📒 다중 선형 회귀
복수의 정보가 존재할 때 어떻게 하나의 추측값을 계산할 수 있을까?
📝 Dummy Data
| Quiz 1 (x1) | Quiz 2 (x2) | Quiz 3 (x3) | Final (y) |
|---|---|---|---|
| 73 | 80 | 75 | 152 |
| 93 | 88 | 93 | 185 |
| 89 | 91 | 80 | 180 |
| 96 | 98 | 100 | 196 |
| 73 | 66 | 70 | 142 |
x_train = torch.FloatTensor([73, 80, 75],
[93, 98, 93],
[98, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])📝 Hypothesis
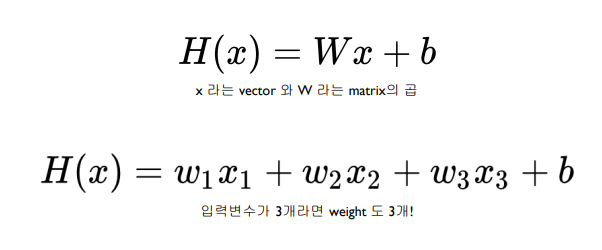
hypothesis = x_train @ W + b📝 Cost function
- 기존 Simple Linear Regression과 동일한 공식이다.
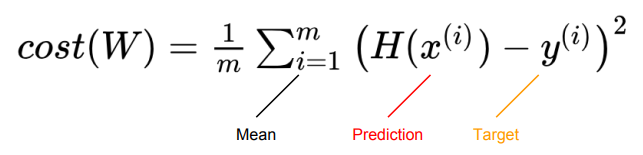
cost = torch.mean((hypothesis - y_train) **2)📝 Gradient Descent
- 역시 기존 선형 회귀와 동일하다.
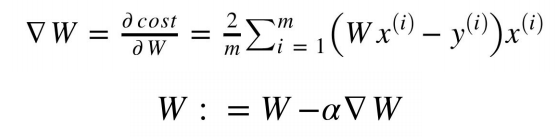
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1e-5)
# optimizer 사용법
optimizer.zero_grad()
cost.backward()
optimizer.step()📝 nn.Module
- W를 쓰는 것은 모델이 커질수록 귀찮은 일이 된다.
- nn.Module을 모델 Class에 상속해서 쓰면 더 쉽게 모델링이 가능하다.
- F.mse_loss 등 cost function도 다양하게 제공하고 있다.
import torch
class MLR(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 입력 차원, 출력 차원
def forward(self, x):
return self.linear(x)
# 모델 초기화 (W, b 선언이 필요 없어졌다.)
model = MLR()
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1e-5)
np_ephchs = 20
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()📒 Loading Data
엄청난 양의 데이터를 한번에 학습시키기는 힘들다.
일부분의 데이터로만 학습시켜보자.
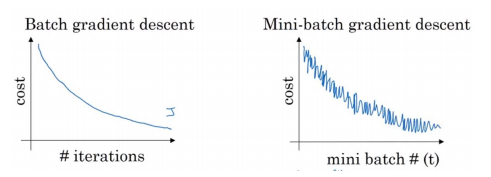
📝 Minibatch
- 전체 데이터를 균일하게 나눠서 학습하는 방법
- 각 Minibatch에 있는 data의 cost만 계산한다.
- 업데이트 주기가 더 빨라지지만, 잘못된 방향으로 학습할 수도 있다.
📝 Dataset and DataLoader
- Dataset을 상속하여 원하는 dataset을 지정할 수 있다.
👉 init, len, getitem 3개의 magic method를 반드시 정의해야 한다. - DataLoader를 사용하여 minibatch data를 핸들링할 수 있다.
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
# 데이터셋의 총 데이터 수
def __len__(self):
return len(self.x_data)
# 어떠한 인덱스를 받았을 때, 그에 상응하는 입출력 데이터 반환
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = CustomDataset()
dataloader = DataLoader(
dataset,
batch_size=2, # 각 minibatch의 크기로 통상적으로 2의 제곱수로 설정
shuffle=True # Epoch 마다 데이터셋을 섞어서 학습되는 순서를 바꾼다.
)
Beginner