
이상처리에 적합한 가상 데이터를 활용한 데이터 클리닝
주어진 데이터 불러오기
import pandas as pd
import numpy as np
# 가상 데이터 생성
data = {
'TransactionID': range(1, 21),
'CustomerID': [101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110],
'PurchaseAmount': [250, -50, 3000000, 450, 0, 300, 200, 150, -10, 800, 50, 75, 400, np.nan, 600, 1000, 20, 5000, 150, 80],
'PurchaseDate': pd.date_range(start='2024-01-01', periods=20, freq='ME').tolist(),
'ProductCategory': ['Electronics', 'Clothing', 'Electronics', 'Home', 'Electronics', 'Home', 'Clothing', 'Home', 'Clothing', 'Electronics', 'Electronics', 'Home', 'Clothing', 'Electronics', 'Home', 'Home', 'Clothing', 'Electronics', 'Home', 'Electronics'],
'CustomerAge': [25, 35, 45, np.nan, 22, 29, 33, 41, 27, 36, 28, 34, 42, 39, 24, 30, 32, 40, 38, 26],
'CustomerGender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male', 'Female', np.nan, 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female'],
'ReviewScore': [5, np.nan, 4, 3, 2, 5, 3, 4, 1, 2, np.nan, 4, 5, 3, 4, np.nan, 1, 5, 2, 4]
}
df = pd.DataFrame(data)가상 데이터를 과제란에서 복붙함.
데이터를 확인해보자.
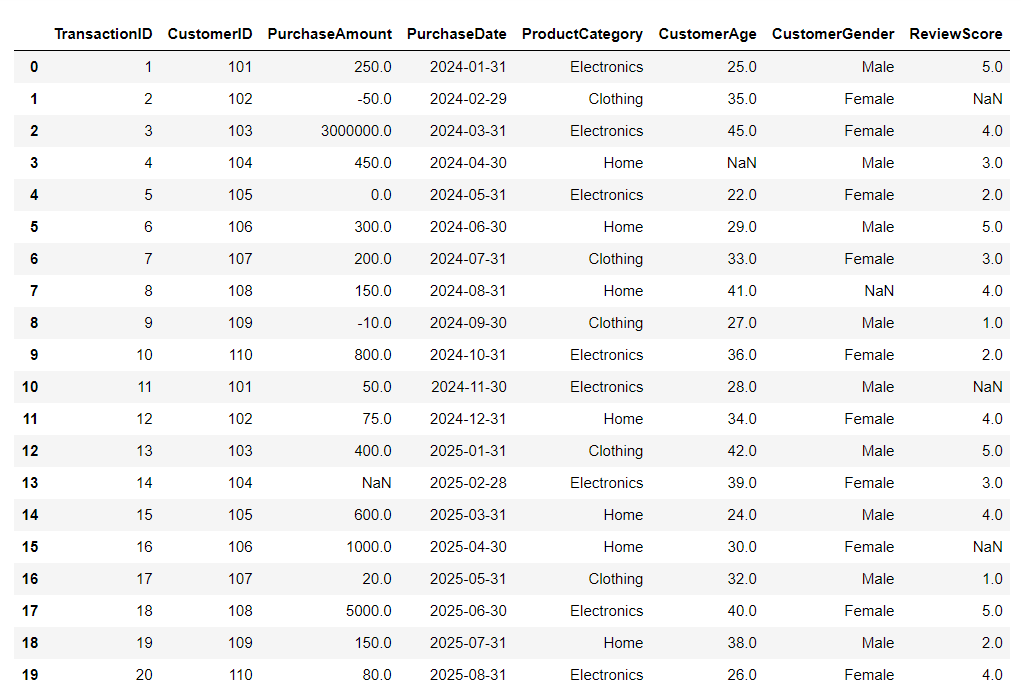
이런식으로 나와서 한눈에 파악하기 쉬운 데이터임을 알 수 있다.
결측치 제거하기
결측치를 제거하라고 했다.
PurchaseAmount, CustomerAge, CustomerGender, ReviewScore 이 네 칼럼에 NaN값이 있고 이를 적절히 처리하는 문제다.
CustomerGender값만 최빈값으로, 나머지는 각 열들의 평균값으로 바꿔보자고 접근함
df['PurchaseAmount'] = df['PurchaseAmount'].fillna(df['PurchaseAmount'].mean())
df['CustomerAge'] = df['CustomerAge'].fillna(df['CustomerAge'].mean())
df['CustomerGender'] = df['CustomerGender'].fillna(df['CustomerGender'].mode()[0]) # 최빈값 찾기
df['ReviewScore']=df['ReviewScore'].fillna(df['ReviewScore'].mean())참고
df['ReviewScore'].fillna(df['ReviewScore'].mean(), inplace=True)이렇게 inplace를 사용해서 결측치를 바꾸려 했을 때
pandas 3.0에서 inplace=True 방식이 더 이상 작동하지 않을 수 있음을 알려주는 경고가 떴다.
또 최빈값을 mode()로 구하고 뒤에 []속의 첫 번째 최빈값을 나타내는 0을 넣어주었다. 최빈값들이 여러개 있을 때 숫자를 바꿔서 넣으면 된다.
이상치 제거하기
(PurchaseAmount 열에서 비정상적으로 큰 값과 음수 값을 처리하세요.)
PurchaseAmount칼럼을 살펴보니 음수값들과 3000000인 값처럼 비정상적인 값들을 볼 수 있다. 이 값들은 가진 행을 지워보자.
df = df[(df['PurchaseAmount'] >= 0) & (df['PurchaseAmount'] < 100000)]이렇게 음수와 100000 이상 값들을 지울 수 있다.
중복 데이터 제거하기
중복된 TransactionID가 있는 경우 제거하세요.
TransactionID에서 중복된 데이터는 없었는데 하라니까 했다.
df = df.drop_duplicates(subset=['TransactionID']) # 중복된 TransactionID없는뎅데이터 타입 변환
PurchaseDate 열의 데이터 타입을 날짜 형식으로 변환하세요.
PurchaseDate열도 이미 날짜 형식임을 알 수 있다.
해보라니까 했다.
df['PurchaseDate'] = pd.to_datetime(df['PurchaseDate'])
df.dtypes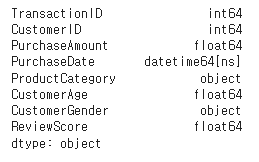
정규화 하기
PurchaseAmount 열을 정규화하세요.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['PurchaseAmount'] = scaler.fit_transform(df[['PurchaseAmount']])
df정규화에 필요한 라이브러리를 불러와서 실행함.
범주형 데이터 선별 및 인코딩
ProductCategory와 CustomerGender 열을 인코딩하세요.
원-핫 인코딩을 해야하나 하다가 힌트보고 더 쉽게 하는 방법이 있었다.
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df['ProductCategory'] = encoder.fit_transform(df['ProductCategory'])
df['CustomerGender'] = encoder.fit_transform(df['CustomerGender'])
df인코딩에 필요한 라이브러리를 불러오고 편하게 인코딩함
인코딩하면 문자열로 된 열들이 숫자로 바뀐다!
셈플링
sampled_df = df.sample(n=5, random_state=0)
sampled_df5개 선별해서 random_state=0으로 했다. 42로 보통 많이 한다고 하는데 그냥 0으로 한번 해봤다...
일요일에 간단한 과제를 하나 수행했다. 문제를 직접 보면서 하나하나 해보니 그냥 정보들을 우겨넣는 것보다 남는게 확실하게 있었다ㅜㅡ. 내일 되면 잊을지 모르겠지만 ㅎㅎ
내일은 아마 팀과제 발제하는 날이다. 팀과제가 궁금하긴 하다. 흥미로운 주제를 받아 즐겁게 했으면 좋겠다 ^^;
