를 pre-train함
- 이 네트워크는 noise constrastive binary classification에 의해서 optimize됨
- simple multi-layer convolutional neural network를 pre-train함
-
실험 결과
- WSJ에서의 실험은 strong character-based log-mel filterbank baseline을 36% 낮춤 -> transcribed data가 few hours로 필요했을때.. ???
Wall Street Journal (WSJ) 유명한 오디오 데이터인가보다 !
word error rate (WER)
- WSJ에서의 실험은 strong character-based log-mel filterbank baseline을 36% 낮춤 -> transcribed data가 few hours로 필요했을때.. ???
-
approach
- nov92 test set에서 2.43% WER 상승
- -> Deep Speech 2를 능가하는 점수임 (character-based system에서 가장 우수하다고 알려진, 라벨링 적은 훈련 데이터 쓸 때)
- nov92 test set에서 2.43% WER 상승
1 Introduction
- speech recognition의 SOTA는 -> transcribed audio data 많이 필요로 함 (좋은 성능 위해)
- 최근 -> neural network를 pre-training하는 것이 -> effective technique으로 등장 (라벨링 데이터가 희귀할때) # 아 옛날에는 훈련 데이터 많아야지 SOTA 였는데 neural network의 pre-train이 새로운 맥락으로 등장했다는 거네
- 주요 아이디어는 -> set up에서 general representation 학습하기
- 1) 엄청난 양의 라벨링된/안된 데이터가 -> 이용 가능, +
- 2) learned representation을 활용하기 위해 -> down stream task에서 성능 향상 위해
- 이런 부분들은 speech recognition 같은 라벨링된 데이터를 필요로 하지 않을 때 특히 흥미로운 태스크다 !
- 주요 아이디어는 -> set up에서 general representation 학습하기
요약: 기존 speech recognition에서는 라벨링 있는 데이터 필요했는데 => neural network 등장으로 맥락에 변화 생김 (+ speech recognition 은 라벨링 필요로 하지 않아서 (Task 특성상) -> neural network가 특히 신기해 !!
- 컴퓨터비전에서 ImageNet, COCO를 위한 representation들은 -> image captioning 같은 task에서 모델 초기화하는데 유용하다고 알려짐
- 컴퓨터 비전에서 unsupervised pre-training은 또한 -> 유망하다고 알려짐
- NLP에서 -> LM을 unsupervised로 pre-training하는 것 -> 성능 향상
- speech processing -> pre-training은 emotion recognition / speaker identification / phoneme discrimination / transferring ASR representations from one language to another
- unsupervised learning 관련해서도 있었지만 -> 결과들은 supervised speech recognition을 향상하기에 적용 X
CV, NLP, Speech에서 지도/비지도 관련해서 어떤 연구들이진행되어졌느가 서로서로 비교
- unsupervised pre-training을 적용해서 -> supervised speech recognition을 향상하자
- 이를 통해 라벨링 안된 데이터 이용 가능 해짐
- 제시하는 모델은 "wav2vec"
- convolutional neural network이고, raw audio 를 input으로 받아들이고 general representationd을 compute하는데 -> speech recognition system에서 그게 input이 될 수 있음
- contrastive loss 를 목표로 두어 -> true future audio sample을 negative에서 구별하는것
- 이전 연구와 달리, beyond frame-wise phoneme classification를 옮기고, learned representations를 적용해서 strong supervised ASR system을 향상시킴 ???
- wav2vec은 -> a fully convolutional architecture에 의존 => 시간에 따라서 쉽게 병렬화됨
모델 설명인데 "wav2vec" 제시했고, 비지도 사전 학습을 통해 지도학습 성능을 올리자 !! 모델 구조는 아직 이해못했다 ,. 블로그 포스팅을 봐보자
- WSJ benchmark에서의 실험 결과
- unlabeled speech에서 1000시간 estimated된 pre-trained representations가 character-based ASR system의 성능 향상에 도움
- SOTA 달성 (Deep Speech 2를 이겼다)
- simulated low-resource setup 에서 8시간만 transcribe된 오디오 데이터로 wav2vec은 WER를 36%나 감소시킨다
Method
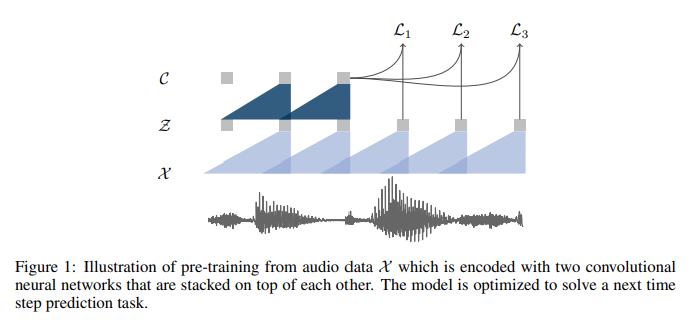
- 오디오가 입력으로 주어지면, 모델을 최적화하여 주어진 신호 context에서 향후 샘플 예측
아직 잘 모르겠는 것들??
Deep Speech 2
해당 포스팅을 참고하여 이해한 내용 간략하게 정리 !!
- End-to-End 음성 인식 모델
- 강점
- 음성 인식에 유리한 모델 아키텍처
- 대규모(1만 시간 가량) 학습 데이터 적용
- 효율적인 학습 테크닉 : Connectionist Temporal Classification(CTC) loss 직접 구현
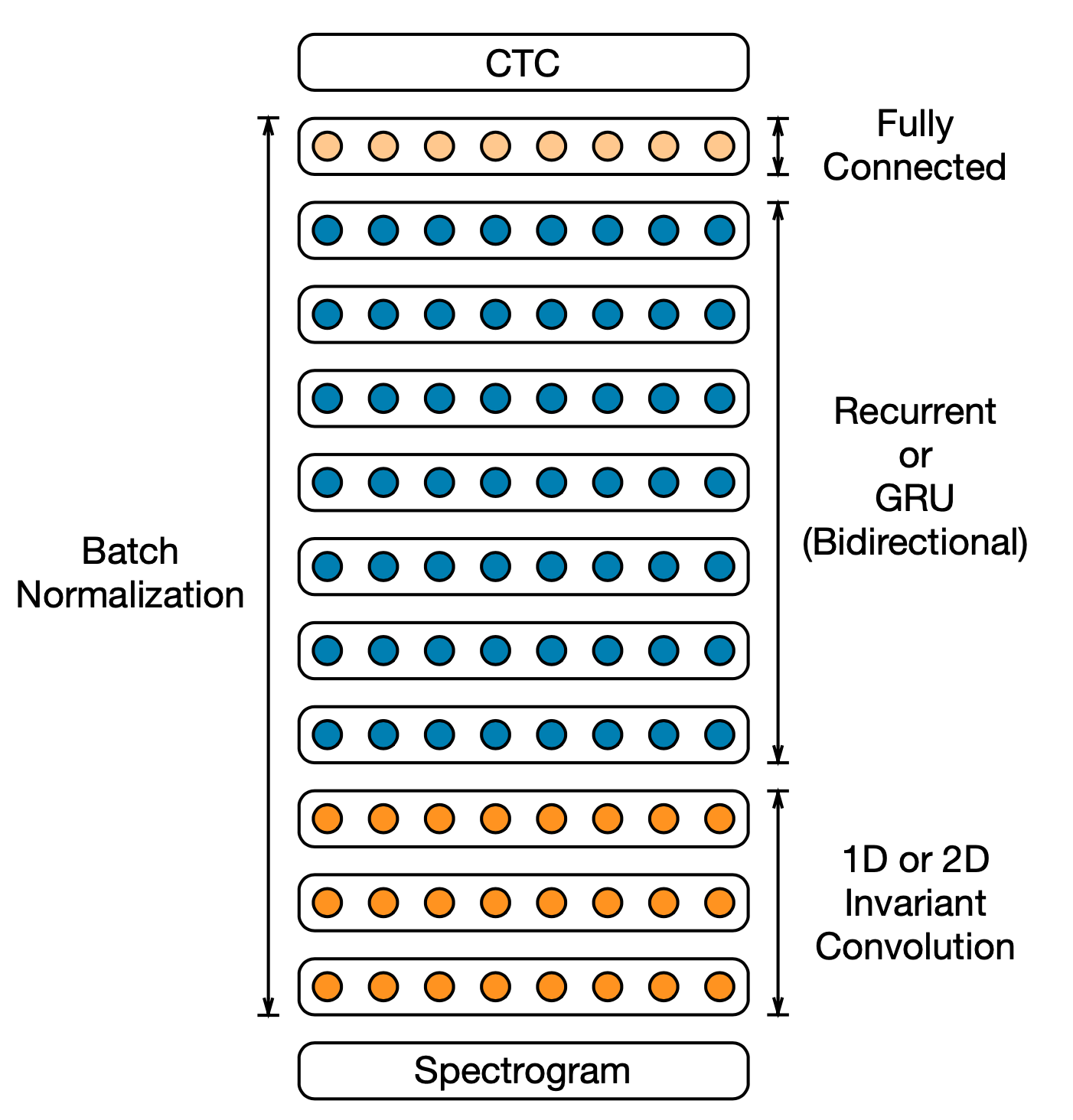
- 모델 구조
- CNN - 음성 입력에서 중요한 특징 추출하는 레이어
- 양방향 RNN
- FC layer
- 각 레이어 사이에는 배치정규화
wav2vec
- arxiv paper link: https://arxiv.org/pdf/1904.05862.pdf
- github:https://github.com/facebookresearch/fairseq/tree/v0.7.2
