[Paper Review] Training Deep AutoEncoders for Collaborative Filtering
Oleksii Kuchaiev, Boris Ginsburg. 2017. Training Deep AutoEncoders for Collaborative Filtering. NVIDIA
1. Introduction
추천시스템은 크게 두 종류로 나눌 수 있다. 첫 번째는 context-based recommendations로, 위치, 날짜, 시간 등의 contextual factor를 고려하는 방법이다. 다른 하나는 personalized recommendations인데, collaborative filtering(CF) 방식으로 유저에게 아이템을 추천해준다. 이때 특정 아이템에 대한 유저의 선호도는 다른 유저들의 선호도와 그들간의 유사성을 기반으로 예측된다.
고전적인 CF task는 크기의 rating matrix 에서 비어있는 값을 추론하는 것으로 entry는 번째 유저의 번째 아이템에 대한 rating을 의미한다. 이러한 CF task의 성능은 보통 RMSE로 평가한다.
1.1 Related Work
딥러닝이 이미지 인식, 자연어 처리와 강화학습에서 좋은 성능을 보여줬기 때문에, 추천시스템에도 이를 적용하려는 시도가 자연스레 이어졌다. 관련해서 restricted Boltzman machines(RBM), feed-foward neural networks, recurrent recommender networks 등 많은 선행 연구가 이루어졌고, 본 논문에서는 그 중 I-AutoRec(item-based autoencoder)과 U-AutoRec(user-based autoencoder)을 확장한 deep autoencoder를 다룬다.
AutoRec에 대한 내용은 이전 논문 리뷰(AutoRec: Autoencoders Meet Collaborative Filtering)를 참고하길 바란다.
2. Model
Deep AutoEncoder 모델은 U-AutoRec으로부터 영감을 받아 만들어진 deep learning 모델이다. pre-training 없이 deep한 model을 학습시키기 위해, 저자는 scaled exponential linear units(SELUs), 높은 dropout rate과 iterative output re-feeding을 학습 과정에서 사용했다.
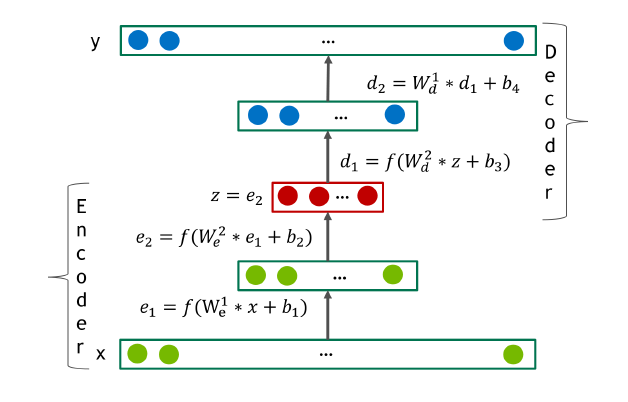
Autoencoder는 인코더 와 디코더 두 가지 transformation으로 이루어진 network로, 와 사이의 오차를 최소화하는 차원의 representation을 얻는 것이 목표이다. 이러한 Autoencoder는 차원 축소를 할 때 사용될 수 있는 좋은 모델로써 PCA(principle component analysis)의 일반화된 버전이라고 볼 수 있다. 아래 그림은 4-layer autoencoder network를 나타낸다.
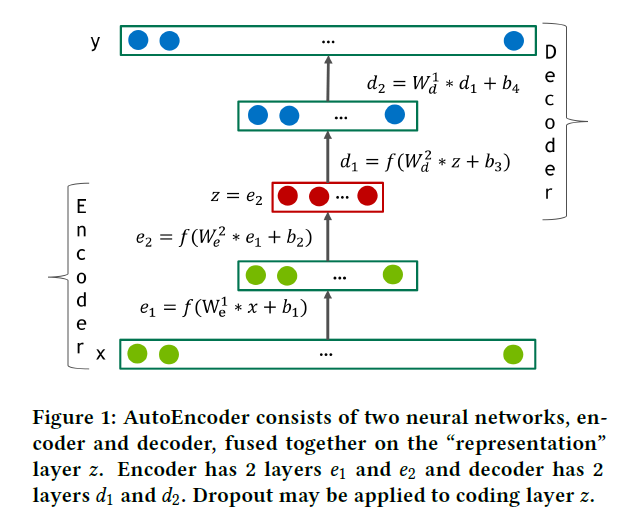
저자들은 Deep AutoEncoder에서 인코더와 디코더를 모두 fully connected feed-forward neural network로 두었다. 즉 형태가 되는데, 는 non-linear한 활성화 함수이다. 만약 활성화 함수의 범위가 데이터 범위보다 작다면, 디코더의 마지막 layer는 linear하게 두었다. 또 hidden layer의 활성화 함수 는 0이 아닌 음수 부분을 포함하고 있어야 하는데, 이를 위해 SELU unit을 사용했다.
만약 디코더와 인코더의 구조가 동일하다면, 번째 디코더의 가중치 은 번째 인코더 가중치 의 transpose로 둘 수 있다. 이런 autoencoder를 constrained 또는 tied autoencoder라고 부르는데, 일반적인 autoencoder에 비해 free parameter를 2배 정도 적게 가진다는 특징이 있다. 논문에서 제안된 모델도 constrained autoencoder에 해당한다.
forward pass 과정에서 모델은 sparse한 training set 의 rating vector로 유저를 표현한다. 이후 디코더의 output 은 모든 item에 대한 rating 예측값을 포함하는 dense vector가 된다.
2.1 Loss Function
유저의 representation vector 에서 이미 0인 rating을 예측하는 것은 적절하지 않다. 따라서 AutoRec: Autoencoders Meet Collaborative Filtering 선행연구를 참고하여 다음과 같은 Masked Mean Squared Error loss를 optimize하고자 했다.
식에서 는 실제 유저의 rating, 는 reconstructed, 즉 예측된 rating을 의미한다. 는 mask function으로써 이면 이고, 아니면 이다.
2.2 Dense re-feeding
한 유저가 rating을 매기는 대상은 전체 아이템의 극히 일부에 불과하기 때문에, input 는 매우 sparse하다. autoencoder는 이 sparse한 input을 dense한 output 로 변환한다.
아주 완벽한 가 있는 이상적인 상황을 가정해보자. 그럼 이고 는 아이템 에 대한 모든 유저의 future rating을 정확하게 예측해낸다. 즉 유저가 새로운 아이템 에 대한 점수를 매겨 새로운 벡터 이 만들어졌을 때 이고 이 성립한다. 따라서 이 상황에서 는 를 만족하는 fixed point여야 한다.
이러한 fixed point 제한 조건을 만족시키며 dense training update를 수행하기 위해 모든 optimization iteration마다 다음과 같은 dense re-feeding step을 거쳤다.
(1) 주어진 sparse 벡터 에 대해 dense 와 MMSE loss를 계산한다. (첫 번째 forward pass)
(2) gradient를 계산하고 가중치를 업데이트한다. (첫 번째 backward pass)
(3) 도출된 를 새로운 input으로 보고 를 계산한다. 이때 와 모두 dense하고 MMSE에서 모든 이 0이 아닌 값을 갖는다. (두 번째 forward pass)
(4) gradient를 계산하고 가중치를 업데이트한다. (두 번째 backward pass)
각 iteration마다 (3)과 (4) 단계가 1회 이상 수행된다. 이를 통해 기존에 한 번씩만 이루어지던 forward, backward pass를 여러 번 수행시켜 모델의 성능을 높였다.
3. Conclusion
본 논문에서 제안된 Deep AutoEncoder는 dropout과 SELU등 최신 딥러닝 기술을 이용해 적은 양의 데이터로도 유저의 rating을 잘 예측해냈다. 또한 iterative output re-feeding은 collaborative filtering에서 학습 속도를 높이고 모델의 generalization 성능을 향상시키는데 도움을 주었다.
