[Paper Review] CoRel: Seed-Guided Topical Taxonomy Construction by Concept Learning and Relation Transferring
Jiaxin Huang, Yiqing Xie, Yu Meng, Yunyi Zhang, Jiawei Han. 2020. CoRel: Seed-Guided Topical Taxonomy Construction by Concept Learning and Relation Transferring. Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
1. Introduction
Taxonomy는 커다란 corpus의 단어들을 계층 구조로 나타내어 각 단어 사이의 관계를 이해하기 쉽게 분류하는 체계를 말한다. 특히 본 논문에서는 seed-guided taxonomy라 하여, 사람이 먼저 제시한 seed taxonomy를 기반으로 text corpus로부터 더 완전한 topical taxonomy를 구축하는 task에 대한 연구를 진행하였다.
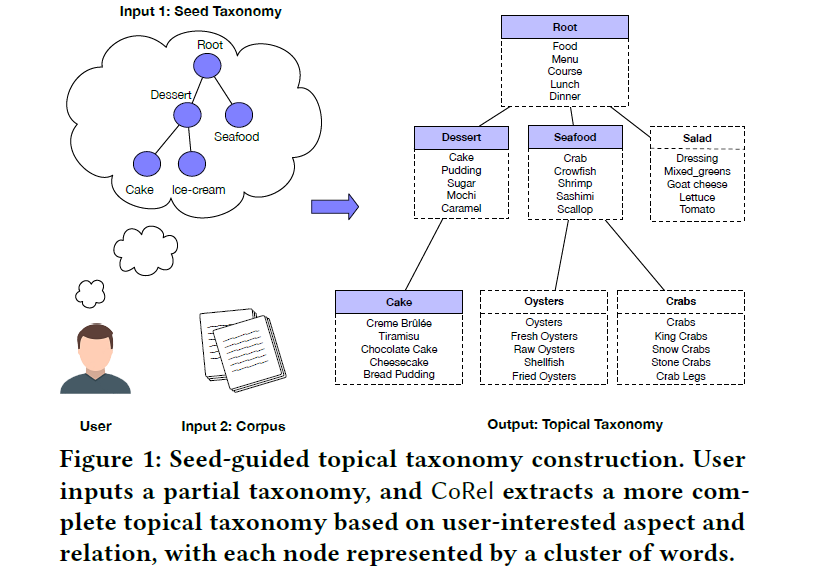
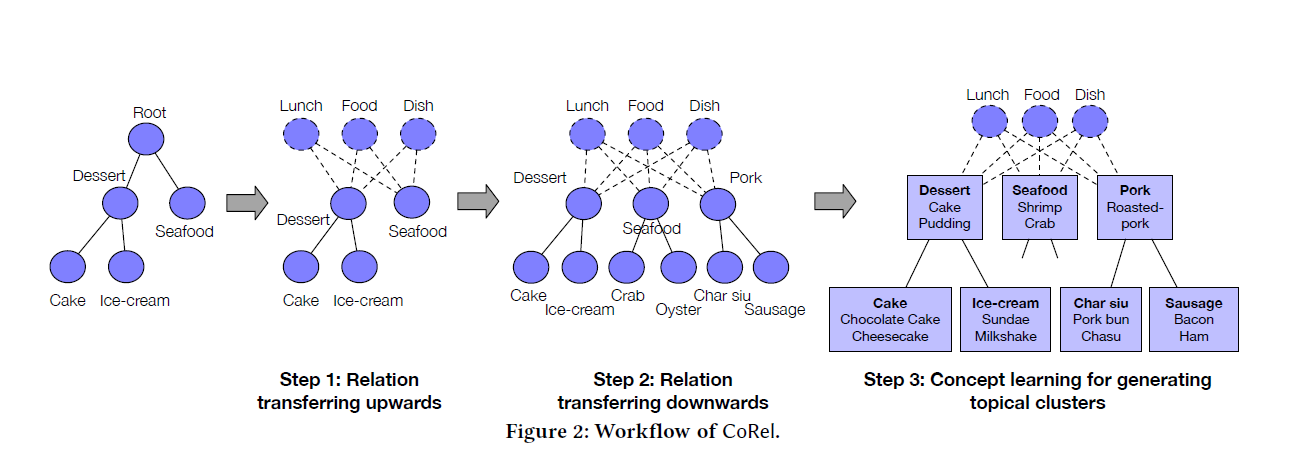
위 그림에서처럼 user가 만약 음식에 대한 seed taxonomy와 corpus를 모델의 input으로 대입하면 더 깊고 넓은 계층 구조를 가진 taxonomy가 output으로 출력된다. 이때 각 노드는 비슷한 단어들의 묶음으로 이루어지고 이들을 대표하는 하나의 단어가 노드의 conceptual topic이 된다.
task를 성공적으로 수행하기 위해 본 논문에서는 relation transferring module과 concept learning module로 이루어진 CoRel framework를 제시하였다.
2. Problem Description
CoRel은 input으로 문서들의 집합 와 seed taxonomy 를 받는다. 이때 의 각 노드 는 corpus에 있는 하나의 단어가 된다. 또 의 edge <, >는 user-interested parent-child pair를 의미하며, 특정 <, > pair를 포함하는 문장을 relation statement라고 정의한다. CoRel의 output은 더 complete한 버전의 topical taxonomy 가 되는데, 이때의 노드 는 cluster를 대표하는 conceptual topic이다.
3. Methodology
3.1 Method Overview
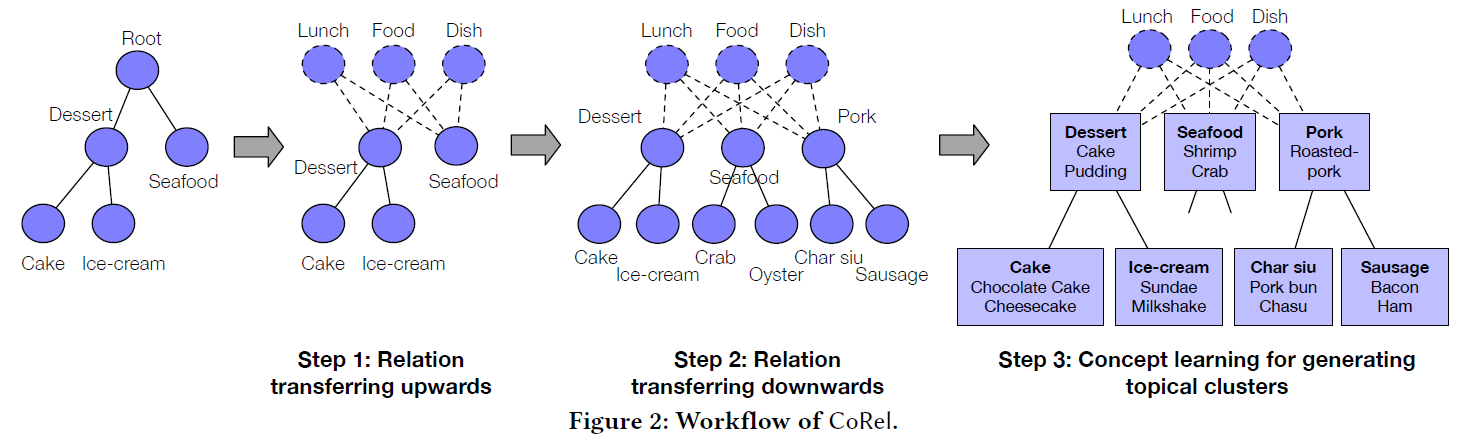
논문에서 제안된 CoRel은 task를 수행하기 위해 2가지 종류의 module을 이용한다.
먼저 relation transferring module로 seed taxonomy에 있는 <, > 사이의 relation을 학습한다. 그리고 학습한 relation을 위쪽 방향으로 전달해서 root가 될 만한 단어를 찾는다. 아래 예시에서 "Lunch", "Food", "Dish"와 같은 general한 단어들이 taxonomy의 root 역할을 한다. 이어서 relation을 아래 방향으로 전달해 계층 구조에 새로운 topic과 subtopic들을 붙인다.
마지막으로 concept learning module을 이용해서 discriminative embedding space를 학습하고 각 concept node에 대한 topical cluster를 만들어 낸다.
3.2 Taxonomy Completion by Relation Transferring
1) Self-supervised Relation Learning
relation transferring module에서는 BERT 모델을 사용해서 parent-child relation을 학습한다. user-interested relation을 학습하기 위해, seed taxonomy에서 주어진 <, >의 relation statement를 positive training sample로 두었다. negative sample로는 sibling node의 relation statement와 랜덤한 문장을 사용했다.
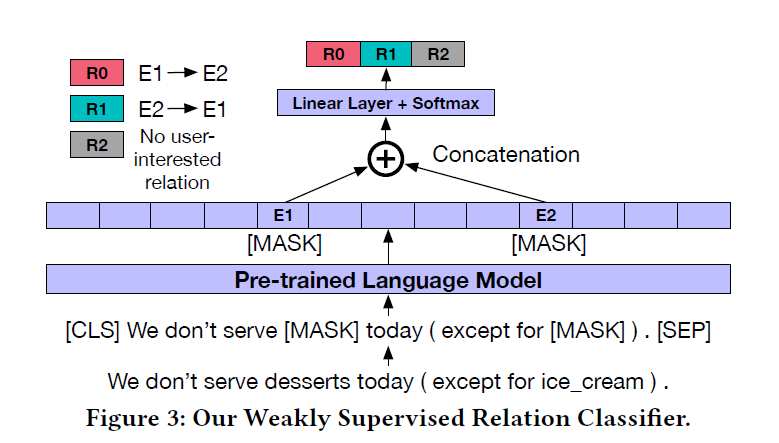
모델의 input으로 parent와 child 단어를 [MASK] 토큰으로 가린 문장이 들어가면, classification layer를 통과하며 3개의 클래스로 분류된다. [MASK] 토큰에 해당하는 단어를 과 라고 할 때 각각 이 의 parent node인지, 가 의 parent node인지, 또는 아무 관계가 없는지를 나타낸다. 이 훈련을 거치며 모델은 parent-child 사이의 relation을 학습하게 된다.
2) First-layer Topic Finding by Root Node Discovery
relation classifier를 얻은 후에는 taxonomy에서 target node를 정해서 그것의 parent node나 child node를 찾는다.
우선 root node를 찾기 위한 방법은 다음과 같다. 어떤 concept 와 그것의 parent가 될 수 있는 후보군 단어 가 있을 때, 가 의 parent가 될 확률을 KL divergence를 이용해 계산해준다. 그리고 이 확률이 threshold 값보다 크면 를 의 parent node로 지정한다.
사전에 주어진 seed taxonomy의 first-layer topic들에 대해 parent node가 되는 단어들을 각각 찾아 그 list를 만든다. 그리고 그 중 공통적으로 parent가 되는 node들을 taxonomy의 root node 로 지정한다.
first-layer의 새로운 topic 노드를 찾는 방법 역시 비슷하다. 위 식에서 , 자리에 , 를 대입해주면 가 의 child node가 될 확률을 계산할 수 있다. 그리고 모든 root node에 대해 를 계산하여 얻어진 평균을 기준으로 새로운 topic을 찾아낸다.
3) Candidate term extraction for subtopics
first-layer topic을 생성한 후에는 각 topic에 대한 subtopic들을 찾는다. 사실 subtopic을 곧바로 찾는 것은 아니고 subtopic이 될 수 있는 후보군들을 탐색한다. 이 경우 , 자리에 , 를 대입해주어 어떤 단어 가 topic node 의 child가 될 확률을 계산한다.
3.3 Generating Topical Clusters by Concept Learning
1) Concept Learning based on Taxonomy and Corpus
discriminative embedding space의 학습을 위해 3개의 loss function을 정의했다.
먼저 비슷한 단어들끼리는 비슷한 주변 단어를 공유한다는 가정 하에, window size가 인 local context에서 주변 단어가 등장할 확률을 최대화시키는 을 정의했다.
이어서 유사한 문서 내의 단어들은 비슷한 topic을 가진다는 점에서 단어가 어떤 문서 내에 들어있는지 예측하는 확률을 최대화시키는 loss fuction 를 정의했다. 식에서 는 document embedding을 말한다.
마지막으로 확장된 taxonomy에서 서로 다른 concept 사이의 구별을 명확히 하기 위해, 매 epoch마다 concept cluster 에 distinctive한 단어를 하나씩 추가했다. 그리고 concept embedding과 cluster 간의 유사도를 높이기 위해 loss function 를 정의했다.
이렇게 정의된 3가지 loss function의 가중치 합으로 최종 목적함수가 만들어졌고, concept learning이 진행되었다.
2) Topic and Relation aware Subtopic Finding
topical constraints와 relational constraints를 고려한 subtopic을 찾기 위해 co-clustering method를 이용한다.
먼저 아래와 같은 Topic-Type table을 만든다.

단어들은 semantic meaning에 따라 열별로 분리되고, semantic type에 따라 행별로 구분된다. 구체적으로, topic에 따른 clustering은 discriminative embedding space에서 affinity propagation clustering을 거쳐 만들어진다. 반면 type별 clustering은 average BERT embedding space에서의 affinity propagation clustering으로 만들어진다.
이 table을 변형해서 subtopic과 type에 따른 결합확률분포를 나타내는 indicative Topic-Type matrix를 만든다. 그리고 만들어진 indicative topic-type matrix 에서 co-clustering을 이용해 consistency score가 높은 subtopic들을 추출한다.
4. Experiments and Results
4.1 Experiment Setup
CoRel의 성능을 검증하기 위해 DBLP와 Yelp dataset을 사용했다.
DBLP는 컴퓨터 과학 내 여러 분야에서 쓰여진 논문들의 초록 데이터이다. AutoPhrase를 이용해 약 15만 개의 초록에서 의미 있는 단어들을 뽑았고, 16,650개의 단어를 추출했다.
Yelp는 108만 개의 레스토랑 리뷰 데이터를 가지고 있다. Yelp에서도 DBLP와 비슷한 방식으로 14,619개의 단어를 추출했다.
성능 비교를 위한 모델로는 Concept Learning을 결합한 Hi-Expan, TaxoGen, HLDA, HPAM를 두었다.
4.2 Qualitative Results
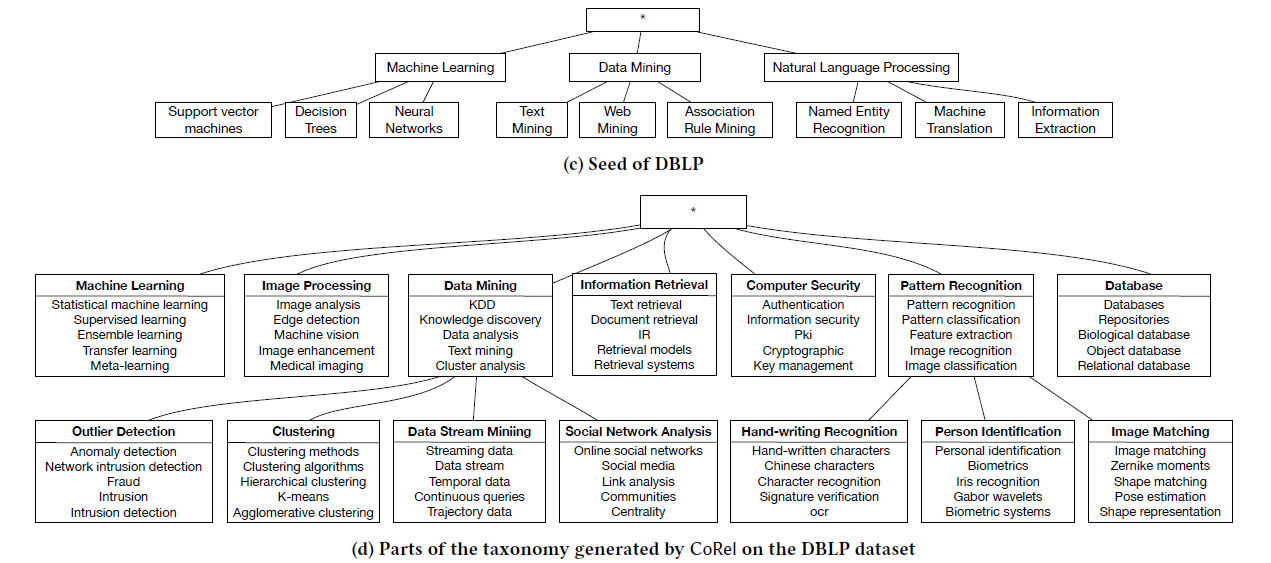
Yelp dataset으로 만든 topical taxonomy의 일부를 살펴보면, 최소한의 seed taxonomy가 주어졌을 때에도 output으로 완전한 topical taxonomy가 도출된 것을 확인할 수 있다. "soup", "pork", "beef"와 같은 음식들도 first-layer topic에 새로 추가되었다. 또 pork의 다양한 cooking style에 따라 명확히 구별되는 subtopic이 만들어졌다.

DBLP dataset의 결과도 성공적이다. input과 비교했을 때 훨씬 다양한 컴퓨터 과학의 분야가 taxonomy에 추가되었다.
relation learning module의 효과를 검증하기 위해 CoRel로 추출한 subtopic을 Hi-Expan으로부터 추출된 것과 비교해보았다. 아래 표에서 X로 표시된 것은 잘못된 subtopic 임을 나타내고, 가위 표시가 된 것은 중복된 단어이거나 기존 단어와 유의어 관계임을 나타낸다.

표에서 DBLP-Machine Learning의 예시를 보면 Hi-Expan은 "neural network"와 비슷한 개념들을 중복해서 추출해냈다는 것을 확인할 수 있다. "artificial neural networks"와 "multilayer perceptron"은 "neural network"의 sibling node가 아닌 cluster 내에 포함되어야 할 것이다. 반면에 CoRel에서는 그런 문제가 발생하지 않고 더 나은 성능을 보였다.
마지막으로 concept learning module이 cluster를 잘 만들어내는지 확인하기 위해 TaxoGen, HLDA, HPAM 모델과 비교했다.
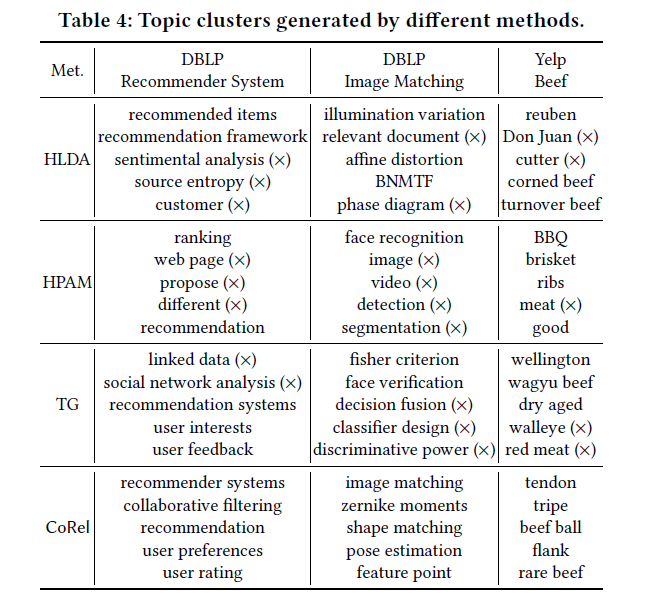
그 결과, 관련이 없는 단어나 교차되는 개념의 단어를 포함하고 있는 TaxoGen, HLDA, HPAM과는 달리 CoRel은 일관적이고 서로 구별되는 단어들을 잘 찾아내는 것을 확인했다.
기존에 읽었던 논문들에서는 aspect 수를 명확히 지정해주어야 하는 단점이 있었는데, CoRel에서는 seed taxonomy만 제공해주면 unsupervised 방식으로 단어들을 추출해내고 clustering 된다는 점이 인상적이었다. 아마 CVF 탐색 과제를 위해 CoRel을 사용하게 될 것 같은데, 내용을 잘 이해하고 있어야겠다🙂
