[Paper Review] Deep Neural Networks for YouTube Recommendations
P. Covington, J. Adams, E. Sargin. Deep neural networks for youtube recommendations. Proceedings of the 10th ACM Conference on Recommender Systems, ACM (2016), pp. 191-198
I. Introduction
유튜브는 전세계에서 가장 큰 동영상 플랫폼 기업으로, 끊임없이 늘어나는 비디오 콘텐츠로부터 십억 명 이상의 유저들에게 개인화된 추천을 제공한다. 이 과정에서 풀어야 할 3개의 숙제는 다음과 같다.
-
Scale: 대부분의 추천 알고리즘은 작은 데이터셋에서는 잘 작동하지만, 유튜브 정도의 규모에서 쓰기엔 어렵다. 유튜브의 수많은 유저와 영상을 기반으로 한 추천 알고리즘이 작동하기 위해서는 대규모 데이터셋에 특화된 알고리즘과 효율적인 서빙 시스템이 필요하다.
-
Freshness: 유튜브는 1초에 수많은 영상들이 올라오는데, 그 길이도 제각각이다. 따라서 유튜브 추천시스템은 유저의 최신 행동 뿐만 아니라 실시간으로 업데이트되는 콘텐츠들도 다룰 수 있어야 한다.
-
Noise: 데이터의 희소성과 관측되지 않은 다양한 external factor의 존재로 유저 행동을 예측하기 어려운 문제가 있다. 따라서 추천시스템에서는 implicit feedback signal을 통해 유저의 선호도를 추정한다. 이때 metadata가 잘 구축되어있지 않은 경우도 있는데, 추천시스템은 이런 노이즈에 대해서도 robust해야 할 필요가 있다.
본 논문에서는 유튜브 영상 추천시스템에 활용된 딥러닝 기술에 대해 다룰 것이다.
II. System Overview
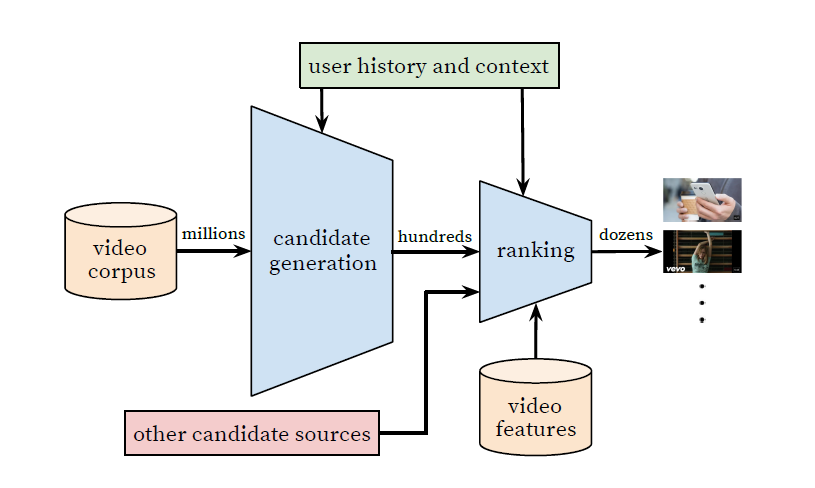
유튜브 추천시스템의 대략적인 구조는 아래 그림과 같다. 크게 2개의 neural network로 구성되는데, 하나는 candidate generation의 역할을 하고 다른 하나는 ranking의 역할을 한다.
먼저 candidate generation network에서는 유저의 과거 기록을 input으로 받아 개인화된 영상 후보군을 도출한다. 이때 precision 값이 높게 나오도록 모델을 학습한다. candidate generation은 collaborative filtering을 통해 이루어지며, 그 과정에서 유저 간의 유사도를 계산하기 위해 시청한 영상 ID, 검색어, 인구통계학적인 정보를 사용한다.
다음으로 ranking network에서는 각각의 후보군 영상들과 유저 간에 점수를 매기고 순위를 부여한다. 이때는 recall 값이 높게 나오도록 모델을 학습하여 상대적인 중요도가 높은, 유저 화면에 배치할 영상을 선별한다.
모델 학습을 위해 precision, recall, ranking loss 등의 offline metric을 활용했지만, 실제 모델의 effectiveness를 평가할 때에는 A/B test를 진행하였다. A/B test를 통해서는 click-through rate, 시청 시간, 그리고 이외에 유저의 유입을 나타내는 다른 지표를 측정하고 비교할 수 있기 때문이다.
III. Candidate Generation
candidate generation은 수백만 개 이상의 유튜브 영상 중 유저와 관련 있는 수백 개의 영상만 필터링해주는 과정이다.
3.1 Recommendation as Classification
저자는 추천 작업을 multiclass classification 문제로 다루었다. corpus 에 있는 수백만 개의 영상 (class) 중 유저 와 맥락 를 고려하여 시점에 볼 영상 을 예측하는 문제로 본 것이다.
식에서 은 유저와 맥락에 대한 고차원 embedding, 은 각각의 후보군 영상에 대한 embedding을 의미한다. Deep neural network 태스크의 목표는 유저의 영상 시청 기록과 맥락을 기반으로 embedding 를 학습하여 softmax classifier로 영상을 식별해낼 수 있게 만드는 것이다.
유튜브에는 좋아요, 설문조사 등 explicit한 feedback이 존재하지만, 저자는 유저가 영상 시청을 끝까지 마친 경우를 positive example로 정의한 implicit feedback을 사용해 모델을 학습시켰다. 이는 sparse한 explicit feedback 데이터의 한계를 보완하며, 더 일반화된 추천이 가능하게 해준다.
Efficient Extreme Multiclass
수백만 개의 클래스를 다루는 모델을 효율적으로 학습시키기 위해서, background distribution으로부터 negative sample을 수집했다. 그리고 true label과 수집된 negative class간의 cross-entropy loss를 최소화하는 방식으로 모델을 학습시켰다.
모델 서빙 과정에서는 유저에게 추천해줄 top N개의 영상을 선택하기 위한 연산이 수행되어야 했는데, 이때 기존 유튜브 시스템에 활용되었던 hashing 방식을 이용해 수백만 개의 아이템에 대한 스코어링 시간을 sublinear하게 단축시켰다.
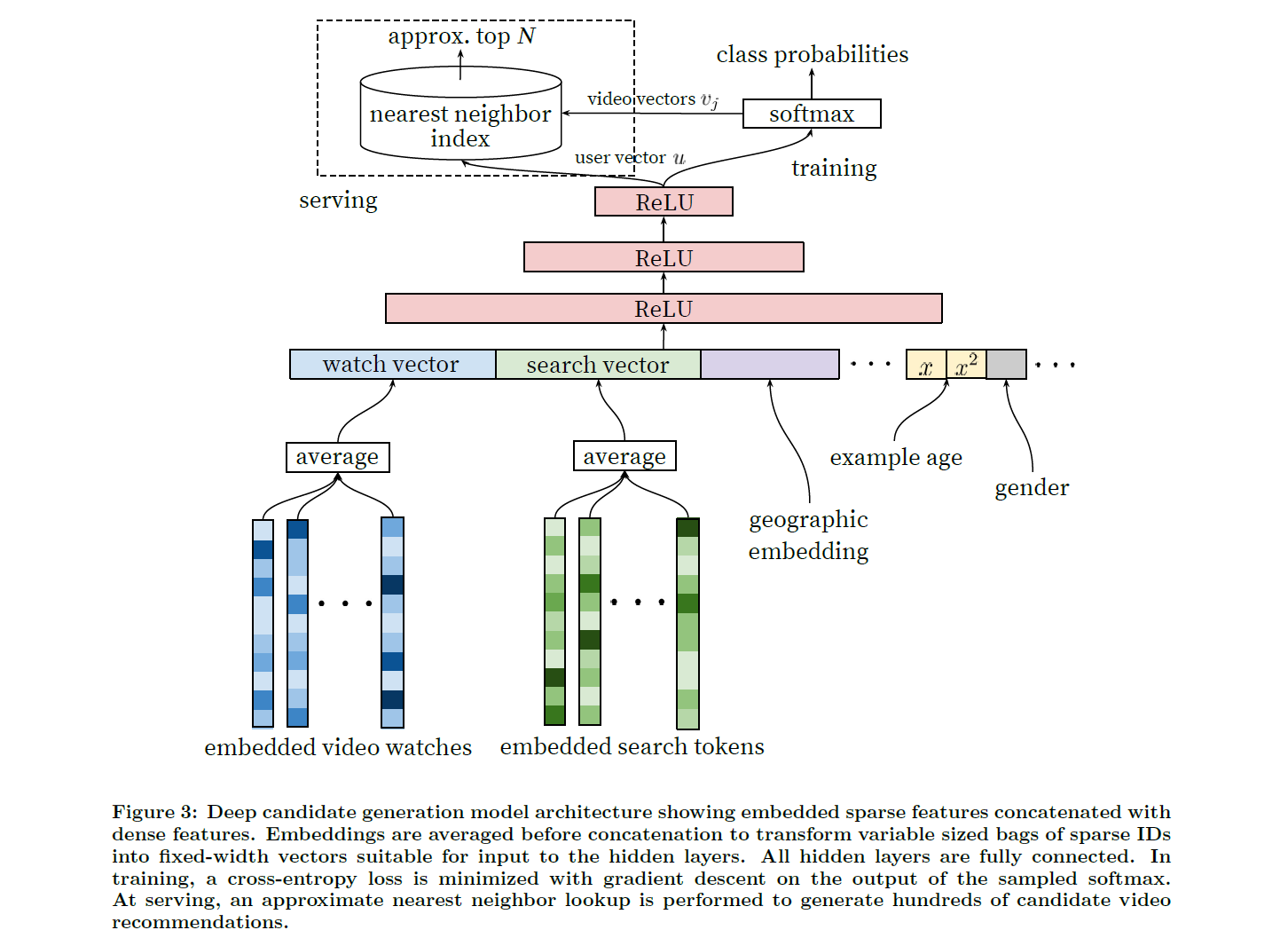
3.2 Model Architecture
모델 학습을 위해 우선 각각의 영상을 고정된 vocabulary로 이루어진 고차원 embedding으로 나타낸 후 feedforward neural network에 통과시켰다. 유저의 영상 시청 기록은 sparse한 영상 ID sequence로 나타내어지는데, 이때 앞에서 만들어진 embedding을 평균낸 값을 고정된 길이의 dense input으로 활용했다. 이외에 age, gender 등 feature들을 concatenate하여 첫 번째 wide layer에 투입했고 이후 fully connected ReLU layer를 쌓은 형태로 구조를 설계했다.
구체적인 모델 구조는 아래 그림과 같다.
3.3 Heterogeneous Signals
Deep neural network를 matrix factorization의 일환으로 사용했을 때의 장점은 연속형, 범주형 feature를 모델에 쉽게 추가할 수 있다는 점이다. 그 예로, 유저들의 검색어 데이터를 unigram과 bigram으로 tokenized하여 embedding을 만들고 이를 평균낸 dense vector를 검색 기록에 대한 representation으로써 모델에 투입할 수 있다. 또한 인구통계학적인 정보나 유저의 거주지, 디바이스 정보, 성별, 나이, 로그인 지역 등의 데이터 역시 [0, 1]의 크기로 normalized되어 network에 바로 투입될 수 있다.
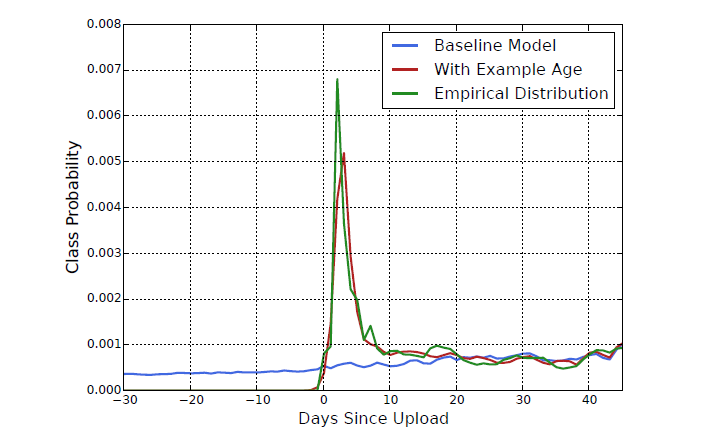
"Example Age" Feature
유튜브 유저들은 fresh한 영상을 선호하는 경향이 있다. 따라서 추천에 있어서 최신성은 특히 중요하다. 다만 머신러닝은 과거 데이터로 미래를 예측하기 때문에 종종 과거의 아이템에 편향된 결과를 제공한다. 영상의 popularity는 시간에 따라 변화하지만, 위에서 제안된 모델 구조에서는 영상 시청 기록의 평균으로 input을 만들고 있어 시간적인 의미를 담지 못한다. 따라서 저자는 이를 보완해주기 위해 영상의 age를 feature로 추가하였다.
그 결과 아래 그래프에서 볼 수 있듯이 모델의 성능이 크게 개선되었다.
3.4 Label and Context Selection
대부분의 추천시스템은 surrogate problem이 있다. 모델의 성능 평가를 위해서는 A/B testing이 필요하지만 매번 실제 유저들의 선택으로 성능을 평가하는 데에는 한계가 있으므로 Hit Rate, NDCG와 같은 offline metric을 이용하곤 한다.
유튜브 추천시스템에서 학습 데이터는 모델이 만들어내는 추천 결과 뿐만 아니라 외부 사이트를 포함한 모든 유튜브 시청 데이터를 기반으로 만들어져야 한다. 그렇지 않다면 exploitation에 편향이 생겨 새로운 콘텐츠에 대한 추천이 어렵기 때문이다. 만약 유저들이 제공받은 추천 알고리즘 외에 다른 방식으로 영상을 탐색한다면, 이를 collaborative filtering에 빠르게 반영해주어야 한다. 또 영상 시청 기록이 매우 많은 유저에게 과도하게 가중치가 부여되는 것을 방지하기 위해 유저별로 학습에 사용할 데이터의 길이를 고정시켜줄 필요가 있다.
직관에 반대될 수도 있겠지만, 모델의 overfitting 문제를 방지하기 위해 classifier에서 나온 정보를 추천 결과에 즉시 반영하지는 않는다. 하나하나의 검색 기록을 모두 추천 결과에 반영하면 오히려 성능이 낮아지는 현상이 나타났다.
또 유저의 비대칭적인 영상 시청 패턴을 모델이 학습할 수 있게 구조를 설계했다. 대부분의 collaborative filtering 시스템은 아래 (5a)와 같이 유저의 시청 기록 중 하나를 랜덤하게 가리고 다른 시청 기록으로부터 해당 영상이 무엇일지 예측하는데, 이 경우 비대칭적인 영상 시청 패턴을 무시하게 된다. 따라서 (5b)처럼 유저가 시청할 영상을 예측할 때 해당 시점 이전의 기록만을 input으로 받게 했다.
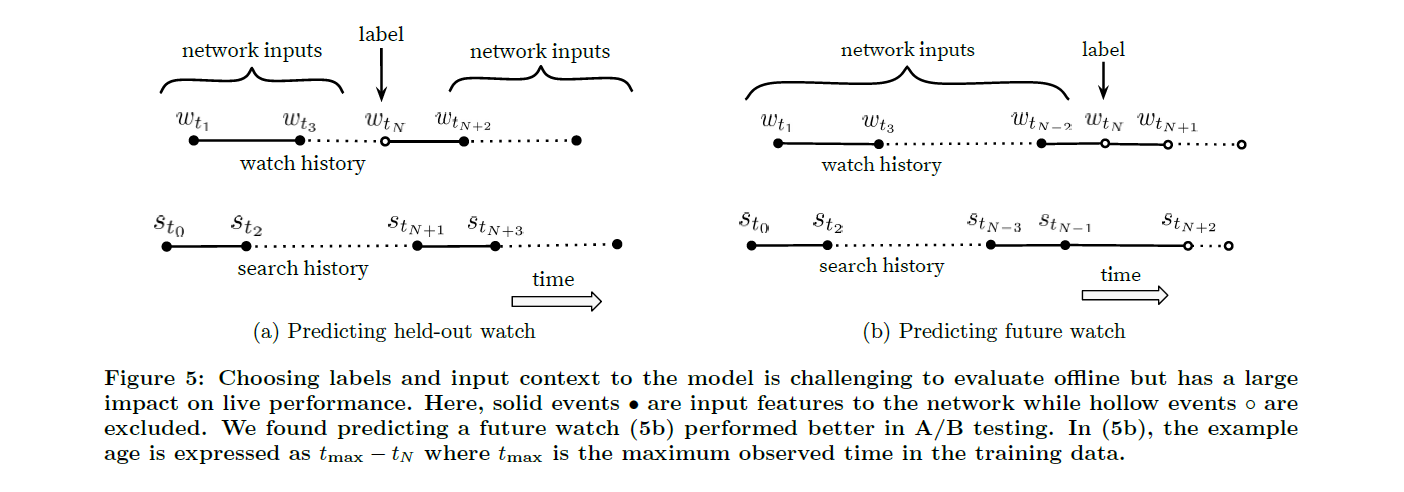
IV. Ranking
Ranking의 주요 역할은 impression 데이터를 사용해 후보군 영상들에게 정량적인 스코어를 매기는 것이다. 영상의 수가 수백 개로 줄어들었기 때문에 더 많은 feature를 투입해 영상과 유저 간의 스코어를 연산하는 것이 가능하다.
Ranking 과정에서는 앞서 candidate generation에 사용되었던 모델 구조와 비슷한 deep neural network를 사용하여 logistic regression으로 각 영상에 스코어를 부여했다. 그리고 최종적으로 한 번의 노출로 기대되는 시청 시간을 기준으로 A/B testing을 수행해 모델의 성능을 평가했다.
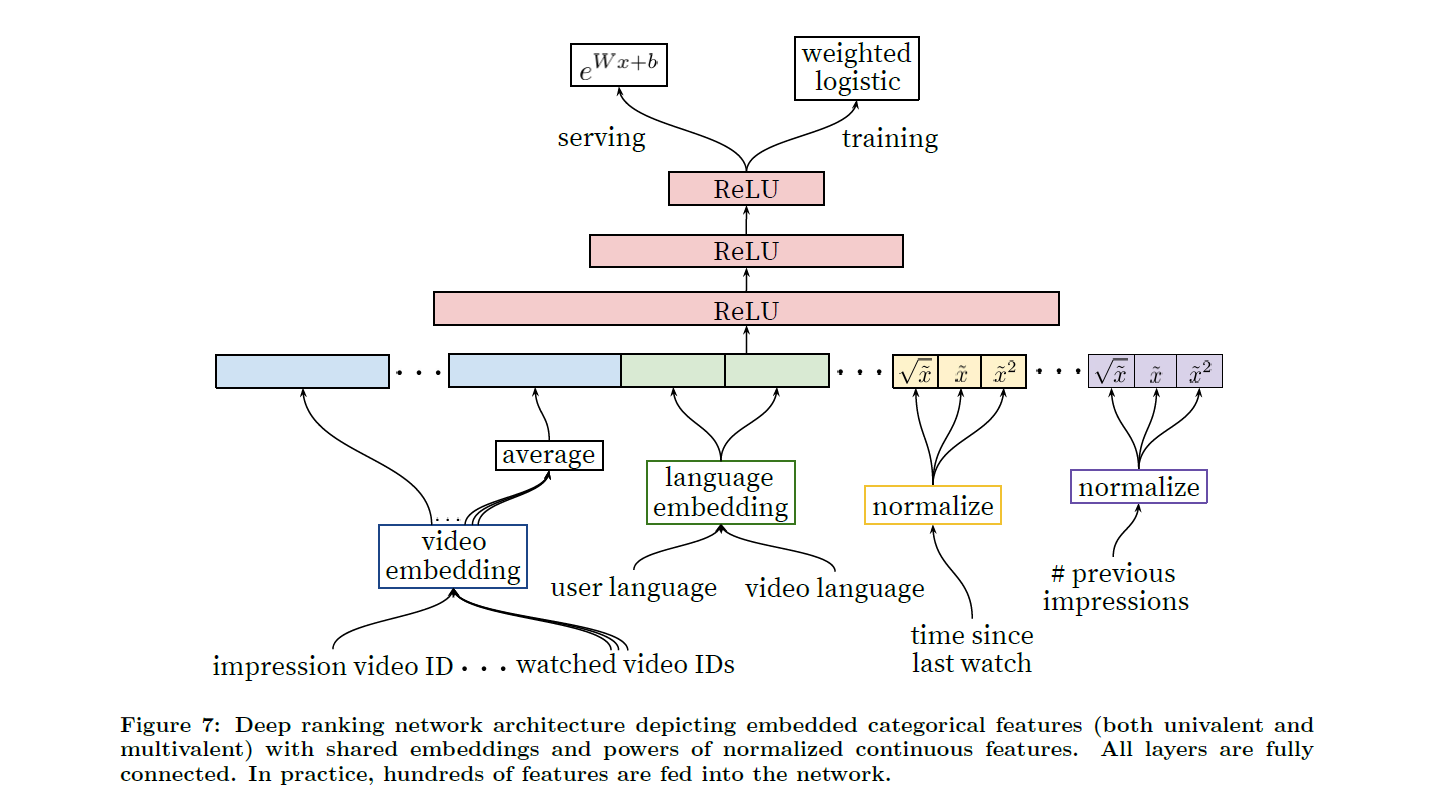
4.1 Feature Representation
Feature Engineering
ranking model에서 사용하는 feature 종류는 수백 개가 넘는다. 딥러닝은 데이터 전처리에 대한 수고를 덜어주지만, 그래도 유튜브에서 발생하는 raw data는 input으로 투입되기 위해 어느 정도 feature engineering 과정이 필요하다. 이때 주로 생각해봐야 할 점은 유저 액션에 대한 temporal sequence를 어떻게 나타낼지, 그리고 이를 영상 scoring에 어떻게 반영할 것인지이다.
저자는 추천해주려는 영상(또는 그와 비슷한 영상)과 유저의 과거 interaction 정보가 ranking에 있어서 중요한 signal이 된다는 사실을 발견했다. 예를 들어, 유저가 특정 채널에서 영상을 시청한 횟수나 특정 주제에 대한 영상을 시청했던 시점과 같은 데이터는 서로 다른 아이템 사이에서도 잘 일반화될 수 있는 feature이기 때문에 특히 중요하다. 이외에도 candidate generation 과정에서 얻을 수 있는 정보를 ranking에 전파하는 것이 중요하다는 사실과 과거에 영상이 얼마나 노출되었는지를 나타내는 frequency가 주요 feature가 된다는 점도 밝혔다.
Embedding Categorical Features
candidate generation을 수행했을 때처럼 sparse한 categorical feature를 dense representation으로 매핑해주기 위해 embedding을 시켜주었다. 만약 영상 ID나 검색어와 같이 space의 크기가 큰 경우에는 top N개의 빈도를 가진 것만 남기고 영벡터로 embedding 시켜주었다. 그리고 multivalent categorical feature embedding은 평균 벡터를 계산하여 network에 투입시켰다.
중요한 점은 같은 ID space의 categorical feature들이 같은 embedding을 공유했다는 것이다. 이는 generalization 성능을 높여주고 training 속도 향상과 메모리 공간 절약 측면에서 효율적이다.
Normalizing Continuous Features
neural network는 scaling과 input의 분포에 민감하다. 따라서 continuous feature 의 경우 누적 분포를 고려하여 [0, 1)의 크기를 갖는 로 변환해주었다. 그리고 super-, sub-linear한 feature로도 설명력을 높이기 위해 과 도 input으로 넣어주었다.
4.2 Modeling Expected Watch Time
유튜브 추천시스템은 추천된 영상에 대한 기대 시청 시간 예측하는 것을 목표로 weighted logisetic regression과 cross-entropy loss를 이용한다. 이때 positive sample은 실제 시청 시간을 가중치로 부여하고, negative sample의 경우엔 시청 시간이 0이기 때문에 unit weight을 부여한다. 이 방식대로라면 logistic regression의 odds는 가 된다. 은 학습 데이터의 수, 는 positive sample의 수, 는 번째 노출 영상의 시청 시간이다. positive impression의 비율이 작다고 가정하면 학습된 odds는 대략 가 된다. 이때 는 클릭할 확률, 는 노출된 영상에 대한 시청 시간의 기댓값인데, 가 작기 때문에 이 값은 와 비슷하다.
V. Conclusions
본 논문에서는 유튜브 영상을 추천해주는 deep neural network 구조를 2개의 task(candidate generation, ranking)로 나누어 소개한다. 비대칭적인 영상 시청 패턴을 학습하고 미래에 대한 정보를 막음으로써 기존 matrix factorization 방식보다 좋은 성능을 보여주었고, classifier로부터의 signal을 차단한 것도 과적합을 방지하는 데에 주요한 역할을 했다. 또 학습 데이터의 최신성을 고려한 추천으로 A/B testing 결과 시청 시간을 늘릴 수 있었다.
Ranking에서는 유저와 아이템의 과거 interaction을 주요한 feature로 판단해 이에 대한 feature engineering 과정을 거쳤고, categorical feature를 embedding하고 continuous feature를 normalize하여 DNN에 투입했다. 그리고 여러 층의 layer를 쌓아 non-linear한 interaction을 효과적으로 학습하였다.
마지막으로 logistic regression을 변형하여 기대되는 시청 시간을 예측하도록 목적함수를 설정했다. 이렇게 시청 시간을 예측하는 ranking 방식은 click-through rate을 예측했을 때보다 더 좋은 성능을 보였다.
평소에 나와 많은 시간을 함께 하고 있는 유튜브의 추천시스템에 관한 논문이라 흥미롭게 읽을 수 있었다. 성능이 아주 뛰어나다고 알려져있는 유튜브 추천시스템의 큰 틀을 이해할 수 있었고, 다른 논문과 다르게 모델 서빙에 관한 내용도 일부 담겨 있어 느낌이 색달랐다. 이렇게 좋은 추천 알고리즘을 개발하는 머신러닝 엔지니어가 되고 싶다🙂

너무 멋있어요