
이전 글에 이어서 데이터 전처리와 모델링 과정을 정리하고자 한다.
4. 데이터 전처리
train = train.set_index('id')
test = test.set_index('id')
tr_idx = train.index
te_idx = test.index
temp = pd.concat([train, test])
temp.shape
# >>(17822, 5)json파일로부터 필요한 데이터를 가져와 train, test에 넣어주었다. 데이터 전처리는 train, test 구분 없이 한번에 처리하기 위해 temp로 합쳤다. 나중에 학습할때 다시 분리해야 하므로 train, test 데이터의 index를 따로 저장한다.
temp['grade']= temp['grade'].str.replace('학년|중등_', '')
temp['essay']= temp['essay'].str.replace('#@문장구분#', '')불러온 데이터에서 grade는 '중등1학년' 형식으로 되어있다. 여기서 학년 정보만 추출하기 위해 '학년'과 '중등'은 제외한다. essay 글에서는 문장 사이에 불필요한 '#@문장구분#'이 들어있어 이 부분도 제외처리 한다.
temp = pd.get_dummies(temp, columns=['etype']) #원-핫 인코딩
col = {'etype_글짓기': '글짓기',
'etype_대안제시': '대안제시',
'etype_설명글': '설명글',
'etype_주장': '주장',
'etype_찬성반대': '찬성반대'}
temp.rename(columns=col, inplace=True)
temp.head()총 5가지 글 유형으로 구성되어있는 etype을 one-hot encoding 처리해준다. get_dummies를 통해 자동 생성된 columns name을 보기 편하게 변경해주었다. 이렇게 처리된 temp 데이터프레임은 아래와 같은 형태가 되었다.

5. 임베딩
!pip install transformers
import tensorflow as tf
from transformers import AutoTokenizer, TFBertModel
# 토크나이저
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
# 모델
model = TFBertModel.from_pretrained("klue/bert-base", from_pt=True)사전학습된 Bert 모델로 글의 representation을 얻기 위해 토크나이저와 모델을 불러오고 정의해준다. 사용하고자 하는 모델은 KLUE(Korean Language Understanding Evaluation)로 사전학습된 Bert 모델이다. KLUE는 국내 기관 및 기업에서 한국어의 적은 데이터 셋 및 적절한 한국어 모델 평가지표가 없는 한계를 극복하고자 시작된 오픈 프로젝트로, Baseline 모델인 KLUE-BERT, KLUE-RoBERTa 모델이 HuggingFace Model Hub에 배포되어 있는 상태이다.
Bert는 목적에 따라 활용할 수 있는 모델이 다양하다. 대표적으로, BertForSentenceClassificaton(문장 분류를 위해 학습된 모델), BertForQuestionAnswering(질문 답변을 위해 학습된 모델) 등이 있다. 여기서 사용한 BertModel은 특정 목적을 위한 layer가 포함되어있지 않기 때문에 raw hidden-states까지만 출력하는 headless 모델이다.
TFBertModel은 Tensorflow 기반으로, BertModel은 Pytorch 기반으로 구축된 점이 다르고 아키텍처는 동일하다. BertModel은 pytorch 기반으로 먼저 사전학습이 되었기 때문에 TFBertModel에서 사전훈련된 가중치를 가져올 때 from_pt=True를 통해 불러와 tensorflow 형식으로 변환해준다.
def gen_emb(data):
for row in tqdm(temp.itertuples()):
inputs = tokenizer(row.essay, return_tensors='tf', truncation=True)
outputs = model(inputs)
cls_embeddings = outputs.last_hidden_state[:,0]
yield cls_embeddings
cls_emb = list(gen_emb(temp))
cls_emb_df = pd.DataFrame(np.squeeze(np.array(cls_emb), axis=1))위 코드는 모든 에세이 데이터에 대한 표현 벡터(임베딩)을 가져오는 과정이다.
모든 글의 임베딩을 얻기 위해 tokenizer를 통해 토큰화 하여 BertModel에 입력한다. tokenizer에서 파라미터 truncation=True는 문장의 토큰화 결과가 모델이 허용할 수 있는 토큰 기준 최대 길이(512)보다 길 경우 문장을 자른다는 의미이다. 확인해보니 최대 토큰 길이보다 더 긴 데이터는 전체 데이터중 약 1%정도 차지하고 있어 잘라도 무방할 것이라 판단하였다.
모델 출력 결과에서 last_hidden_state[:,0]을 가져온다. 이 부분을 cls embedding이라고도 하는데 모델 구조로 보면 다음과 같다.
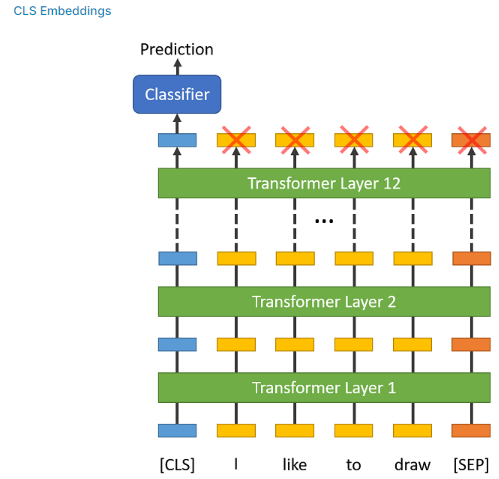
[CLS] 토큰은 문장의 시작 부분에, [SEP] 토큰은 문장의 끝에 추가된다. BERT는 문맥을 이해하기 위해 문장의 각 단어(토큰)을 다른 모든 단어와 연결시켜 이해하는 계산 과정을 거친다.(따라서 BERT를 문맥 기반 모델이라고 한다.) 이 과정에서 [CLS] 토큰은 다른 모든 토큰의 집계 표현을 보유하고 있으므로 문장 전체에 대한 표현을 담고 있다. 위 그림에서는 [CLS] 토큰이 실제 문장을 구성하는 모든 토큰(I, like, to, draw)을 고려한 임베딩을 담고 있다. 따라서, 문장 분류와 같은 다운스트림 과제나 특징을 추출할 때 cls embedding을 활용한다.
last_hidden_state는 최종 인코더 계층에서만 얻은 모든 토큰의 표현을 뜻한다. 이 중에서 last_hidden_state[:,0]는 가장 첫 번째 토큰인 [CLS] 의 표현 벡터를 뜻하므로 이것을 가져온 것이다.
BERT의 경우 임베딩의 크기는 768이므로 모든 에세이 글은 768 길이의 일정한 표현 벡터로 변환된다.
이 부분은 시간이 꽤 걸린다. Colab Pro 기준으로 약 45분정도 소요되었다.
cls_emb_df.head()를 출력해보면 다음과 같이 768길이의 임베딩 값이 저정되어있는 것을 확인할 수 있다.

6. 학습용 데이터셋 구축
이제 이 임베딩 값과 앞전에 가져온 grade, levels, type 등의 데이터와 합쳐서 최종 학습 데이터셋을 구축할 단계이다. 그러나 feature의 개수가 이미 700개가 넘어가게 되는데, feature 수가 너무 많으면 오히려 학습에 방해가 될 수 있다. 그러므로 차원 축소를 통해 임베딩의 주요 정보로 축약하도록 했다.
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=200) # 200은 임의로 선정한 값
emb_svd = svd.fit_transform(cls_emb_df)
df_emb = pd.DataFrame(emb_svd)
df = pd.concat([temp, df_emb], axis=1)
df.drop(columns=['essay'], inplace=True) # text data는 임베딩 값으로 대체되므로 삭제
df.head()
데이터를 확이해보면 위와 같이 id별로 grade, levels, types(글짓기, 대안제시 등), score 정보와 200크기로 축약된 임베딩 데이터가 합쳐진 것을 볼 수 있다.
7. Regressor 모델 구축, 튜닝
Regressor는 lightgbm으로 먼저 시도해보았다. hyper parameter tunning 기법으로 optuna를 활용하였다.
!pip install optuna
# Optuna Libraries
import optuna
from optuna import Trial
from optuna.samplers import TPESampler
# LGBM Regressor
from lightgbm import LGBMRegressor
# train_test_split
from sklearn.model_selection import train_test_split
# Evaluation Score
from sklearn.metrics import mean_squared_error
df.set_index('id', inplace=True)
df_x = df.loc[tr_idx]
y = round(df_x['scores'], 2)
X = df_x.drop(columns=['scores'])
X['grade']=X['grade'].astype('int')
X['levels']=X['levels'].astype('int')
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# random sampler
sampler = TPESampler(seed=10)
# define function
def objective(trial):
lgbm_param = {
'objective': 'regression',
'verbose': -1,
'metric': 'mse',
'num_leaves': trial.suggest_int('num_leaves', 2, 1024, step=1, log=True),
'colsample_bytree': trial.suggest_uniform('colsample_bytree', 0.7, 1.0),
'reg_alpha': trial.suggest_uniform('reg_alpha', 0.0, 1.0),
'reg_lambda': trial.suggest_uniform('reg_lambda', 0.0, 10.0),
'max_depth': trial.suggest_int('max_depth',3, 15),
'learning_rate': trial.suggest_loguniform("learning_rate", 1e-8, 1e-2),
'n_estimators': trial.suggest_int('n_estimators', 100, 3000),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'subsample': trial.suggest_loguniform('subsample', 0.4, 1),
}
# Generate model
model_lgbm = LGBMRegressor(**lgbm_param)
model_lgbm = model_lgbm.fit(X_train, y_train, eval_set=[(X_val, y_val)],
verbose=0, early_stopping_rounds=25)
# 평기 지표
MSE = mean_squared_error(y_val, model_lgbm.predict(X_val))
return MSE
optuna_lgbm = optuna.create_study(direction='minimize', sampler=sampler)
# n_trials의 경우 optuna를 몇번 실행하여 hyper parameter를 찾을 것인지를 정한다.
optuna_lgbm.optimize(objective, n_trials=50)
lgbm_trial = optuna_lgbm.best_trial
lgbm_trial_params = lgbm_trial.params
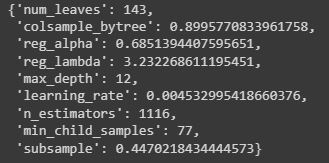
lgbm_trial_params하이퍼 파라미터 튜닝 결과 최적 파라미터 조건은 아래와 같은 결과가 나왔다.
8. 모델 학습 및 평가
# Modeling fit
lgbm = LGBMRegressor(**lgbm_trial_params)
lgbm_study = lgbm.fit(X_train, y_train)
test_ = df.loc[te_idx]
y_test = round(test_['scores'], 2)
X_test = test_.drop(columns=['scores'])
X_test['grade']=X_test['grade'].astype('int')
X_test['levels']=X_test['levels'].astype('int')
pred = lgbm_study.predict(X_test)
predict_df = pd.DataFrame({'pred':pred, 'target': y_test})
predict_df['error']=abs(predict_df['target']-predict_df['pred'])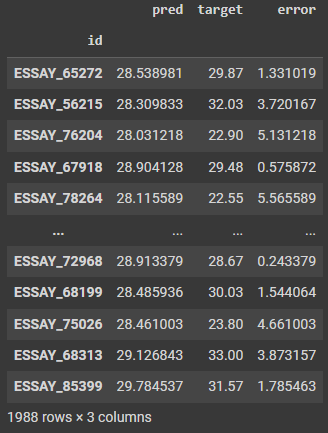
전반적인 모델의 예측 결과를 확인해보기 위해 예측값, 실제 score와 이 둘 간의 차이를 계산한 결과이다.
from sklearn.metrics import mean_squared_error
mean_squared_error(predict_df['target'], predict_df['pred'])MSE 결과는 약 8.96으로 확인되었다. 실제로 약 3점 정도의 점수 오차가 있다고 할 수 있다.
sns.lineplot(data=predict_df, x=range(len(predict_df)), y='error');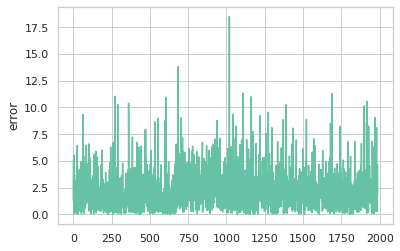
에세이 score 실제값과 예측값의 차이를 시각화한 결과이다. 전반적으로 오차는 ±5점 이내로 분포되어 있으며 큰 경우는 ±5~10사이가 대부분이다. 가장 차이가 큰 오차로 약 18점 정도로 튀는 값이 존재한다.
지금까지 적용한 구조는 시도할 수 있는 다양한 방법 중 하나일 뿐이다. 여러 방식으로 시도해보고 가장 성능이 좋은 구조를 선택하는 것이 가장 좋다.
.jpg)
안녕하세요 ai hub에서 에세이 글 평가 데이터를 이용해보고 있는 학생입니다.
혹시 cls_emb을 list로 받았는데 이후에 cls_emb_df가 되는 dataframe 과정이 어떻게 되는지 이해가 안가서 설명가능할까요? 혼자 공부하려니 너무어려워서요..