[Paper Review] An Unsupervised Neural Attention Model for Aspect Extraction

Ruidan He, Wee Sun Lee, Hwee Tou Ng, Daniel Dahlmeier. 2017. An Unsupervised Neural Attention Model for Aspect Extraction. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
1. Introduction
sentiment analysis의 주요 과제 중 하나인 aspect extraction은 문장 내에서 토픽의 역할을 하는 aspect term을 추출하는 것을 목표로 한다.
aspect extraction은 2개의 sub-task로 이루어진다. 먼저 리뷰 문서 내의 모든 aspect term을 추출한다. 그리고 비슷한 의미를 가진 aspect term들을 하나의 aspect로 군집화한다. 예를 들어, "The beef was tender and melted in my mouth."라는 문장에서 aspect term을 추출하자면 "beef"가 될 것이다. 그리고 이렇게 리뷰 문서의 문장들로부터 "beef", "pasta", "pork"와 같은 토픽 단어들을 추출해내면 "food"라는 aspect로 군집화할 수 있다.
기존에는 rule-based, supervised, unsupervised 3가지 종류의 aspect extraction 방식이 있었다. 그러나 rule-based 방식은 추출한 aspect term들을 군집화하지 못한다는 단점이 있었고, supervised 방식은 데이터에 대한 labeling이 필요하다는 점과 새로운 데이터를 잘 분류하지 못한다는 문제가 있었다. 그래서 Latent Dirichlet Allocation(LDA) 모델처럼 labeled 데이터가 필요하지 않은 unsupervised 방식이 널리 사용되었다. 하지만 LDA 모델 또한 자주 함께 나오는 단어들에 대한 정보를 담지 못하고 길이가 짧은 리뷰 문서에서 aspect 분포를 추정하기가 어렵다는 단점이 존재했다.
이러한 LDA 모델의 단점을 보완하기 위해 본 논문에서는 Attention-based Aspect Extraction(이하 ABAE) 모델을 제안한다. attention mechanism은 어느 aspect에도 포함되지 않는 단어들에 대한 가중치를 줄여 모델이 aspect 관련 단어들에만 집중할 수 있도록 도와준다.
2. Model Description
ABAE의 궁극적인 목적은 aspect embedding을 학습하는 것이다. ABAE 모델을 통해 어떤 embedding 값이 주어졌을 때 동일한 선형 공간 상에서 aspect와 가까운 단어들을 찾을 수 있고, 해당 aspect가 의미하는 바를 쉽게 해석할 수 있다.
ABAE의 구조를 그림으로 도식화하면 아래와 같다.
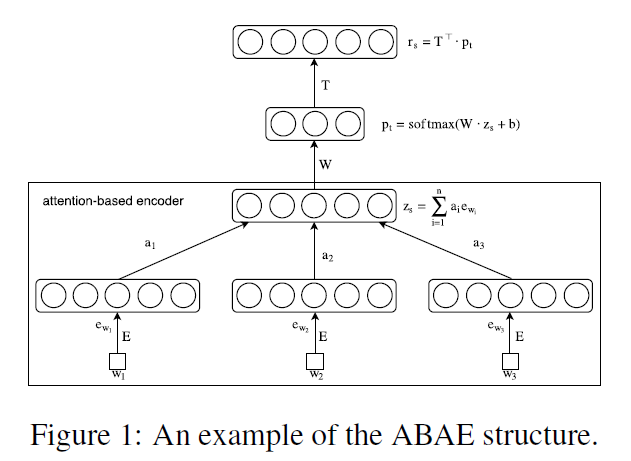
ABAE의 input으로 리뷰 문장의 단어 index 리스트가 들어오면 먼저 attention mechanism을 통해 aspect와 관련이 없는 단어들을 필터링한다. 그리고 이렇게 필터링된 word embedding으로부터 sentence embedding 를 만든다. 그 후 aspect와 단어가 같은 embedding 공간에 있도록 하기 위해 aspect embedding 행렬 를 이용해 sentence embedding을 aspect embedding의 선형 결합으로 reconstruct한다.
2.1 Sentence Embedding with Attention Mechanism
sentence embedding 단계에서는 attention mechanism을 이용하여 input sentence 에 대해 벡터 를 만든다. 이때 만들어진 벡터 가 문장의 aspect에 대한 정보를 최대한 많이 담을 수 있도록 해야 한다.
attention mechanism은 다음과 같은 순서로 수행된다. 먼저 input sentence의 단어 를 특성 벡터 에 mapping 시킨다. 특성 벡터로는 pre-trained된 word embedding을 사용하는데, 이는 자주 함께 등장하는 단어를 embedding 공간에서 가깝게 mapping 시키는 word embedding의 성질을 활용하기 위함이다. 단어 집합의 크기를 라고 할 때 이 특성 벡터들을 행으로 쌓으면 word embedding 행렬 가 만들어진다.
그리고 모든 word embedding의 평균 를 구한다. 이때 는 문장의 전체적인 내용을 대변하는 하나의 벡터가 된다.
다음으로 와 word embedding 를 mapping 해주는 행렬 을 학습시킨다. 그리고 행렬 으로 단어들을 변환시켜 개의 aspect와 관련 있는 단어들만 필터링시킨다. 이렇게 필터링된 단어들을 와 내적하여 문장과 각 단어의 관련성을 계산하고, 로 나타낸다.
그리고 각각의 단어 가 문장의 토픽과 관련되어 있을 확률을 나타내는 가중치 를 아래와 같이 계산한다.
마지막으로 sentence embedding 를 word embedding 들의 가중치 합으로 정의한다.
2.2 Sentence Reconstruction with Aspect Embeddings
2.1의 과정을 거쳐 얻어진 sentence embedding에 대한 reconstruction 벡터를 구한다.
우선 개의 aspect embedding에 대한 가중치 벡터 를 계산한다. sentence embedding 의 차원을 에서 로 축소시키고 softmax 함수를 통과시키면 정규화된 가중치 벡터 를 얻어낼 수 있다.
식에서 와 는 각각 가중치 행렬과 편향 벡터로 training 과정에서 학습되는 파라미터이다. 이렇게 얻어진 벡터 의 요소들은 input 문장이 각 aspect에 속할 확률값이 된다.
그리고 aspect embedding 행렬 를 설정하여 개 aspect에 대한 aspect embedding을 학습한다.
최종적으로 reconstruction 는 행렬 에 의한 변환으로 얻어진 aspect embedding의 선형 결합으로 정의된다.
2.3 Training Objective
ABAE는 reconstruction 오차를 최소화하는 방향으로 훈련된다.
각각의 input 문장에 대하여, training data에서 무작위로 개의 문장을 뽑아 negative sample로 둔다. 그리고 이 negative sample들의 word embedding 값을 평균낸 벡터를 로 표현한다.
training을 통해 재구성된 embedding 는 target 문장의 embedding 와 비슷하고 negative sample들과는 차이가 있어야 한다. 따라서 objective function 는 와 의 내적값은 키우고 와 negative sample 간의 내적은 줄이는 방향의 hinge loss 형태가 된다.
식에서 는 training data를 의미하고 는 모델의 파라미터이다.
2.4 Regularization Term
논문에서는 리뷰 dataset을 가장 잘 대변하는 aspect에 대한 vector representation을 얻고자 한다. 하지만 aspect embedding 행렬 는 training 과정에서 불필요한 중복 문제를 겪을 수 있다. 따라서 aspect embedding의 다양성을 높이기 위해 아래 식과 같은 regularization 항을 추가한다.
여기서 는 항등 행렬이고, 은 의 각 행이 크기 1로 정규화된 행렬이다. 그리고 의 대각성분이 아닌 요소들은 서로 다른 aspect embedding을 내적한 값이다. 이 값들이 0이 될 때 는 최소가 된다. 따라서 regularization 항은 aspect embedding 행렬 의 행들이 서로 직교하도록 만들어주고, 서로 다른 aspect 벡터들 간의 중복을 줄이는 역할을 한다.
최종적인 objective function 은 앞서 정의한 와 를 합하여 만들어진다.
식에서 는 하이퍼파라미터로 regularization 항의 가중치를 조절하는 역할을 한다.
3. Experimental Setup
3.1 Datasets
1) Citysearch corpus
Citysearch New York의 레스토랑 리뷰 문서로, 50,000개 이상의 레스토랑 리뷰가 포함되어 있다. 선행연구에서 이 중 3,400개의 문장에 labeling을 해두어, 그 문장들을 모델의 aspect extraction 평가에 사용할 것이다. 'Food', 'Staff', 'Ambience', 'Price', 'Anecdotes', 'Miscellaneous' 6개의 aspect label이 존재한다.
2) BeerAdvocate
약 150만 개의 맥주 리뷰를 포함하고 있는 리뷰 문서이다. 그 중 1,000개의 리뷰, 9,245개의 문장이 5개의 aspect로 labeling 되어 있다. 5개의 aspect는 'Feel', 'Look', 'Smell', 'Taste', 'Overall'이다.
3.2 Baseline Methods
ABAE의 성능을 검증하고자 LocLDA, k-means, SAS, BTM 4가지의 비교 모델을 설정했다.
3.3 Experimental Settings
실험을 위해 ABAE의 word embedding 행렬 를 word2vec으로 학습된 word vector들로 초기화시켰다. embedding 크기는 200, window 크기는 10, negative sample 크기는 5로 두었다.
또한 k-means를 돌려 나온 cluster들의 중심으로 하여 aspect embedding 행렬 를 초기화했다. 나머지 파라미터들은 랜덤으로 초기화를 시켰다.
training 과정에서는 Adam optimizer를 이용해 word embedding 행렬 와 다른 파라미터들을 초기화시켰다. 학습률은 0.001로 두었고, epoch은 15개로, batch 크기는 50으로 설정했다.
이외에도 input 1개당 negative sample의 수를 20개로 정했고, orthogonality penalty weight 를 1로 두었다.
4. Evaluation and Results
4.1 Aspect Quality Evaluation
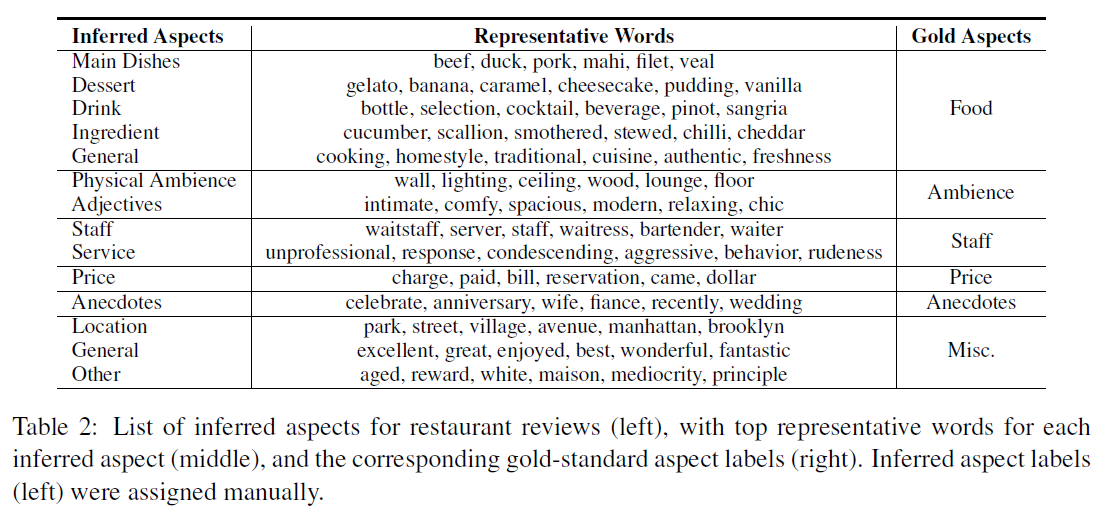
아래 표는 레스토랑 리뷰에 대해 ABAE가 추출해낸 14개의 aspect를 정리해둔 것이다. gold aspect에서 'food'로 분류한 것을 'main dish', 'dessert', 'drink' 등으로 분류한 것처럼 ABAE가 좀 더 세분화된 aspect를 찾아냈음을 알 수 있다.
1) Cohesive Score
모델의 성능을 수치적으로 나타내기 위해, coherence score를 지표로 사용했다. aspect 가 있고 와 가장 관련 있는 상위 개의 단어 집합 가 주어졌을 때, coherence score는 아래와 같이 계산된다.
는 단어 가 문서 내에서 나오는 빈도를 의미하고, 는 단어 과 가 문서에서 함께 나오는 빈도를 의미한다.
아래 그래프는 레스토랑과 맥주 리뷰 각각에 대해 모델들의 평균 coherence 값을 계산하여 나타낸 것이다.
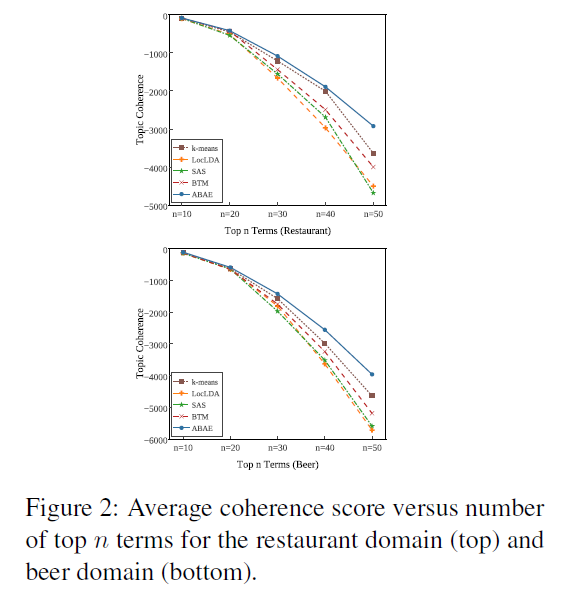
그래프를 살펴보면 ABAE가 다른 모델에 비해 높은 coherence 값을 가지고 있음을 확인할 수 있다. k-means의 성능이 ABAE만큼 뛰어난 것도 눈여겨볼 만하다.
2) User Evaluation
다음으로 ABAE가 찾아낸 aspect들이 실제로 사람이 판단했을 때 받아들일 만한지를 알아보고자 했다. 3명의 평가자가 판단하여 만약 상위 50개 단어가 일관성 있게 aspect를 나타낸다면 해당 aspect는 coherent 하다고 표현했다. 이 방식으로 레스토랑과 맥주 리뷰를 분석한 결과, 5개 모델 중 ABAE가 가장 많은 coherent aspect를 가지고 있었다.
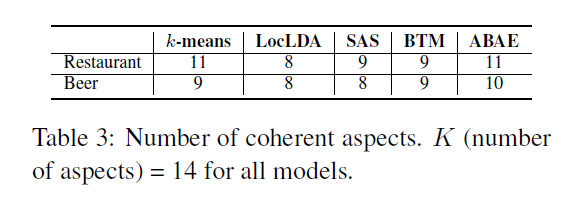
그리고 각각의 coherent aspect에 대해, 상위 개 단어를 뽑아 단어마다 해당 aspect를 잘 나타낸다고 판단되면 'correct'라는 label을 붙였다. 그리고 모델마다 precision을 계산하여 그래프로 나타냈다.
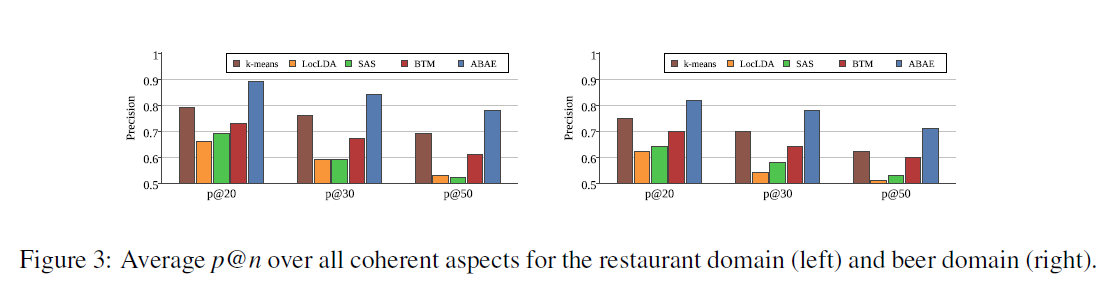
위 그래프를 살펴보면, ABAE의 precision이 타 모델에 비해 가장 높았고 그 차이는 이 커질수록 명확해지는 것을 알 수 있다.
4.2 Aspect Identification
이제 ABAE의 sentence-level aspect identification 성능을 평가하기 위해, 예측된 label이 실제 label과 얼마나 비슷한지 precision, recall, F1 score를 계산하여 분석해보았다. 레스토랑 리뷰의 경우 앞서 설정한 비교 모델 이외에 MaxEnt-LDA와 SERBM을 추가로 도입하여 비교했다.
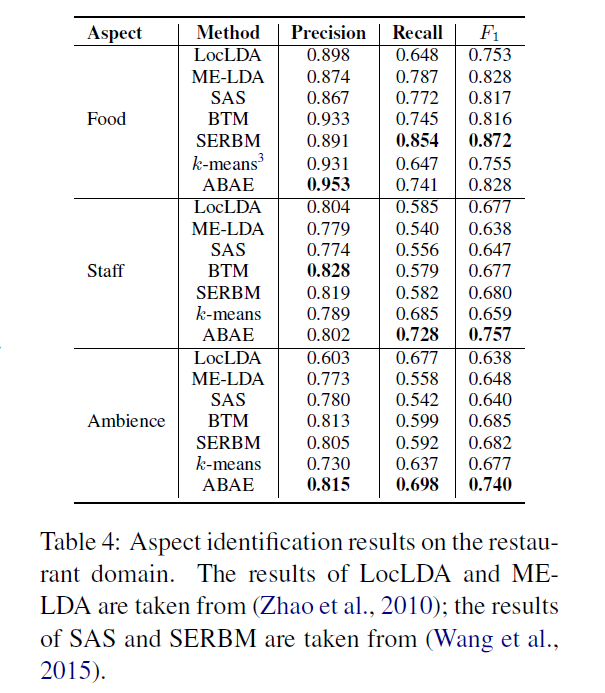
먼저 레스토랑 리뷰에 대한 결과를 표로 정리한 Table 4를 보면 ABAE가 'Staff'와 'Ambience' aspect에서 다른 모델보다 높은 F1 score를 가졌다. 하지만 'Food' aspect에서는 낮은 F1 score가 나타났다. 이것은 리뷰 문장에 구체적인 음식 메뉴가 나타나있지 않으면, 모델은 리뷰 문장을 'Food' aspect가 아닌 다른 aspect로 판단하는 경향이 있었기 때문이다.
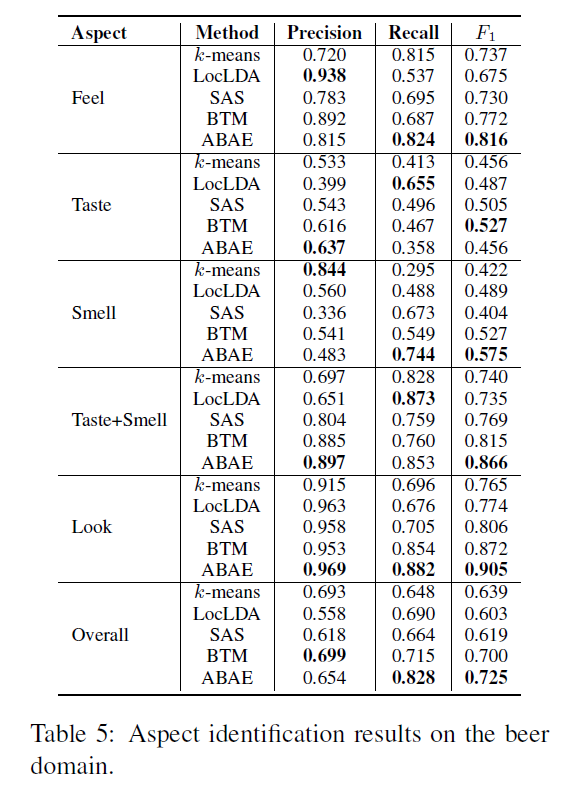
맥주 리뷰에 대한 precision, recall, F1 score를 나타낸 Table 5를 보면, 마찬가지로 ABAE가 대부분의 aspect에서 높은 F1 score를 가진다는 것을 확인할 수 있다.
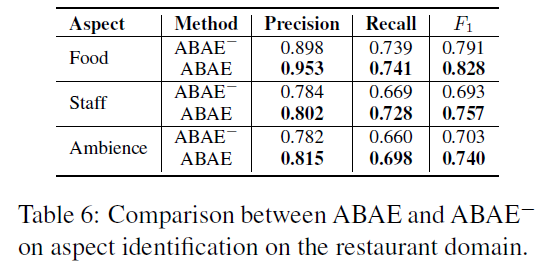
4.3 Validating the Effectiveness of Attention Model
마지막으로 attention layer의 중요성을 확인하기 위해 attention layer를 제거하고 word embedding의 평균값으로 sentence embedding을 계산한 ABAE 모델을 설정했다. 그리고 이를 ABAE와 비교하여 precision, recall, F1 score 값을 계산했을 때, attention layer가 있는 ABAE 모델의 성능이 훨씬 좋다는 것을 알 수 있었다.
처음 논문을 읽으면서 ABAE의 구조를 이해하는 데에 어려움이 좀 있었다. 이렇게 리뷰를 쓰면서 검색도 많이 해보고 논문을 계속 반복해서 읽게 되어 개념이 명확해지는 것 같다. 앞으로 논문 리딩과 글쓰기 실력 모두 발전하기를..!
