
AI HUB 에세이 글 평가 데이터를 활용하여 간단한 score 예측 모델을 만들어 보고자 한다.
에세이 글 데이터에는 초등/중등/고등학생 전학년의 글들이 있으며, 11종의 세부 평가지표에 따른 점수와 관련 메타 데이터가 존재한다.
AI HUB에 공개된 AI 모델 상세 설명에는 모든 데이터를 학습하여 11가지 소분류별 평가지표에 대한 점수를 각각 예측하는 모델 구조를 확인할 수 있다.
이번에는 중학생 대상의 글로 한정하고, 소분류 점수를 모두 합한 총점을 예측하는 모델를 구축했다.
1. 데이터 확인
먼저 데이터가 어떻게 구성되어 있는지 확인해본다.
path ='/1.Training/라벨링데이터/' # 경로 지정
file_str = path + '글짓기/글짓기_중등_1학년_ESSAY_60967.json' # 파일명
with open(file_str) as f: # json파일 열기
text = json.load(f)
text{'paragraph': [{'paragraph_txt': '어렸을 때 백투더퓨처나 스타워즈를 보면서 정말 미래에는 물위를 달리고 하늘을 나는 자동차나 타임머신, 광선검을 쓸 수 있는 세상이 올까라는 상상을 많이 해봤던 기억이 있습니다.#@문장구분# 하지만 저는 그런 날이 오지 않을 것이라고 생각합니다.#@문장구분# 왜냐하면 지금도 막대한 개발과 착취 등으로 현재 지구는 지구온난화라는 현상이 일어나고 있습니다.(중략),
'paragraph_len': 614,
'paragraph_id': '001'}],
'score': {'paragraph_score': [{'paragraph_scoreT': [3, 2.5, 2],
'paragraph_scoreT_detail': {'paragraph_scoreT_exp': [[3, 3, 0],
[3, 2, 0],
[2, 2, 0]]},
'paragraph_scoreT_avg': 2.5,
'paragraph_id': '001'}],
'essay_scoreT': [30, 23.65, 23.05],
'essay_scoreT_avg': 25.566666,
'essay_scoreT_detail': {'essay_scoreT_org': [[3, 3, 3, 3],
[1, 2, 3, 3],
[2, 2, 2, 3]],
'essay_scoreT_cont': [[3, 3, 0, 3], [2, 3, 0, 3], [2, 2, 0, 3]],
'essay_scoreT_exp': [[3, 3, 0], [3, 2, 0], [2, 3, 0]]}},
'student': {'date': '2021.12.05',
'student_educated': True,
'student_grade': '중등_1학년',
'location': '054',
'student_grade_group': '중등',
'student_reading': 1},
'rubric': {'essay_grade': '중등_1학년',
'organization_weight': {'org_paragraph': 1,
'org': 2,
'org_essay': 5,
'org_coherence': 1,
'org_quantity': 1},
'essay_type': '글짓기',
'content_weight': {'con_clearance': 4,
'con_novelty': 4,
'con': 4,
'con_prompt': 0,
'con_description': 2},
'essay_main_subject': '미래 도시에 대한 본인의 생각',
'expression_weight': {'exp_style': 0,
'exp_grammar': 3,
'exp_vocab': 3,
'exp': 4}},
'correction': [],
'info': {'essay_id': 'ESSAY_60967',
'essay_prompt': ' 미래의 도시는 어떤 모습일까요?\n\n 기술의 발전으로 인해 자동차가 하늘을 날아다니고 사람들은 로봇과 자연스럽게 대화하며 지낼까요?\n\n 아니면 더 이상의 환경 파괴를 하지 말자고 결정되어 기계를 줄이고 숲과 동물들과 함께 어울려 살아가게 될까요?\n\n 외계인과 소통하는 세계가 되어있을 수도 있겠네요!\n\n 자신이 생각하는 미래 도시의 이름을 지어주세요. 그리고 미래 도시의 모습을 상상하여 자유롭게 작성해주세요. 그렇게 생각한 이유를 작성해주면 더욱더 좋을 것 같아요.',
'essay_type': '글짓기',
'essay_level': '2',
'essay_len': 475,
'essay_main_subject': '미래 도시에 대한 본인의 생각'}}paragraph_txt 에서 에세이 글을 확인할 수 있고, 여러 라벨링 정보를 확인할 수 있다. 여기서 score에 영향을 미치는 요소가 무엇인지 생각해보면 학년, 에세이 레벨, 에세이 타입 등이 있을 수 있다. 같은 글을 쓰더라도 1학년인지, 3학년인지에 따라 점수가 달라질 수 있을 것이고, 또 에세이 레벨도 점수에 고려되는 부분일 것이다. 그리고 에세이 타입은 총 5가지(글짓기, 대안제시, 설명글, 주장, 찬성반대)로 어떤 타입인가에 따라 점수를 매기는 기준이 다를 것이다.
score는 크게 paragraph_score와 essay_scoreT로 나뉘어져 있다. 총점만 고려할 것이기 때문에 paragraph_scoreT_avg와 essay_scoreT_avg를 가져와 더할것이다.
2. 모델 구조 설계
모델 구조는 다양하게 설계할 수 있다. 가장 좋은 방법은 여러 방법으로 모두 시도 후 가장 성능이 좋은 구조를 선택하는 것이다. 대표적으로 아래와 같은 구조를 고려할 수 있다.
-
text(에세이 글)로만 Bert 학습(fine-tuning)
성능이 잘 나온다면 가장 간단한 방법. 다른 feature(학년, 레벨, 타입 등)들을 고려하지 않아도 됨. -
text에 다른 feature를 포함시켜서 Bert 학습(fine-tuning)
(e.g. "grade: 2 level: 2 type: 글짓기 본문: 저는 미래에...")
BERT만 쓰면 되므로 간단, 그러나 추가된 feature들이 어떻게 영향을 미치는지 알기 어려움 -
BERT를 이용해서 텍스트만으로 일단 점수를 한 번 예측한 다음, 이 예측된 점수와 다른 변수들로 score를 다시 회귀분석으로 예측
모델 구조가 복잡. 텍스트와 feature들이 서로 상호작용하는 경우는 반영 못함.

-
Bert로 추출한 text representaion과 다른 feature들을 결합하여 새로운 regression 모델에 투입하여 score 예측
Bert를 fine-tunning하지 않아도 됨. 텍스트와 feature들이 서로 상호작용하는 효과를 반영할 수 있음.
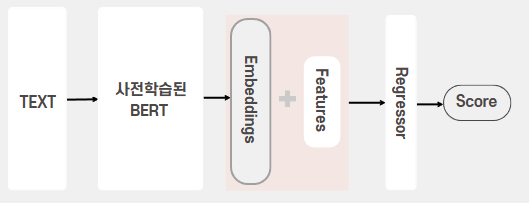
여러 요소들을 고려하여 마지막 4번째 모델 구조로 학습을 진행하기로 하였다.
3. 데이터 준비
훈련데이터 가져오기
text 데이터를 포함한 필요 데이터는 라벨링데이터에 모두 들어있으므로, '라벨링데이터' 폴더를 경로로 데이터를 가져온다. 에세이 아이디, 에세이 글, 학년 정보, 글 종류, 레벨, score data를 가져온다.
from os import listdir
from tqdm import tqdm
path ='./1.Training/라벨링데이터/' # 맞는 경로를 지정해줘야 함
# 라벨링 데이터 가져오는 함수
def get_data(data, path):
ids, grades, etypes, essay, levels, scores =[], [], [], [], [], [] # 빈 리스트 생성
for row in tqdm(data.itertuples(), total=data.shape[0]): # 진행상황 확인을 위한 tqdm, data frame 값을 빠르게 가져오기 위한 itertuples
file_str = path + row.file_name # 파일명
with open(file_str) as f: # json파일 열기
text = json.load(f)
txt = text['paragraph'][0]['paragraph_txt']
paragraph_score = text['score']['paragraph_score'][0]['paragraph_scoreT_avg'] # paragraph score data 가져오기
essay_score = text['score']['essay_scoreT_avg'] # essay score data 가져오기
score = paragraph_score + essay_score # score 더하기
ids.append(text['info']['essay_id']) # essay_id
grades.append(text['rubric']['essay_grade']) # 학년
etypes.append(text['info']['essay_type']) # 글 종류
essay.append(txt)
levels.append(text['info']['essay_level']) # 각 글의 level
scores.append(score) # score data
df= pd.DataFrame({'id': ids, 'grade': grades, 'etype':etypes, 'essay':essay, 'levels': levels, 'scores': scores}) # 리스트로 dataframe 만들기
return df
text_type = ['글짓기','대안제시', '설명글', '주장', '찬성반대'] # 글 5가지 종류
main_df = pd.DataFrame() # 빈 데이터프레임
# 파일 리스트로부터 모든 데이터 가져오기
for i in range(5):
paths = path + text_type[i]+'/' # 경로 지정
fileNameList = listdir(paths) # 해당 경로에 포함된 파일 리스트를 모두 가져옴
df= pd.DataFrame(fileNameList, columns=['file_name']) # 파일 리스트 -> 데이터 프레임화
df=df.astype('string') # df type string 으로 변경
df['file_name'] = df['file_name'].str.normalize('NFC') # colab의 경우 한글 인식을 못하는 경우(한글 자음 모음이 분리되어있음), 자음 모음을 합쳐주는 작업
cr = df['file_name'].str.contains('중등') # 파일명에 '중등'이 포함되어있는 파일만 filtering
data = df[cr]
sub_df = get_data(data, paths) # 데이터 가져오는 함수
main_df = pd.concat([main_df, sub_df]) # main_labels에 누적하여 더하기 위 반복문에서 df['file_name'].str.normalize('NFC') 이 부분은 colab 환경에서만 해당 된다.
가끔 한글 데이터를 colab에서 불러오면 한글 인식을 못하는 경우가 있는데, 여기서는 자음과 모음을 분리해서 인식하고 있다. (데이터로 볼 때는 구분이 안됨) 따라서 colab에서 파일명의 자음과 모음을 합쳐주기 위한 코드이며 local에서 진행할 때는 해당 코드를 제외해줘야 한다.
중학생 대상 글만 추출하기 위해 파일명에 '중등'이 포함되어 있는 파일만 filtering하고 get_data 함수로부터 main_df에 데이터를 넣어준다.
이는 훈련데이터이며 테스트 데이터도 불러와야 한다. 테스트 데이터는 파일 경로만 변경(path ='./2.Validation/라벨링데이터/')하여 위 코드와 동일한 과정으로 가져온다.
시각화
데이터를 파악하기 위해 간단히 시각화를 해보았다.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_theme(style='whitegrid', font_scale=1) # seaborn style 지정
sns.set_palette('Set2', n_colors=10) # seaborn colar pallete 지정
fig, ax = plt.subplots(1,2, figsize=(16,5))
sns.distplot(train['scores'], ax=ax[0]); # score 분포 확인
sns.countplot(train['levels'], ax=ax[1]); # levels 분포 확인 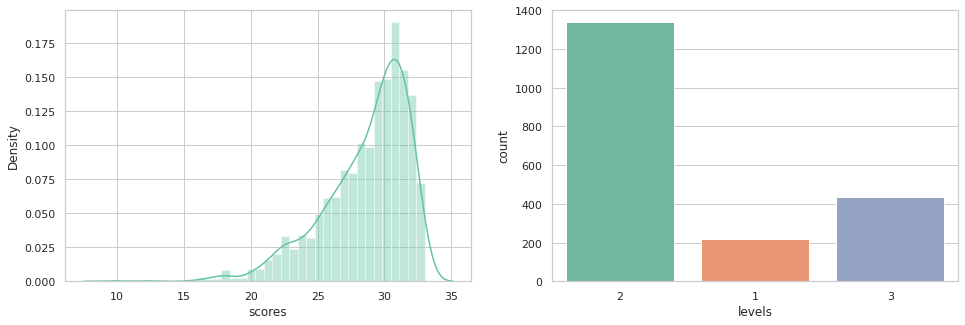
score 분포를 확인해보니 대부분의 점수가 25~33점 사이에 치중되어 있는 것을 알 수 있다.
essay_level은 거의 대부분의 글이 level 2에 치중되어 있는 것을 알 수 있다.
데이터 준비에 이어서 데이터 전처리와 모델링 과정은 다음 글에서 진행하겠다.
.jpg)
안녕하세요 다름이 아니라 ai 글쓰기 채점모델에 대해서 공부하고있는데 비전공자라 잘 이해가 안되서 전체적인 코드가 있을까요..?