1. 3차 프로젝트
텍스트 데이터에 대해 검색 엔진 모듈, 분류 및 군집화 모델 구현을 목적으로 한다. 3차 프로젝트는 문서 검색 엔진과 문서 분류 및 군집화로 이루어져 있다.
2. IR model
IR model(information retrieval model)은 말 그대로 정보 검색 모델이다. 이용자의 정보요구에 적합한 정보, 지식을 찾아내 결과를 반환하는 역할을 수행한다. 주로 text document를 다루며 웹 검색 엔진은 가장 쉽게 접할 수 있는 IR model 중 하나이다.
가장 널리 알려진 IR model의 종류에는 다음의 3가지가 있다.
1) 불리언 모델
사용자가 AND, OR, NOT의 연산자를 사용하여 키워드를 조합한 식에 대하여 식을 만족하는 문서만을 검색해주는 모델이다.
query는 용어의 boolean logic으로 표현되고, 문서는 용어들의 집합으로 간주한다. query 내 용어들의 대상 문서내 포함 관계에 따라 문서의 검색 결과내 반영 여부가 결정된다.
예를 들어 query로 information and not theory를 준다면 information이 포함된 모든 문서 중에 theory가 포함되어 있지 않은 것들만 결과로 보여준다.
구현하기 쉽고 질의 처리가 매우 효과적이라는 장점이 있지만, 검색어의 상대적인 중요도를 나타낼 수 없고 정확하게 일치하지는 않지만 적합한 문헌을 검색하지 못한다는 단점이 있다.
2) 벡터 모델
불리언 모델의 단점을 보완하는 모델. 검색되는 문서가 반드시 query의 단어와 일치하지 않아도 둘 사이의 유사도를 계산하여 가장 유사한 문헌부터 순위를 결정할 수 있는 모델이다.
용어들의 집합인 query와 문서를 벡터공간에 표현할 수 있다는 아이디어로 시작한다. 각각의 차원은 개별 단어로 한다. 문서 내에 특정 단어가 포함되어 있다면, 벡터 내에서 해당 차원은 0이 아닌 값을 갖게 하는 방식이다. 정확히 값을 계산하는 방식에는 여러 방법이 존재하며 그 중 가장 유명한 것은 tf-idf 방식이다.
벡터 모델의 장점으로는 문서의 검색 순위가 결정된다는 것 한계점으로는 검색 키워드는 문서내의 단어와 정확히 일치해야 한다는 것 단어가 나타나는 순서에 관한 정보가 활용되지 못한다는 것 등이 있다.
3) 확률 모델
Query가 들어오면 그 query에 대해 각 문서가 적합할 확률과 부적합한 확률을 산출하고 적합할 확률이 부적합한 확률보다 큰 문서를 결과로 보여준다는 것이 기본 아이디어이다.
과제는 그 중 성능이 굉장히 좋다고 알려진 BM25 모델을 활용한다.
2. 문서 검색 엔진
주어진 질의어와 관련이 높은 순서대로 문서들을 나열하는 검색 엔진 모듈을 python의 whoosh 라이브러리를 사용하여 구현하는 것이 목표였다.
사용 데이터는 Cranfield 데이터셋으로 1400개의 document, 225개의 query(검색어) 그리고 각 질의어의 실제 연관 문서가 명시된 정답 파일이 있다.
이번 프로젝트는 사실상 전처리 싸움이었다. document는 tokenization, stemming, stopwords처리를 해주어야 했고, query에 대해서는 stemming, stopwords 처리를 해주었다. stemming을 할 것인지 lemmatizing을 할 것인지 결정하기 위해 수도 없이 많이 모델을 돌려보며 score가 더 높은 과정을 선택하였다. 쿼리에 대해서는 추가로 pos_tag처리 한 후 어떤 품사에 대해 더 높은 가중치를 줄지 결정하였다. 이 과정이 제일 힘들었다. 강의에서는 search engine의 기본적인 원리만 배웠는데, 도저히 어떤 품사에 대해 높은 가중치를 주어야 하는지 배경이 없으니 그저 아무 숫자나 넣어보면서 높은 정확도를 나타내는 쪽으로 값을 계속 변경해주었던 것 같다. 시간 여유가 있었더라면 논문도 찾아보고 기존 모델에서는 어떤 값을 넣는 것이 가장 보편적인지 찾아보았을 것 같은데, 당시는 이런 생각도 하지 못했고 그저 높은 정확도가 나오도록 최대한 많은 숫자를 넣어보는 전략을 택했다.
custom scoring 함수는 기본적으로 BM 25 함수가 주어졌지만 함수 코드를 잘 살펴본 결과 IDF가 원래 정의와 약간 다르게 설정되어 있는 것을 알 수 있었고, 조사를 한 결과 같은 BM25함수여도, IDF가 어떻게 정의되었는지에 따라 함수가 달라질 수 있음을 확인할 수 있었다. 그래서, "Improvements to BM25 and language models examined." (Trotman 등 4명) 논문을 참조하여, 다양한 IDF 정의 방법과 이에 따른 결과를 확인하였고, BM 25외에도 다양한 함수들에 대해서 도 결과를 확인해보았다. 그 결과, TFl◦d◦p◦IDF함수를 적용하였을 때, 가장 좋은 값을 가짐을 확인할 수 있었다.
def intappscorer(tf, idf, cf, qf, dc, fl, avgfl, param):
# tf - term frequency in the current document
# idf - inverse document frequency
# cf - term frequency in the collection
# qf - term frequency in the query
# dc - doc count
# fl - field length in the current document
# avgfl - average field length across documents in collection
# param - free parameter
# TODO - Define your own scoring function
K1 = 1.5
B = 0.75
return idf * (1 + log(1 + log((tf * (K1 + 1)) / (tf + K1 * ((1 - B) + B * fl / avgfl)))))평가 방법은 다음과 같다.
- 225개의 질의어 중 임의로 정해진 37개의 test 질의어에 대한 검색 성능 평가
- 평가 지표로는 BPREF 사용
평균 BPREF값은 0.34591685109715153로 나왔다.
3. 문서 분류
The New York Times의 영어 신문 기사를 분류, 군집화하는 모델을 python의 sklearn 라이브러리를 사용하여 구현하는 것이 목표였다.
주어진 데이터 셋에 대한 정보는 다음과 같다.
- opinion, business, world, us, arts, sports, books, movies 총 8개의 카테고리
- 각 카테고리마다 약 300개의 기사 데이터 제공
- text 폴더 내부에 train/test 폴더 구분, 각 폴더 내에 8개의 카테고리를 이름으로 하는 폴 더 내에 텍스트 파일로 존재
- test폴더에는 각 카테고리별 가장 최근 날짜의 기사 약 5개 정도만 존재
이를 Naïve Bayes Classifier와 SVM 두가지로 문서를 분류해보았다.
1) Naïve Bayes Classifier
먼저, 가장 좋은 Naïve Bayes Classifier를 찾으려 했다. 수업시간에 배운 GaussianNb, MultinomialNb, BernoulliNb 중, 어느 것이 가장 좋은 정확도가 나오는지 확인해보았다.
# TODO - 2-1-1. Build pipeline for Naive Bayes Classifier
clf_nb = Pipeline([
('vect', CountVectorizer(stop_words = 'english', min_df = 3, max_df=0.5, max_features=10000)),
('tfidf', TfidfTransformer()),
('clf', MultinomialNB())
])
clf_nb.fit(train_data.data, train_data.target)
이를 통해, MultinomialNB가 가장 좋은 결과를 보여줌을 확인할 수 있었다. 다음으로는 적절한 min_df(최소 문서빈도수), max_df(최대 문서빈도수), max_features(최대 단어수)를 찾기 위해 노력하였다. 최소 문서빈도수를 1이라 설정하면, overfitting이 발생할 가능성이 높기 때문에, 적절한 값을 찾기 위해 노력하였고 그 결과 3일 때가 좋은 accuracy값을 가지는 것을 확인할 수 있었다. 다음으로는 max_df이다. 너무 문서빈도수가 높으면 이것은, 의미없는 feature일 확률이 크기 때문에 적절한 max_df를 설정할 필요가 있었다. 그 결과 0.5, 즉 절반 이하로 나타난 feature에 대해, 좋은 accuracy값을 가짐을 확인할 수 있었다. 마지막으로, max_feature값이다. 너무 큰 max_feature값을 설정하면, 이 또한 overfitting이 나타날 확률이 크고 그래서 적절한 값을 찾아야했다. 그 결과 10000이란 max_feature값을 가질 때 최고의 accuracy를 가짐을 확인할 수 있었다.
2) SVM
SVM은 분류를 하는 Decision Boundary를 결정할 떄, 어느정도의 error를 허용한 채, 각 분포의 margin을 최대화하는 기법을 말한다. SVM의 방법에는 크게 3가지SVC와 NuSVC와 LinearSVC가 있다.
Naïve Bayes Classifier와 마찬가지로 predict함수를 이용해 분류를 진행 하고 그 결과를 확인하였을 때는 다음과 같았다.

각 분류 방법에 따른 정확도는 모두 같았다. 따라서, SVC를 기준으로 여러 변 수들의 값을 변경하여 정확도를 높이기 위해 노력했다.
먼저, max_df값을 극적으로 변화시켰다. 0.1로 max_df값을 변경하여, 10번중 에 1번 이상 나오는 feature들은 고려하지 않기로 하였다. n_gram의 범위는 (1,2) 를 설정하였다. (1,1)로 하였을 때가 결과가 더 잘 나오기는 했지만, 이는 근사의 정도가 현실의 확률분포와 멀어지기 때문에 채택하지는 않았다.
오류를 어느정도 허용할지 결정하는 C값으로는 0.95를 채택했다. 어느 정도의 오류를 허용함으로서 overfitting이 되는 것을 막기 위함이었다. kernal은 ‘rdf’를 유지하고, gamma값을 설정하였다. Gamma값을 너무 낮추면 underfitting을, 너무 높으면 overfitting이 발생하기 때문에, 적절한 값인 1로 설정하였다.
4. 문서 군집화
영어 신문 기사 군집화를 하기 위해 K-means clustering을 진행한다.
검색 엔진과 유사하게 전처리를 해준다. (사실상 그냥 줄글로 되어있는 데이터를 학습시키기 위한 상태로 만들기 위해서는 필수적이다.) 평가 지표로는 homogeneity와 completeness의 조화 평균인 V-measure를 사용했다.
이때 clustered 된 자료를 v-measure scoring 하여 좋은 값을 얻기 위해 여러가지 parameter 값들을 변경하는 것이 핵심이었다. 여러 번의 시도 끝에, cluster의 수는 9 근처에서 가장 커지는 것을 알 수 있었고 init 값을 random으로 지정 하여 cluster의 초기 위치를 random 하게 지정해주는 것이 좋은 v-measure 결과를 반환함을 알 수 있었다.
n_init값을 지정하기 위해서 SSE와 n_cluster를 축으로 가지는 elbow method를 이용하기 위해 n값만 1부터 20까지 반복문을 통해 바꿔가면서 각각의 군집 수에 따른 SSE 값 을 계산하여 그래프화하였다.
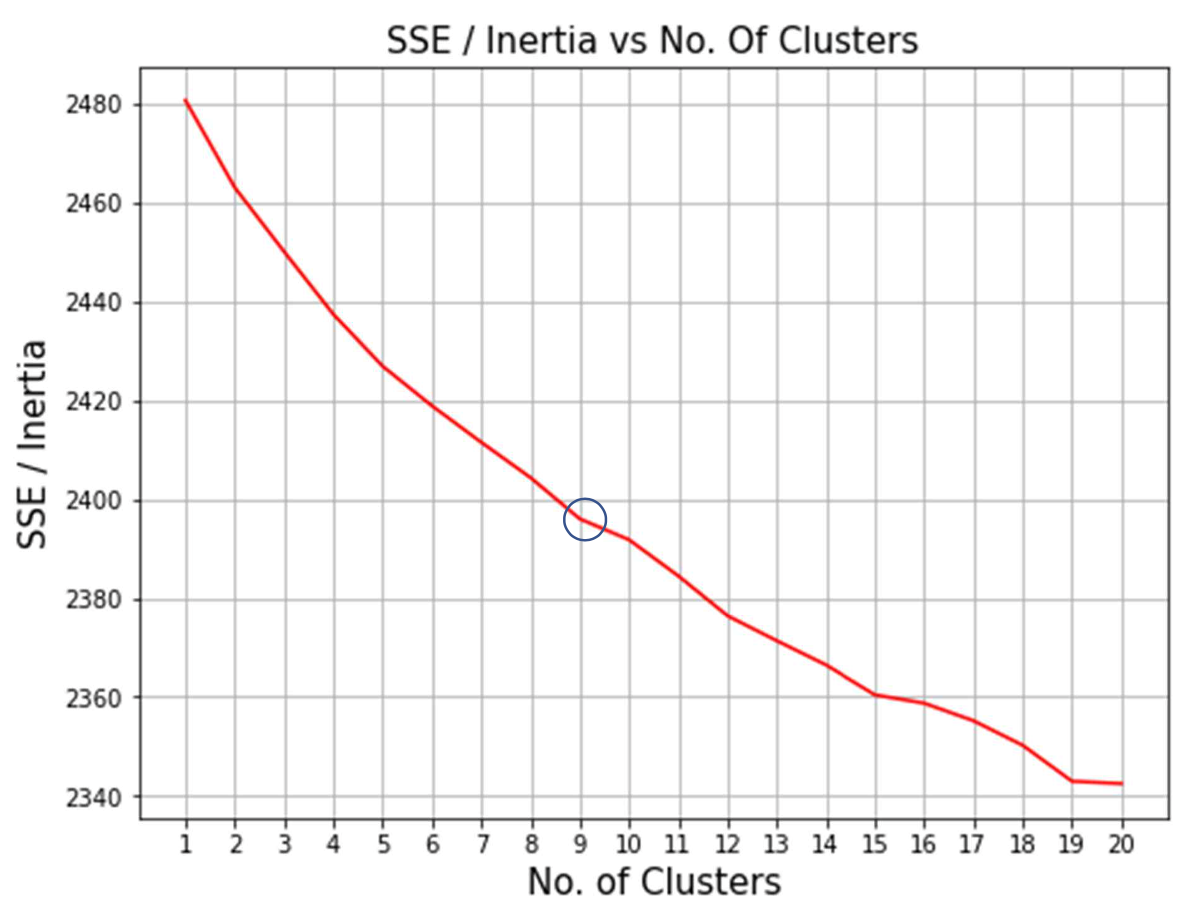
n=9에서 그래프가 elbow point 를 가지는 것을 알 수 있었다. 따라서 반복문을 통해 구한 V-measure 값의 최고점이 n=9 에서 나 타나는 것에 대해 확신을 가질 수 있었다.
기존 라벨링 되어 있는 카테고리와 이렇게 clustering한 결과를 비교하기 위해서 PCA를 진행하였고 결과는 다음과 같았다.
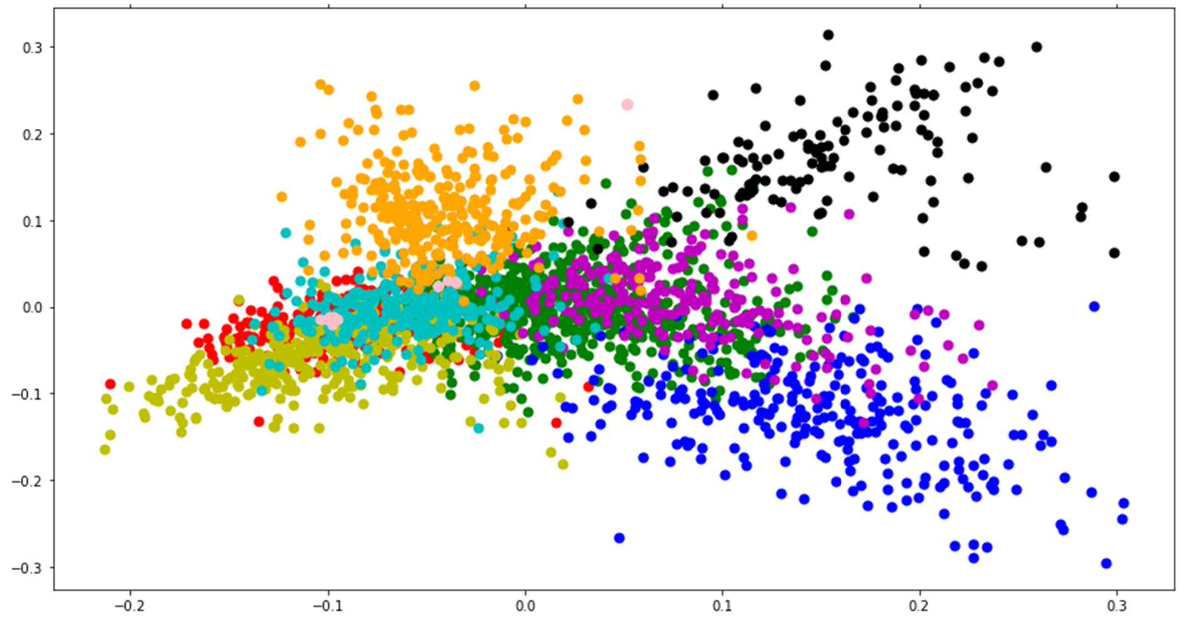
기존 카테고리
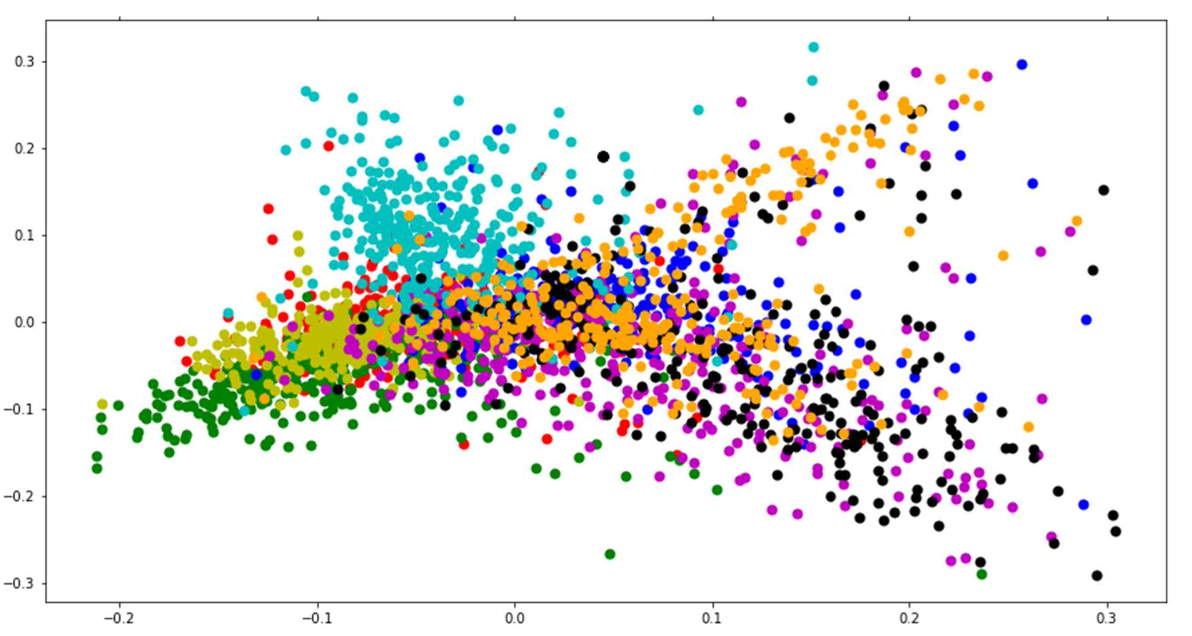
clustering(군집화) 결과
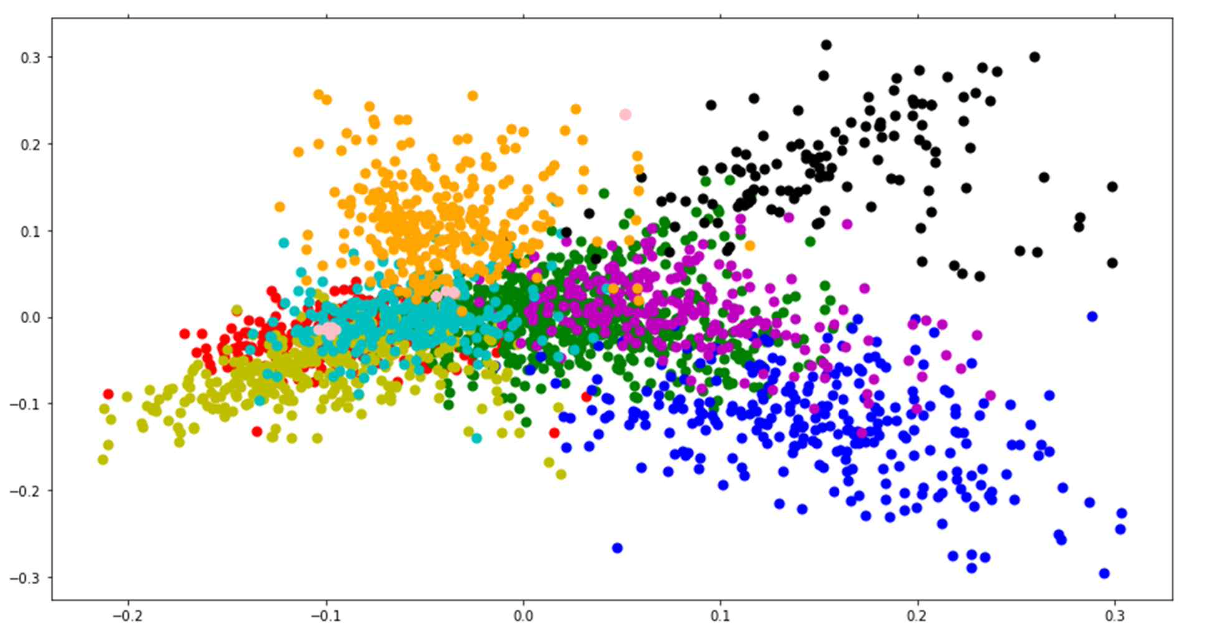
Visualization 이미지를 분석해본 결과, 우선 기존에 주어진 category로 군집화 했을 때는 문서들이 비교적 규칙적이지 않게 분포되어 있는 것을 볼 수 있다. 그러나 K-mean clustering을 진행한 후에는 문서들이 잘 군집화 되어있는 것을 확인할 수 있었다.
5. 3차 프로젝트 마무리
개인적으로 가장 힘든 프로젝트였다. 자유도가 높았고, 어떤 방법을 써서든 우리에게 주어지지 않은 채점 test set을 가장 잘 맞출 수 있는 모델을 제출하면 되었기 때문에 어디가 맞는 방향인지도 모르면서 계속 돌려보기만 하는 상황이 연출되었다. 프로젝트 결과도 우리에게 주어진 test set은 가장 잘 맞추는 모델을 내놓았지만, 주어지지 않은 채점 test set에 대해서는 중위권의 결과가 나와 낙담했다.
