[Paper Review] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Google AI Language.
2018년 구글이 공개한 인공지능 언어 모델 BERT에 대한 논문이다. BERT는 등장과 동시에 자연어 처리(Natural Language Processing, 이하 NLP) 분야에서 획기적인 성능을 보여주었다.
1. Introduction
언어 모델을 사전 훈련시키는 것은 NLP task의 성능 향상에 효과적이라고 알려져 있다.
사전 훈련된 언어 모델이 작동하는 원리는 크게 2가지로 나뉜다. 먼저 특정 task에 특화된 네트워크 구조에 사전 훈련된 네트워크를 부가적인 feature로써 추가하는 방식이 있는데, 이를 feature-based 방식이라고 한다. 대표적으로는 ELMo가 있다. 반면에 모델의 범용성을 고려하여 모든 파라미터를 사전 훈련한 후 적용할 task의 종류에 따라 세부 조정하는 방식도 있는데, 이를 fine-tuning 방식이라고 한다. OpenAI GPT가 fine-tuning 모델의 대표적인 예시이다.
그러나 위 두 모델은 왼쪽에서 오른쪽으로, 또는 오른쪽에서 왼쪽으로 단방향 학습만 가능하다는 한계가 존재한다. 예를 들어, 'I like to ... soccer.'라는 문장의 빈칸을 채우는 문제에서 두 모델은 'I like to'에만 의존하여 빈칸에 들어갈 단어를 결정하고 오른쪽에 있는 'soccer'의 영향은 받지 않는다. 문맥을 이해하여 단어를 채우기 위해서는 빈칸 앞뒤 단어를 모두 고려하는 방식으로 훈련이 이루어져야 할 것이다.
따라서 저자들은 본 논문을 통해, 양방향에서 문맥을 이해하여 pre-train시키는 BERT(Bidirectional Encoder Representations from Transformers)를 제안한다.
2. BERT
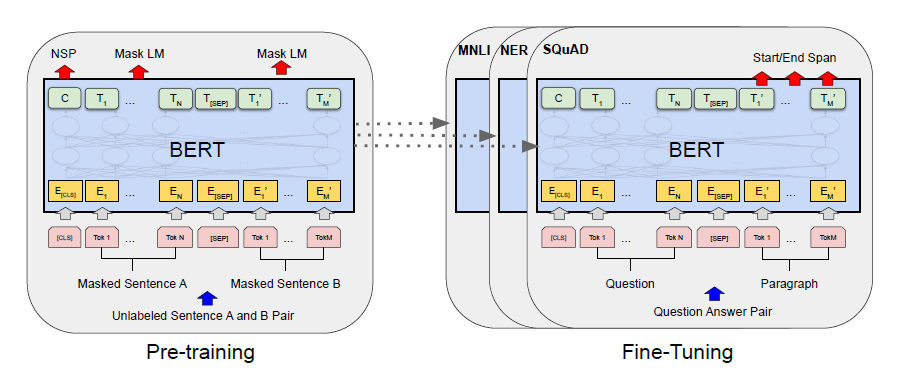
BERT는 pre-training과 fine-tuning의 두 개 step으로 나뉜다.
먼저 pre-training 과정에서는 MLM과 NSP task를 비지도 방식으로 훈련하게 된다. MLM과 NSP task의 자세한 내용은 아래 2.1에서 다루겠다. pre-training이 끝나면 fine-tuning 단계로 넘어가 pre-train을 통해 얻어진 parameter들을 모델의 초기 parameter로 대입하고, downstream task의 labeled data에 맞게 파라미터를 세부 조정한다.
BERT는 양방향 트랜스포머 인코더를 여러 층 쌓아올린 구조를 가지고 있다. 논문에서는 실험을 위해 BERT Base(L=12, H=768, A=12)와 BERT Large(L=24, H=1024, A=16) 2개의 모델을 설정했다. L은 트랜스포머 블록의 수, H는 hidden size, A는 self-attention head의 수이다. 이때 BERT Base는 GPT와의 성능 비교 목적으로 제작된 모델이다.
BERT를 다양한 종류의 task에 사용하기 위해, input의 형태를 단일 문장과 쌍으로 구성된 문장을 모두 나타낼 수 있는 형태로 만들었다. 이를 sequence라고 표현한다. 각 sequence의 첫 번째 token은 [CLS]라는 token인데, 이것은 분류 문제에서 sequence의 의미를 응축해서 나타내는 역할을 한다. 분류 문제가 아닌 경우에는 사용하지 않는 token이 된다. 그리고 input이 쌍으로 이루어진 문장일 경우 문장을 구분하기 위해 [SEP]라는 token을 사용한다.
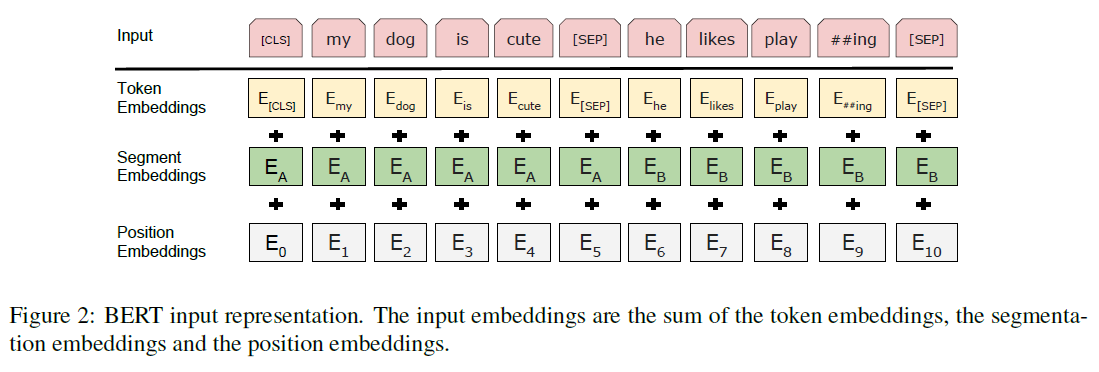
위 그림에서 볼 수 있듯이, BERT의 input은 token 임베딩과 segment 임베딩, position 임베딩을 더하여 만들어진다. 먼저 WordPiece 임베딩의 30,000개 vocabulary를 사용해 token을 임베딩한다. 그리고 segment 임베딩을 통해 문장 쌍이 input으로 들어왔을 때 각 문장을 구분한다. 마지막으로 position 임베딩에서 self-attention 모델이 token의 위치를 고려할 수 있도록 위치 정보를 담는다.
2.1 Pre-training BERT
BERT를 pre-train시키기 위해 사용한 두 개의 비지도 task를 소개한다.
Task #1: Masked Language Model(MLM)
MLM은 input token 중 일부를 가리고 가려진 token이 무엇인지를 예측하는 task이다.
논문에서는 각 sequence의 token 15%를 가리고 task를 수행했다. 이 15% token 중 80%는 [MASK] token으로 대체하고, 10%는 랜덤 token으로 대체했다. 그리고 나머지 10%는 가리지 않고 그대로 두었다. 이것은 fine-tuning 단계에서 [MASK] token이 나타나지 않기 때문에 pre-training과 fine-tuning 사이에 발생하는 불일치 문제를 해결하기 위한 방안이다.
MLM 예시
- 80%: my dog is hairy my dog is [MASK]
- 10%: my dog is hairy my dog is apple
- 10%: my dog is hairy my dog is hairy
이러한 MLM task를 수행하며 모델은 앞뒤 문맥을 파악할 수 있는 방향으로 훈련된다.
Task #2: Next Sentence Prediction(NSP)
NSP는 두 문장 A, B가 있을 때 A 다음에 B가 올 것인지의 여부를 예측하는 task이다.
이때 50%는 연결이 되는 문장 쌍(IsNext), 50%는 서로 관련이 없는 문장 쌍(NotNext)을 투입하여 훈련시킨다.
NSP 예시
- IsNext: [CLS] the man went to [MASK] store [SEP], he bought a gallon [MASK] milk [SEP]
- NotNext: [CLS] the man went to [MASK] store [SEP], penguin [MASK] are flight ##less birds [SEP]
NSP task를 통해 모델이 두 문장 사이의 관계를 이해하여 Question Answering(QA)이나 Natural Language Inference(NLI)와 같은 task를 수행할 수 있다.
2.2 Fine-tuning BERT
Fine-tuning에서는 사전 학습된 BERT 파라미터에 label이 있는 downstream task를 추가로 지도학습시켜 파라미터들을 미세 조정한다.
input으로는 단일 문장이 들어갈 수도 있고, Question-Answering처럼 문장 쌍이 들어갈 수도 있다. output은 task의 종류에 따라 달라지는데, 분류 문제의 경우 [CLS] token을 사용해 분류 결과를 출력한다.
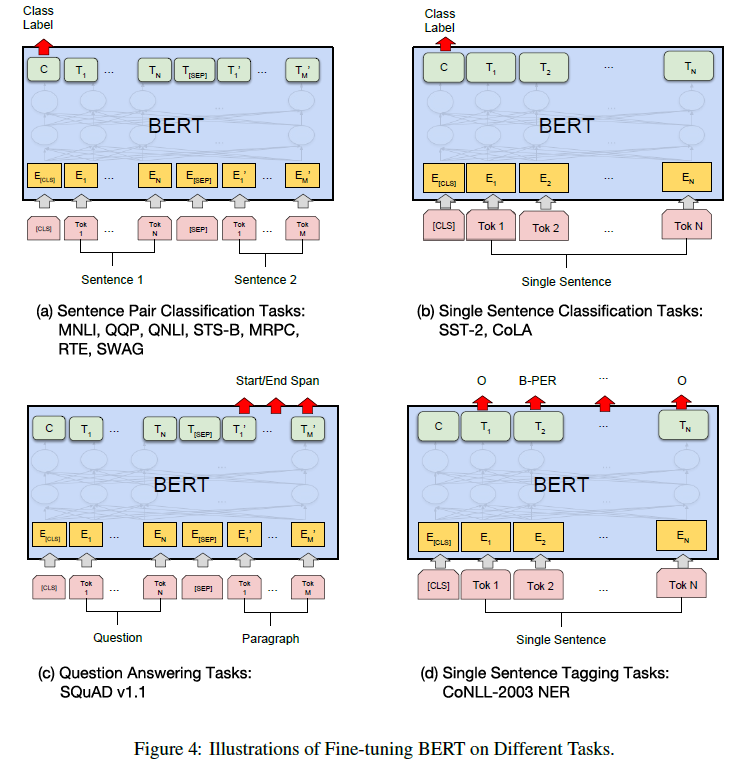
위 그림에서 (a)와 (b)는 sequence-level task이고, (c)와 (d)는 token-level task이다. (a)와 (b)는 분류 task이므로 [CLS] token을 classification output으로 사용한다. (c)는 Question이 주어졌을 때 Answer의 시작, 끝 위치를 찾는 task이다. (d)는 하나의 문장에 나오는 각 token들을 tagging하는 task이다.
fine-tuning은 pre-training에 비해 빠르게 학습되며, 데이터 크기가 클수록 정확도가 상승하는 특징이 있다.
3. Experiments
3.1 GLUE
먼저 General Language Understanding Evaluation(이하 GLUE)의 8개 task를 이용해 BERT의 성능을 측정했다. GLUE의 task들은 아래와 같다.
- Multi-Genre Natural Language Inference(MNLI): 두 문장이 주어졌을 때 뒷 문장이 앞 문장에 수반되는지/반대되는지/중립인지를 맞추는 task
- Quora Question Pairs(QQP): 두 question이 서로 동일한 의미를 갖는지 여부를 판단하는 task
- Question Natural Language Inference(QNLI): Question과 Sentence가 주어졌을 때, Question에 대한 답을 Sentence에서 찾을 수 있는지 판단하는 task
- Stanford Sentiment Treebank(SST-2): 영화 리뷰의 한 문장이 주어졌을 때, 긍정적인지/부정적인지를 분류하는 task
- Corpus of Linguistic Acceptability(CoLA): 문장이 문법적으로 옳은지를 판단하는 task
- Semantic Textual Similarity Benchmark(STS-B): 두 문장이 얼마나 비슷한지 1점에서 5점 사이의 점수로 나타내는 task
- Microsoft Research Paraphrase Corpus(MRPC): 두 문장이 서로 동일한 의미를 갖는지 여부를 판단하는 task
- Recognizing Textual Entailment(RTE): MNLI와 비슷하지만 더 적은 수의 training data로 뒷 문장이 앞 문장에 수반되는지 여부를 판단하는 task
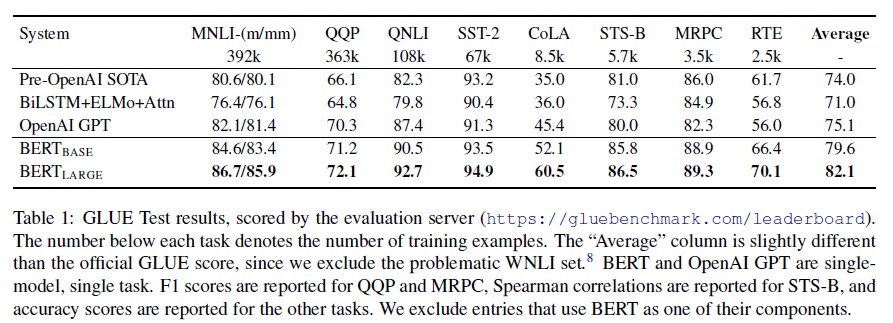
결과를 살펴보면, BERT Base 모델은 GPT와 비교했을 때 모든 task에서 나은 성능을 보였다. 그리고 BERT Large는 5개 모델 중 GLUE task들을 가장 잘 수행했다.
3.2 SQuAD v1.1
이어서 Stanford Question Answering Dataset(이하 SQuAD)을 사용해 Question에 대한 Answer를 문단에서 찾아내는 task에 대한 수행도를 평가했다.
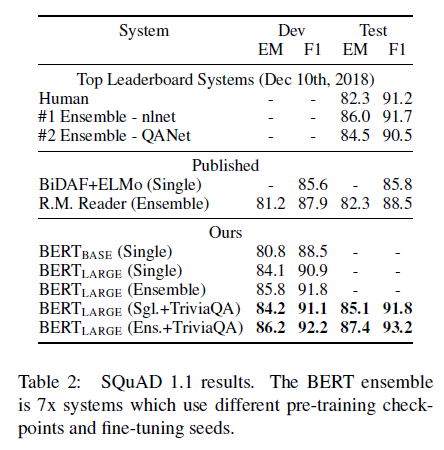
그 결과, single BERT 모델이 기존 앙상블 모델에 비해 더 높은 f1-score를 보였다. TriviaQA fine-tuning data를 제외해도 여전히 기존 모델에 비해 좋은 성능을 보인 것을 알 수 있다.
3.3 SQuAD v2.0
SQuAD 2.0 task는 Question에 대한 Answer를 문단에서 찾는 task임은 동일하지만, 길이가 짧은 Answer가 존재하지 않아 SQuAD 1.1에 비해 더 현실적이라고 할 수 있는 task이다.
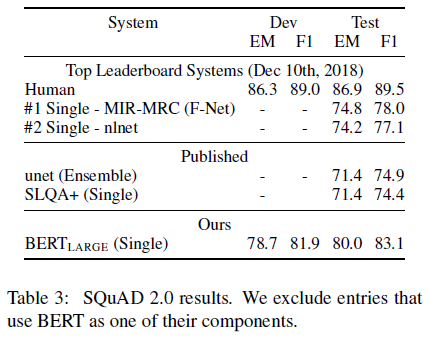
SQuAD 2.0에서도 BERT가 기존 모델에 비해 좋은 f1-score를 얻었음을 확인할 수 있다.
3.4 SWAG
마지막으로 Situations With Adversarial Generations(이하 SWAG)을 이용해 4개의 문장 중에서 문장 A 뒤에 올 문장 B를 고르는 task를 수행했다.
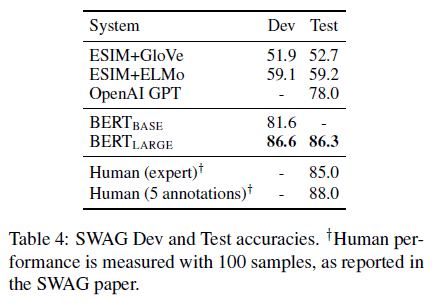
이번에도 BERT는 ESIM+ELMo 모델보다 27.1%, OpenAI GPT보다 8.3% 높은 성능을 보였다.
정리하면, BERT는 MLM, NSP 사전 훈련을 거쳐 양방향에서 문맥을 이해하는 구조를 가진 모델로 기존 SOTA 모델과 비교했을 때 다양한 종류의 NLP task를 성공적으로 수행하는 모델이다.
소감
구글에서 연구한 모델이라니..! 양방향으로 문맥을 파악하는 BERT의 성능이 기존 모델들에 비해 월등했다는 점이 인상깊었다. 물론 지금은 2020년 6월에 나온 GPT-3가 가장 뛰어난 언어 모델이라고 한다. BERT도 나름 나온지 3년도 안된 따끈따끈한 모델인데, 그새 GPT-3에게 따라잡힌 것을 보면 AI 기술이 매년 빠르게 진화한다는 것이 실감났다.

인상깊게 잘 읽었습니다...!