The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset
논문
Abstract
이미지를 잘 분류할 수 있는 Robust한 CNN 모델을 만들기 위해서 많은 hyper-pameter에 대한 tuning이 필요하다. 그 중에서 가장 중요한 것 중 하나는 batch size로, 이는 모델이 forward와 backward를 통해 한번 학습하는 이미지의 수를 말한다. 이 논문에서는 batch size와 learning rate가 모델의 성능에 끼치는 영향을 연구하였다. 실험을 해본 결과, 일반적으로 batch size가 크다고 해서 높은 정확도를 보이는 것은 아니라는 것을 알 수 있었다. 또한, learing rate와 batch size를 낮추면 fine-tuning 단계에서 모델이 더 잘 학습될 수 있는 것을 발견했다.
Introduction
Batch size는 모델이 gradient estimation process를 통해 한번 학습할 때 사용하는 이미지의 수를 말한다. Batch size가 작으면 빠르게 수렴하지만 optimum minima에 도달하지 못할 수 있다. 또한, batch size가 큰 variance 값으로 인해 regularization 효과가 있지만 minima를 지나칠 수 있어 상대적으로 작은 learning rate를 필요로 한다. 반면, batch size가 클 경우 안정적으로 학습이 가능하지만 수렴하는데 오래 걸린다.
내가 알고있는 batch size와 논문에 적혀있는 batch size의 의미가 다르다?
batch size, which is the number of images used in every epoch to train the network..
논문에서는 위와 같이 batch size에 대해 설명한다. Epoch마다 사용하는 sample의 수에 따라서 3가지의 방법으로 gradient descent 방법을 나눌 수 있다. 아래와 같의 정의했을 때, 내가 생각한 일반적인 batch size를 mini-batch라고 생각하면 이해하기 쉬울 것 같다.
- Batch gradient descent
한 번의 epoch에 모든 데이터를 활용하여 학습한다.- Stochastic gradient descent
한 번의 epoch에 데이터에서 임의의 하나의 sample만을 활용하여 학습하는 것을 말한다.- Mini-batch gradient descent
사전에 정의된 개수만큼 데이터를 활용하여 한번의 epoch에 학습한다.
Batch size가 크면 수렴하는데 오래 걸리고, 작으면 loss가 튀는 이유?
Batch gradient descent 와 stochastic gradient descent만 살펴보자. Batch 단위로 학습을 할 경우, 전체 데이터에 대한 평균 loss를 활용하여 학습하기 때문에, 학습이 안정적이지만 학습을 하는데 오래 걸린다. 반면, random하게 데이터 중 하나의 sample을 선택하는 stochastic gradient descent의 경우에는 한 번의 step에 하나의 data만 바라보기 때문에 학습이 빠르지만 불안정하여 minima를 찾지 못하고 발산할 수 있다.
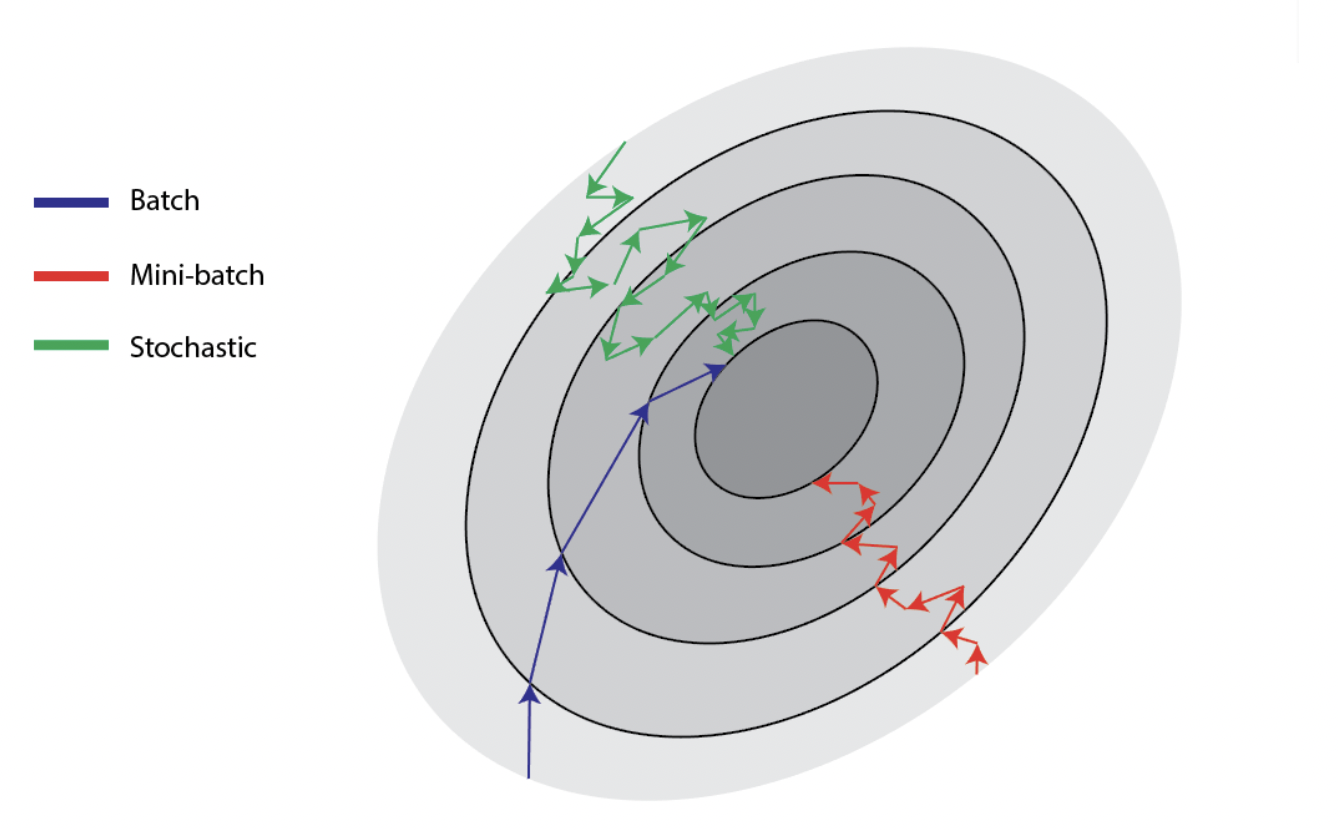
Methodology
CNN 모델이 이미지를 분류하기 위해 학습하는 것을 SGD(stochastic gradient descent)나 Adam optimizer를 사용하여 loss function 를 최소화하는 과정으로 정의할 수 있다.
SGD optimizer
SGD optimizer을 사용하여 모델의 가중치는 아래와 같은 식에 따라 갱신된다.
여기서 는 learning rate, 는 학습에 사용된 sample images, 는 image의 labels, 는 학습할 가중치를 의미한다.
Adam optimizer
Adam optimizer는 아래와 같은 식에 따라 모델의 가중치를 갱신한다.
여기서 은 이전의 update 정보를 얼마나 사용할지를 나타낸다. 는 gradients running average의 momentum, 는 squared gradients running average의 momentum을 나타낸다.
Adam optimizer를 어떻게 해석할 수 있을까?
안정적으로 학습하기 위하여 이전 step의 gradient와 adaptive learning rate 을 사용한다고 생각하자.
수식을 살펴보면 알 수 있듯이 learning rate와 batch size는 서로에게 영향을 끼치고, 모델 성능을 좌우한다.
Experiment & Results
사전 학습된 VGG16 모델과 PatchCamelyon dataset을 활용하여 실험을 진행하였다. Test는 kaggle에 존재하는 이미지를 사용하였다. 모든 이미지는 pixels 이다. Image augmentation은 이미지의 수를 늘리는 효과가 있고, model을 robust하게 한다. 따라서, 이 논문에서는 image를 수직, 수평으로 flip, 180도 회전, 확대, shift 등의 기법들을 사용하여 augmentation 하였다.
모델의 성능을 평가하기 위해 ROC curve (AUC)를 사용하였다.
여기서 TP와 TN은 각각 positive, negative 인 값을 잘 분류한 것을 의미한다. FP는 negative를 positive로 잘못 분류한 것을, FN은 positive를 negative로 잘못 분류한 것을 의미한다. AUC의 최소값은 0.5로 전혀 예측을 하지 못하는 것을 의미하고, 최댓값은 1이다.
VGG16의 마지막 두 block을 80% 데이터로 finetuning 하였고, 20%의 데이터로 validate 하였다. 실험에서 batch size는 [16, 32, 64, 128, 256]으로 사용하였고, optimizer은 SGD와 Adam을 사용했다. 학습의 일관성을 위해 epoch는 50으로 고정하였고, 가장 validation accuracy가 높은 모델을 test에 사용했다.
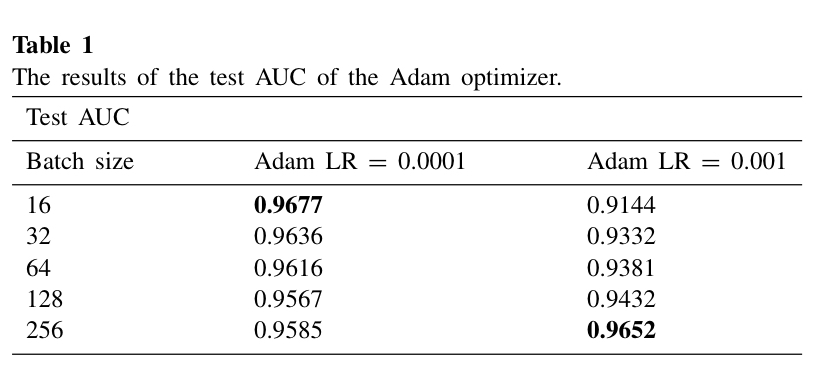
Adam optimizer를 사용했을 때 결과는 Table1과 같다. Batch size가 16이고 learning rate이 1e-4일 때 Test AUC가 가장 높았다. Learning rate이 1e-3일 때는 batch size가 256일 때 성능이 가장 높은 반면, batch size가 작을 때는 성능이 좋지 않았다.
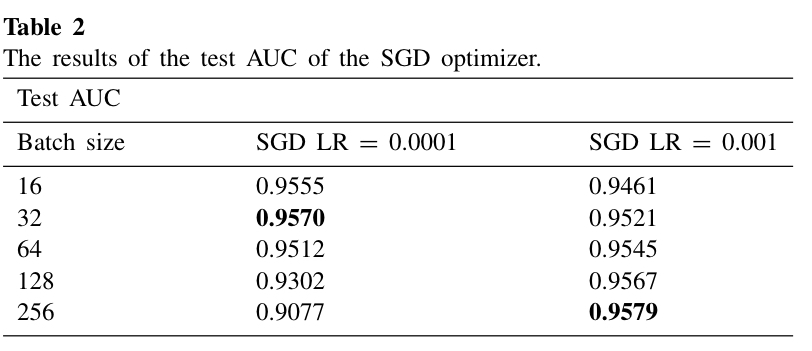
SGD optimizer을 사용할 때도 Adam과 마찬가지로 learning rate가 크면 batch size가 클 때 성능이 좋았고, learning rate이 작으면 batch size가 작을 때 높은 경향을 보였다.
Conclusion
이 논문은 실험을 통해 learning rate이 크다면 batch size가 클 때, learning rate이 작다면 batch size가 작은 것이 성능이 좋다는 것을 보였다. 또한, learning rate과 batch size를 작게 설정하여 fine-tuning 하는 것을 추천하였다. 추가적으로 GPU의 process를 고려하여 batch size는 2의 제곱으로 설정하고, batch size의 초기값을 32나 64로 설정하여 실험하는 것을 추천했다.
