[Paper Review] Latent Aspect Rating Analysis on Review Text Data: A Rating Regression Approach
Hongning Wang, Yue Lu, Chengxiang Zhai. 2010. Latent Aspect Rating Analysis on Review Text Data: A Rating Regression Approach, Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
여름방학 중 데이터마이닝랩 인턴을 하며 Social CVF 탐색 과제 참여의 일환으로 읽게 된 논문이다.
1. Introduction
리뷰를 분석하여 주요한 문장을 추출하고, 상품이나 서비스에 대한 고객들의 의견을 파악하는 것은 중요한 과제이다. 특히 리뷰의 총점(이하 overall rating)이 같더라도 고객마다 중요하게 생각한 요소(이하 aspect)는 다를 수 있기 때문에, 주요 aspect들을 정하고 각각의 aspect에 대한 개별 rating을 분석하는 과정이 필요하다.

이와 관련한 연구를 Latent Aspect Rating Analysis(LARA)라고 부른다. LARA의 목표는 overall rating과 리뷰 내용을 바탕으로 주요 aspect들에 대한 고객의 rating과, 각 aspect에 대해 고객이 생각하는 상대적인 중요도(이하 aspect weight)를 추론하는 것이다.
LARA 문제 해결을 위해서는 2가지 가정이 필요하다. 하나는 고객이 매기는 overall rating은 각 aspect rating의 가중치 합으로 계산된다는 것이고, 다른 하나는 각 aspect에 대한 rating 또한 리뷰 내에서 등장하는 관련 단어들의 가중치 합으로 생성된다는 것이다.
본 논문에서는 위 가정을 바탕으로 2단계 접근법을 제시하였다. 1단계에서는 bootstrapping 기반 알고리즘을 이용해 리뷰의 주요 aspect를 파악하고 내용을 분할한다. 2단계에서는 분할된 리뷰의 내용과 overall rating에 generative Latent Rating Regression(LRR) 모델을 적용하여 aspect rating과 aspect weight을 추론한다. 이렇게 제안된 모델의 성능을 평가하기 위해 논문에서는 TripAdviser의 호텔 데이터를 이용했다.
2. Problem Definition
먼저 논문에서 사용된 용어의 정의이다.
를 리뷰 문서들의 집합이라고 하고, 각각의 리뷰 에 대하여 overall rating을 라고 한다. 그리고 개의 단어들의 집합 이 있다고 가정한다.
Overall Rating
리뷰 의 overall rating 는 과 사이의 값으로, 리뷰 의 내용을 종합적으로 대변하는 하나의 수이다.
Aspect
Aspect 는 리뷰에서 동일한 평가 요소 속성을 가지는 단어들의 집합이다. 예를 들어, 호텔 리뷰에서 '가격', '가치', '값'과 같은 단어들은 공통적으로 호텔의 '가격'에 대한 특성을 나타내므로 하나의 aspect에 포함된다.
좀 더 수학적으로 표현하면 한 단어를 aspect에 mapping 시키는 함수를 이라고 할 때, 으로 나타낼 수 있다.
본 논문에서는 리뷰마다 개의 aspect가 있다고 가정하였다.
Aspect Ratings
Aspect Rating 는 개의 aspect에 대한 만족도를 요소로 가지는 차원 벡터이다. 즉, 번째 요소 는 리뷰 를 작성한 고객이 에 대해 얼마나 만족했는지를 표현하는 수이다. 의 값을 가지며, 수가 클수록 더 높은 만족도를 나타낸다.
Aspect Weights
Aspect Weight 는 개의 aspect에 대해 리뷰 에서 여기는 중요도를 요소로 가지는 차원 벡터이다. 번째 요소 는 범위의 값을 가지며, 을 만족한다. aspect weight 값이 크다는 것은 리뷰를 작성한 고객이 해당 aspect에 더 큰 중요도를 부여한다는 뜻이다.
Latent Aspect Rating Analysis(LARA)
리뷰 집합 와 주제 가 주어졌을 때, LARA는 각각의 리뷰가 개의 aspect에 대해 평가하는 점수 와 상대적 중요도 를 찾는 연구이다.
3. Methods
3.1 Aspect Segmentation
aspect segmentation의 목적은 리뷰 내의 문장들이 어떤 aspect와 관련이 있는지를 mapping해주는 것이다. 본 논문에서는 사전에 7개의 aspect를 지정하고 각 aspect에 속하는 seed word들을 정해주었다.

aspect segmentation은 문장 단위로 이루어지기 때문에, 리뷰의 모든 문장들을 하나씩 split 시키는 전처리 과정이 선행되어야 한다. 그 후 아래 iterative algorithm을 통과시킨다.

알고리즘의 내용을 살펴보면, 먼저 리뷰 텍스트의 각 문장을 문장 내에서 가장 많은 단어들이 속한 aspect에 할당한다. 그리고 모든 aspect와 단어 사이의 dependency를 계산하기 위해 카이제곱 분포를 이용한 아래의 식을 이용한다. 식에서 는 단어, 는 aspect를 나타낸다.
- : aspect 에 속하는 문장들에서 등장하는 의 수
- : aspect 에 속하지 않는 문장들에서 등장하는 의 수
- : aspect 에 속하는 문장들 중 가 포함되지 않은 문장의 수
- : aspect 에 속하지도 않고, 도 포함하고 있지 않은 문장의 수
- : 단어의 전체 등장 횟수
dependency를 계산한 후에는 aspect별로 가장 dependency가 높은 개의 단어들을 골라 aspect keyword list를 만든다. 이때 를 selection threshold라고 부른다.
이 과정을 keyword list가 더이상 변하지 않거나 iteration이 총 회 돌 때까지 반복하면 aspect segmentation이 완료된다. aspect segmentation이 끝나면 리뷰 텍스트의 각 문장은 가장 관련성이 높은 aspect에 할당된 상태가 된다.
마지막으로 크기의 feature matrix 를 만드는데, 여기서 는 리뷰 번호, 는 전체 aspect의 수, 은 전체 단어의 개수를 나타낸다. 의 각 원소 는 특정 aspect 에서 단어 가 나오는 빈도를 전체 단어의 수에 대해 정규화한 값이다.
3.2 Latent Rating Regression Model(LRR)
LRR 모델은 앞서 aspect segmentation을 통해 만들어진 feature matrix 를 독립변수, overall rating 를 종속변수로 하는 회귀 모델이다.
먼저 aspect rating 를 계산하기 위해, 단어의 빈도를 나타내는 에 단어의 sentiment polarity를 나타내는 벡터 를 곱한다.
한 가지 알아두어야 할 점은 각 aspect 에 대응되는 가 각각 따로 존재한다는 것이다. 즉, 같은 단어라도 어떤 aspect 관점에서 보는지에 따라 sentiment polarity 값이 다를 수 있다. 예를 들어 'luxury'라는 단어는 'room' 측면에서는 긍정적일 수 있지만, 'price' 측면에서는 부정적이다.
이렇게 얻어진 들의 가중치 합( )으로 overall rating 를 나타낼 수 있는데, 이때의 계수인 는 aspect의 중요도를 나타내는 aspect weight가 된다. 이 aspect weight 값이 크다는 것은 해당 aspect가 overall rating에 중요한 영향을 미친다는 것을 의미한다.
overall rating 예측의 불확실성을 고려하여 베이지안 regression을 사용하면, 종속 변수를 하나의 값으로 예측하는 것이 아니라 종속 변수가 따르는 확률 분포를 예측하게 된다. 본 논문에서는 가 정규분포를 따른다고 가정했다. 분산에 해당하는 은 예측의 불확실성을 나타내는 모델 파라미터이다.
또한 사람마다 aspect에 대한 중요도가 다를 것이고, aspect끼리의 독립성이 보장되지 않기 때문에 가 평균 , 공분산 의 다변량 정규분포를 따르는 확률변수라고 가정하였다. 이 분포는 베이지안 통계의 사전확률분포가 된다. 와 또한 모델의 파라미터인데, 뒤에서 정의할 likelihood를 최대화하는 방향으로 값이 조정된다.
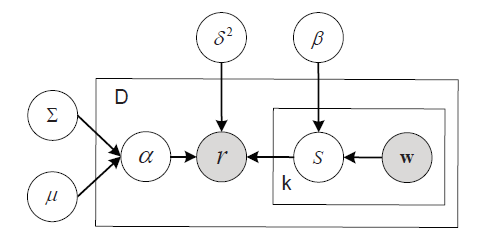
지금까지의 내용을 정리하면 아래 그림과 같다.

overall rating 과 feature matrix element 는 input으로부터 얻어지는 값이고, 는 모델의 파라미터이다. 와 word sentiment polarity 를 곱하여 aspect rating 를 구하고 와 을 이용해 베이지안 regression 문제를 푼다. 이때 계수가 되는 aspect weight 는 사전확률분포 를 따른다고 가정하였고, 예측에 대한 불확실성을 으로 표현하였다.
다음으로 베이지안 regression 문제를 풀기 위해 MAP estimation method가 사용되었다. MAP estimation method는 주어진 관측 결과와 사전확률분포를 결합해서 최적의 모수를 찾아내는 방법이다. 최대화하고자 하는 목적함수는 아래와 같다.

목적함수는 에 대한 사전 확률과, 파라미터들이 주어졌을 때 관측한 값이 나타날 likelihood의 곱으로 이루어져 있다. 식을 에 대해 정리한 후 미분하여 최적화 문제를 풀면 의 값을 구할 수 있다. 는 aspect weight의 정의에 맞게 0 이상 1 이하의 값을 가지며 총합이 1이 된다.

3.3 LRR Model Estimation
3.2에서는 모델 파라미터 집합이 주어졌을 때 aspect weight 를 구하는 방법에 대해 알아보았다. 사실 파라미터 값은 주어진 것이 아니기 때문에, 본 논문에서는 Maximum likelihood estimation을 사용하여 overall rating 가 관측될 확률을 최대화하는 LRR 모델의 파라미터 를 구한다.
log-likelihood 함수는 다음과 같다.

따라서 ML estimate 식은 이 값을 최대화하는 를 목표로 한다.

최적의 파라미터 를 구하기 위해 를 랜덤으로 초기화하고, 이후 EM algorithm을 반복한다. E-Step에서는 현재의 파라미터 를 바탕으로 aspect rating 와 aspect weight 를 구한다. 그리고 M-Step에서는 계산된 와 , 관측된 의 likelihood를 증가시키는 방향으로 가 업데이트된다. 이 과정을 likelihood 값이 수렴할 때까지 반복하면 최적의 값을 찾을 수 있다.
4. Experiment Results
4.1 Data Set and Preprocessing
제안된 모델의 성능을 검증하기 위해 TripAdvisor의 235,793개의 호텔 리뷰 데이터를 이용했다. TripAdvisor의 리뷰 데이터는 value, room, location, cleanliness, check in/front desk, service, business service의 총 7개 aspect에 대한 rating이 매겨져있기 때문에, overall rating과 리뷰 내용만을 가지고 LRR 모델을 훈련시킨 후 도출된 aspect rating을 실제값과 비교할 수 있다는 장점이 있다.
실험에 앞서 아래 그림과 같이 aspect 7개와 그에 해당되는 seed word를 사전에 정의해두었다.
논문에서는 selection threshold 값을 로 설정했고, iteration step limit을 으로 두었다.
4.2 Qualitive evaluation
Aspect-level Hotel Analysis
아래 표는 LRR 모델을 이용해 value, room, location, cleanliness 4개 aspect에 대한 aspect rating 값을 예측한 결과이다. 괄호 안의 값은 실제 고객이 매긴 aspect rating의 평균이다.

위 표에 있는 3개 호텔은 overall rating 값이 동일한 호텔들이다. 결과를 살펴보면 각 aspect에 대한 rating의 경향성이 실제값과 비슷하다는 것을 알 수 있다. 물론 LRR 모델이 aspect rating 값을 하나하나 정확하게 맞춘 것은 아니지만, overall rating과 리뷰 내용만으로 aspect rating을 예측하는 것이 가능함을 보여준다.
Reviewer-level Hotel Analysis
다음은 같은 호텔에 대해 서로 다른 고객의 aspect rating을 예측한 표이다. 괄호 안의 값은 실제 고객이 매긴 aspect rating이다.

표를 살펴보면, MR.Saturday는 cleanliness에 대해 높은 점수를 줄 것이라고 예측했고, 실제로도 가장 높은 5점을 주었다. 또 Salsrug는 value와 location에 대해 높은 점수를 줄 것으로 예측했고, 실제로도 비슷한 양상을 띠었다. 이처럼 리뷰 내용을 토대로 개인별 aspect rating이 어떻게 될 것인지를 예측하는 것도 가능하다.
Corpus Specific Word Sentimental Orientation
다음은 sentiment polarity 의 최종값을 바탕으로, value, rooms, location, cleanliness 4개 aspect에 대해 긍정적인 의미가 내포된 단어 5개와 부정적인 의미가 내포된 단어 5개를 정리한 표이다.

예를 들어, 'clean'이라는 단어는 청결 상태가 좋았음을 가장 잘 나타내는 단어이고, 'smelly'라는 단어는 반대로 청결 상태가 나빴음을 가장 잘 나타내는 단어라는 것을 알 수 있다. LRR 모델은 텍스트 데이터로 weight 값을 산출했기 때문에 domain specific한 sentiment polarity를 얻어낼 수 있다는 장점이 있다.
4.3 Applications
논문에서 제안된 LRR 모델을 적용할 수 있는 사례 3가지를 간략히 소개한다.
Aspect-Based Summarization
긴 리뷰 텍스트를 요약해서 간결한 aspect-based summary를 만들 수 있다. 수많은 리뷰를 직접 일일이 읽어보지 않고도 호텔의 장점과 단점을 요약하여 나타내준다.
User Rating Behavior Analysis
고객이 중요시하는 aspect가 무엇인지, 평가를 내리는 데에 가장 큰 영향을 미친 요소가 무엇인지 분석이 가능하다.
Personalized ranking
고객이 중요시하는 aspect를 기반으로 개인화된 호텔 ranking을 매길 수 있다. 논문에서는 한 고객과 비슷한 rating behavior를 가진 다른 고객들의 리뷰를 기반으로 호텔의 ranking을 매기는 방식을 제안했다.
소감
처음 접한 NLP 관련 논문이었는데, 생소한 텍스트마이닝 용어나 개념들이 나올 때마다 찾아보면서 스스로 공부하는 기회가 되었다. 호텔 리뷰 데이터로 aspect rating과 aspect weight을 도출해내는 내용 자체가 흥미로웠고, 논문에 수식이 많은 편은 아니라서 그나마 이해가 잘 됐던 것 같다. 프로젝트를 진행하려면 이 내용을 코드로 구현해야하는데, 어렵겠지만 한 번 도전해봐야겠다😄



너무 유익해요!