[Paper Review] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
H. Guo, R. Tang, Y. Ye, Z. Li, and X. He, “Deepfm: A factorizationmachine based neural network for CTR prediction,” in Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, 2017, pp. 1725–1731.
1. Introduction
click-through-rate(CTR) 예측은 유저가 추천된 아이템을 클릭할 확률을 추정하는 task로, 추천시스템의 주요 과제 중 하나이다. 클릭 수를 높여 더 많은 수익을 내는 것은 많은 추천시스템의 목표라고 할 수 있다.
CTR 예측을 위해서는 유저의 클릭 행위 뒤에 숨겨진 implicit feature interaction을 학습할 필요가 있다. 예를 들어 앱 추천시스템의 경우 유저가 앱을 다운받는 행위는 시간대, 유저의 나이와 성별 같은 feature와 앱 카테고리 사이의 interaction이 CTR에 영향을 미칠 수 있다. 이러한 interaction은 매우 복잡하고 low, high-order feature interaction 가릴 것 없이 CTR에 있어서 모두 중요한 역할을 한다.
결국 중요 포인트는 feature interaction을 효과적으로 학습하는 것이다. 선행 연구에서는 generalized linear model부터 factorization machine, wide & deep learning까지 데이터 속에 감춰진 feature interaction을 머신러닝으로 잡아내기 위한 많은 시도가 이루어졌다. 하지만 low-order interaction이나 high-order interaction에만 편향되었거나, feature engineering 과정이 복잡해지는 등 몇몇 한계점이 존재했다.
논문에서 저자는 FM과 DNN의 구조를 결합한 DeepFM 모델을 제안한다. DeepFM은 FM의 특징을 가지고 있어 low-order feature interaction을 학습하고, DNN처럼 high-order feature interaction도 학습할 수 있다. wide & deep model과 같이 복잡한 feature engineering이 필요하지도 않다. 또 wide part와 deep part가 동일한 input, embedding vector를 공유한다는 특징이 있어 complexity를 감소시키고 효과적으로 학습될 수 있다.
2. Our Approach
모델 학습을 위한 데이터는 개의 instance 로 구성되어 있다. 는 유저와 아이템 쌍을 포함하고 있는 -fields data이고, 은 유저의 클릭 행위를 구분하는 associated label이다.
는 범주형 변수와 연속형 변수를 모두 포함할 수 있는데, 범주형 변수의 경우 one-hot encoding으로 나타내고 연속형 변수의 경우 값 그 자체가 feature가 되거나 discretization 후 one-hot encoding으로 나타내는 방법이 있다.
이후 각 instance는 로 변환된다. 인 차원 벡터로 는 에서 번째 field의 벡터 표현식이다. 보통 는 차원이 높고 희소한 벡터이다.
CTR 예측 task는 유저가 특정 앱을 클릭할 확률을 추정하는 예측 모델 를 학습시키는 것이다.
2.1 DeepFM
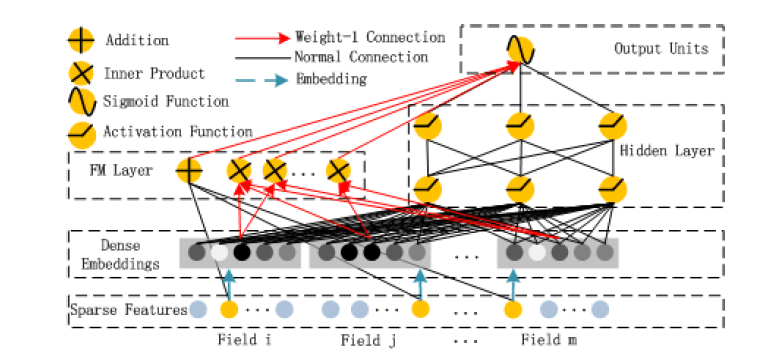
DeepFM의 구조는 아래 그림과 같다. low-, high-order feature interaction을 학습하기 위해 Factorization Machine(FM)과 deep neural network를 결합한 구조를 가지고 있다.
DeepFM에서 FM component와 deep component는 같은 input을 공유한다. feature 에 대해서, 가중치 는 order-1 importance를 나타낸다. 그리고 latent vector 는 FM component에서는 order-2 interaction, deep component에서는 high-order interaction을 나타내기 위해 사용된다.
, , 그리고 network parameter를 포함한 모든 파라미터들은 jointly train되어 다음과 같이 최종 예측값이 도출된다.
은 CTR 예측값, 은 FM component의 output, 은 deep component의 output이다.
FM Component
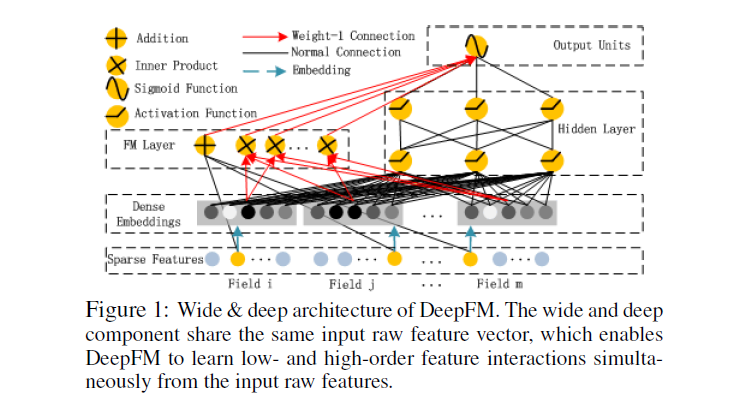
FM component는 아래 그림과 같은 factorization machine이다.
FM은 linear interaction(order-1) 외에도 pairwise feature interaction(order-2)으로써 latent vector간의 inner product 연산을 이용한다. 기존 FM은 feature 와 모두 한 data에 존재할 때 interaction이 학습될 수 있었는데, DeepFM의 FM component에서는 latent vector 와 의 inner product를 통해 order-2 feature interaction이 좀 더 간편하게 계산될 수 있다.
FM 모델의 output은 위 그림에서 볼 수 있듯이 Addition unit과 Inner Product unit의 합이 된다.
Deep Component
deep component는 feed-forward neural network로 high-order feature interaction을 학습하는 것이 목적이다.

CTR 예측을 위한 raw feature input vector는 매우 sparse하고, 높은 차원을 가졌으며, 범주형 변수와 연속형 변수가 섞여있고, 필드들이 그룹화되어있다. 따라서 첫 번째 hidden layer에 통과시키기 전에 input vector를 저차원의 dense한 실수 벡터로 압축시켜주는 과정이 필요하다.
아래 그림은 input layer와 연결된 embedding layer의 구조를 보여준다.
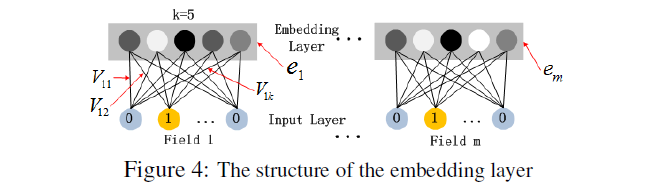
위 network 구조는 두 가지 특징이 있다. 먼저 input field vector들끼리 크기가 다를 수 있음에도 embedding은 같은 크기 로 맞춰진다는 것이다. 또 latent feature vector 가 여기서는 network weight 역할을 하게 된다.
선행연구에서 network를 초기화하기 위해 FM으로 사전학습된 latent feature vector를 사용한 것과 달리, 저자는 FM 모델도 전체 learning architecture에 포함시켰다. 즉 FM을 통한 사전학습 과정을 없애고 전체 network를 end-to-end로 jointly train시켰다.
embedding layer의 output을 이라고 할 때, 은 DNN에 투입되어 아래 식과 같은 forward process를 거친다.
식에서 은 layer depth, 는 활성화 함수, , , 은 각각
번째 layer의 output, weight, bias를 나타낸다.
이렇게 dense real-value feature vector가 만들어지면 sigmoid 함수 를 거치면서 DNN을 통한 CTR 예측값이 도출된다. 는 hidden layer 수이다.
2.2 Relationship with the other Neural Networks
이어서 DeepFM을 CTR 예측에 사용되는 기존 모델들과 비교한다.
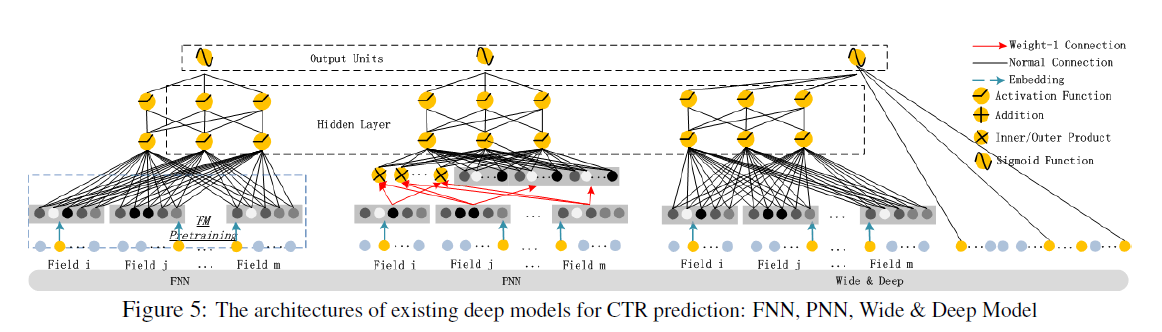
Figure 5에서 가장 왼쪽에 있는 모델은 FNN으로, FM-initialized feed-forward neural network이다. FM을 이용해 pre-train을 하는 원리이지만 몇 가지 단점이 존재한다. 바로 embedding parameter들이 FM에 과도하게 영향을 많이 받는다는 점과 pre-training 단계로 인해 학습 efficiency가 줄어든다는 점이다. 또 high-order feature interaction만을 잡아낸다는 단점도 있다. 반면 DeepFM은 사전학습이 필요없고 high-, low- order interaction을 모두 잡아낼 수 있다.
중앙에 있는 모델은 PNN이다. PNN은 embedding layer와 첫 번째 hidden layer 사이에 product layer를 넣어 inner product, 혹은 outer product로 high-order interaction을 잡아내고자 했다. 다만 outer product가 inner product에 비해 신뢰성이 떨어진다는 점과 연산의 복잡도가 높다는 한계가 존재한다.
가장 오른쪽에 있는 모델은 Wide & Deep Model로, low-, high- order feature interaction을 모두 잡아낼 수 있다는 장점을 가지고 있다. 하지만 wide part에 투입할 input을 만들어내는데 복잡한 feature engineering이 필요하다. DeepFM은 FM과 deep component가 같은 feature embedding을 공유할 수 있게 함으로써 이러한 한계를 극복했다.
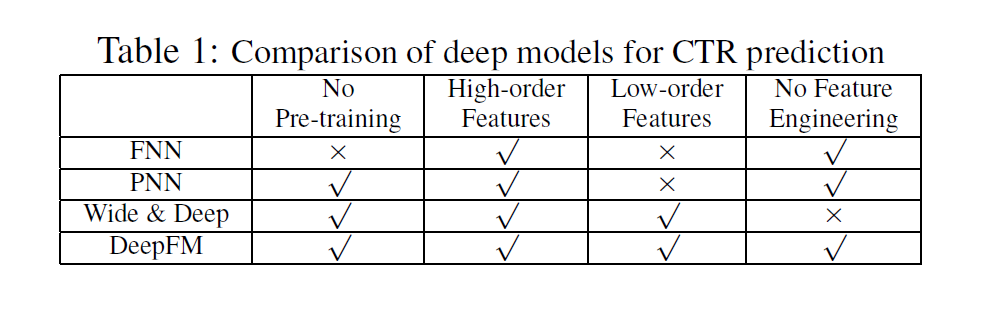
FNN, PNN, Wide & Deep 모델과 DeepFM의 특징을 정리하면 아래 표와 같다.
3. Conclusions
CTR 예측을 위해 본 논문에서 제안된 DeepFM은 FM 기반 neural network 모델로써 deep component와 FM component가 jointly train 된다. DeepFM의 장점은 3가지 정도로 요약할 수 있다. 먼저 별다른 pre-training 과정이 필요하지 않다. 또 high-, low- order feature interaction을 모두 학습할 수 있다. 마지막으로 feature embedding을 공유하여 feature engineering 없이 동작한다.
