
DETR(End-to-End Object Detection with Transformers, ECCV 2020)
Introduction
Object detection task can be understood as a combination of two tasks: bounding box regression and label prediction. Bounding box of the object should be located properly, and each box should be predicted with correct label. Anchor based bounding box selection methods, especially utilizing NMS(Non-maximum suppression) algorithms are somehow heuristic.
Was it bad? No! Notably, DETR shows similar or slightly imperior performance compared to Mask R-CNN. However, there is a huge advantage of end-to-end training, it is still important to suggest a methodology which does not rely on heuristic algorithms or prior knowledge.
Architecture
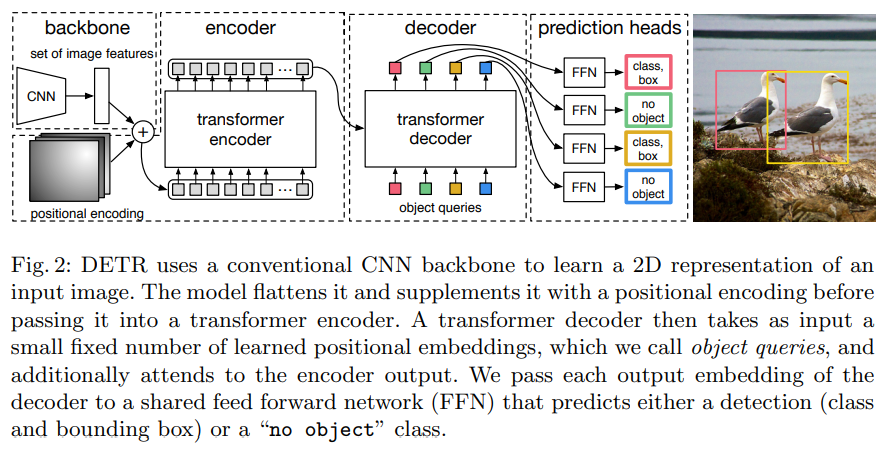
- Features extracted from CNN, flattened, and decorated by positional encoding
- Bbox predictions with transformer encoder-decoder
- Predicted bounding box are regularized by bipartite graph matching with the ground truth
- Bipartite matching loss is suggested, to assign each predicted bounding box into corresponding bounding box in the ground truth.
- Did not utilize any customized block, thus has high scalability: extend to swin transformer, ViT
- Decodes N object in a non-autoregressive manner
Object detection set prediction loss
Loss function
- Bipartite matching loss
- Bipartite matching loss is introduced to optimize ideal matching & similarity of matched objects.
- Search space: all permutated pair of bounding boxes(prediction & GT)
- Bipartite matching loss aims to find permutation s.t.
- : Hungarian algorithm
- is a loss that both reflects class prediction and boundng box similarity
- Where

interested in 🖥️,🧠,🧬,⚛️