tf-idf란 단어의 중요도를 계산하는 가장 대표적인 기법이다. tf-idf에 대해 이야기하기 전에 DTM(Document Term Matrix)이 뭔지 알아보자.
1.DTM
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
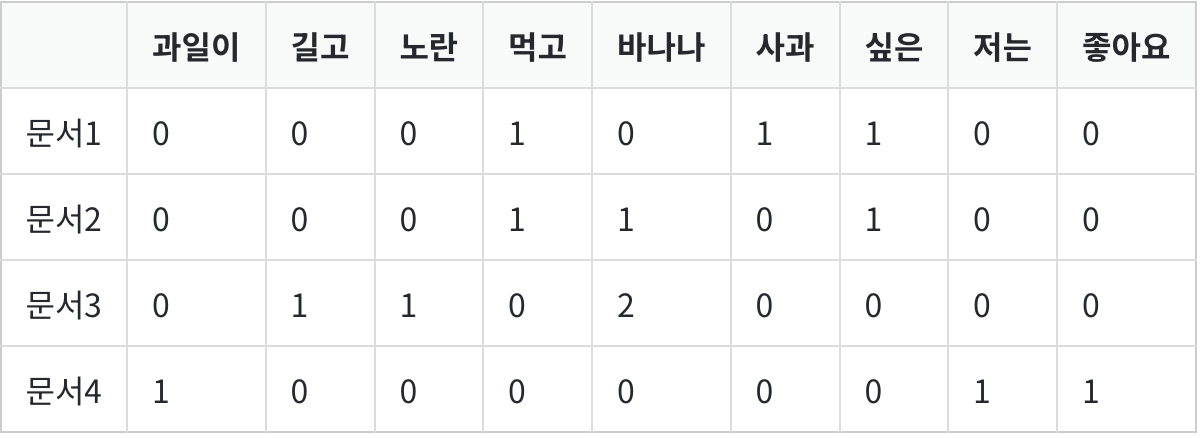
각 문서에서 등장한 단어의 빈도를 행렬의 값으로 표기한 것이다. 다음과 같은 문서 4개가 있다고 가정하자.
문서1 : 먹고 싶은 사과
문서2 : 먹고 싶은 바나나
문서3 : 길고 노란 바나나 바나나
문서4 : 저는 과일이 좋아요
띄어쓰기 단위로 토큰화를 수행하면 DTM은 다음과 같이 표현된다. (column에는 문서에 포함한 모든 단어를 적고 row에는 문서를 적는다. cell에는 row에 해당하는 문서에 column에 있는 단어가 몇번 등장하는지 적는다. 매우 직관적이다.)
DTM의 한계
1) 희소 표현
문서가 매우 많다고 생각해보자. DTM의 column 개수는 문서 전체에 등장하는 단어 집합의 크기를 갖게 된다. 또 문서 전체 집합이 커질수록 각 문서에 등장하는 단어의 비율은 줄어드니 대부분의 cell이 0의 값을 갖게 된다.
2) 단순 빈도 수에 의존
중요한 단어와 불필요한 단어를 구분하지 못한다. 단순 빈도수가 높더라도 중요한 의미를 갖지 않는 단어들이 많다.
그렇다면 중요한 단어에 가중치를 줄 수 있는 방법은 없을까??
2. TF-IDF
간단하게 설명하면 TF와 IDF를 곱한 값이다.
tf(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를
나타내는 값이다. 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다. 하지만 어떤 단어가 다른 문서에서도 많이 등장한다면?(the 같은 어떤 문장에서도 자주 등장하는 단어를 생각해보자.) 그 단어의 중요도는 낮을 수 밖에 없다. 그렇다면 특정 단어가 등장한 문서의 수가 많으면 작아지는 값을 정의해서 tf에 곱한다면 적당한 중요도를 표현할 수 있지 않을까 생각해볼 수 있다. 그 역할을 하는 값이 idf이다.
tf (Term Frequency)
tf(d,t) = 특정 문서 d에서의 특정 단어 t의 등장 횟수.
이 값을 전에 이미 구한적이 있다. 바로 DTM의 cell의 값이다.
df (Document Frequency)
df(t,D) = 특정 단어 t가 등장한 문서의 수
D는 문서 전체를 의미한다.
DTM에서 특정 단어 t가 위치한 column을 살펴보자. 0이 아닌 값들의 개수는 이 단어가 등장한 문서의 개수가 될 것이다. 이 값이 df(t)이다. 주의할 점은 0이 아닌 값들을 더한 것이 아니다. 0이 아닌 값의 개수이다.
idf(df(t)가 증가하면 작아지는 수)
n은 문서의 총 개수를 의미한다.
책마다 분모 부분을 가 아닌 로 표현한 경우도 있는 것으로 보인다. 가 0이 되는 경우를 막기 위한 것으로 보인다. (사실 df(t)가 0이라면 어느 문서에도 등장하지 않는 단어라는 의미인데 이런 단어가 굳이 DTM에 존재할 필요가 없다. 어떤 단어가 문서에 없을 때 DTM에서 즉시 제거할지 남겨둘지 원칙에 따라 달라질 것으로 보인다.)
log를 씌워주는 이유는 n이 큰 수라면 df가 작은 단어에 대해 엄청난 가중치가 부여되기 때문이다.
tf-idf
